|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Малахов С.В., Якупов Д.О.
Исследование стохастических моделей генерации пакетов в компьютерных сетях
// Программные системы и вычислительные методы.
2024. № 2.
С. 53-72.
DOI: 10.7256/2454-0714.2024.2.70340 EDN: EKXYBU URL: https://nbpublish.com/library_read_article.php?id=70340
Исследование стохастических моделей генерации пакетов в компьютерных сетях
Малахов Сергей Валерьевич
ORCID: 0009-0001-8666-6713
кандидат технических наук
доцент; кафедра управления в технических системах; Поволжский государственный университет телекоммуникаций и информатики
443090, Россия, Самарская область, г. Самара, Московское шоссе, 77
Malakhov Sergei Valer'evich
PhD in Technical Science
Assistant, Associate professor, Povolzhskiy State University of Telecommunications and Informatics
443090, Russia, Samara region, Samara, Moskovskoe shosse, 77

|
s.malakhov@psuti.ru
|
|
 |
|
Якупов Денис Олегович
ORCID: 0009-0003-2371-0822
ассистент; кафедра программной инженерии; Поволжский государственный университет телекоммуникаций и информатики
443090, Россия, Самарская область, г. Самара, Московское шоссе, 77
Yakupov Denis Olegovich
Assistant, Povolzhskiy State University of Telecommunications and Informatics
443090, Russia, Samara region, Samara, Moskovskoe shosse, 77
|
|
d.yakupov@psuti.ru
|
|
|
|
DOI: 10.7256/2454-0714.2024.2.70340
EDN: EKXYBU
Дата направления статьи в редакцию:
02-04-2024
Дата публикации:
02-06-2024
Аннотация:
Стохастические модели генерации пакетов – это модели, которые используются для генерации трафика в компьютерных сетях с определенными характеристиками. Эти модели могут быть использованы для симуляции сетевой активности и тестирования производительности сети. Стандартная передача данных в сети – это генерация пакетов с задержками, при котором пакеты отправляются через определенные промежутки времени. Для генерации пакетов с задержками могут использоваться различные стохастические модели, включая равномерное распределение, экспоненциальное распределение, распределение Эрланга. В данной работе была собрана экспериментальная установка и разработано клиент-серверное приложение для проведения исследования и анализа производительности канала передачи данных. Был предложен алгоритм, позволяющий восстанавливать моментные характеристики случайной величины интервала между пакетами для дальнейшего использования моделей массового обслуживания. Выполнен анализ законов распределения на производительность экспериментального образца сети и получены оценки эффективности использования канала и среднего времени генерации пакетов в сегментах сети, а также гистограммы задержек по законам распределения. Была создана экспериментальная установка, разработано клиент-серверное приложение для анализа производительности канала передачи данных. Предложен алгоритм восстановления моментных характеристик временных интервалов между пакетами. Проведен анализ законов распределения на производительность сети, получены оценки эффективности использования канала и среднего времени генерации пакетов в сегментах сети, также гистограммы задержек по законам распределения. Генерация пакетов с задержками по стохастическим законам распределения (равномерное, экспоненциальное, Эрланга) имеет большое значение при моделировании и анализе работы сетевых систем. Также генерация пакетов с задержками по вышеупомянутым законам распределения позволяет проводить тестирование и отладку сетевых приложений и устройств в условиях, близких к реальным. Это позволяет выявлять возможные проблемы и улучшать работу сетевых систем. В результате эксперимента был предложен алгоритм, позволяющий восстанавливать моментные характеристики случайной величины интервала между пакетами для дальнейшего использования моделей массового обслуживания. Также, выполнен анализ влияния законов распределения на производительность экспериментального образца сети и получены оценки эффективности использования канала и среднего времени генерации пакетов в сегментах сети, а также гистограммы задержек по законам распределения.
Ключевые слова:
равномерное распределение, экспоненциальное распределение, распределение Эрланга, пакетная коммутация, задержки, клиент-серверное приложение, анализ трафика, передача данных, генерации пакетов, Стохастические модели
Abstract: Stochastic packet generation models are models that are used to generate traffic in computer networks with certain characteristics. These models can be used to simulate network activity and test network performance. Standard data transmission on the network is packet generation with delays, in which packets are sent at certain intervals. Various stochastic models can be used to generate delayed packets, including uniform distribution, exponential distribution, and Erlang distribution. In this work, an experimental setup was assembled and a client-server application was developed to conduct research and analyze the performance of the data transmission channel. An algorithm has been proposed that allows to restore the moment characteristics of a random value of the interval between packets for further use of queuing models. The analysis of the distribution laws on the performance of the experimental network sample was performed and estimates of the efficiency of channel use and the average packet generation time in network segments, as well as histograms of delays according to the distribution laws, were obtained. An experimental setup was created, and a client-server application was developed to analyze the performance of the data transmission channel. An algorithm for restoring the moment characteristics of the time intervals between packets is proposed. The analysis of the distribution laws on network performance was carried out, estimates of the efficiency of channel use and the average packet generation time in network segments were obtained, as well as histograms of delays according to the distribution laws. The generation of packets with delays according to stochastic distribution laws (uniform, exponential, Erlang) is of great importance in modeling and analyzing the operation of network systems. Also, the generation of packets with delays according to the above-mentioned distribution laws allows testing and debugging of network applications and devices in conditions close to real ones. This allows to identify possible problems and improve the operation of network systems. As a result of the experiment, an algorithm was proposed that allows to restore the moment characteristics of a random value of the interval between packets for further use of queuing models. Also, the analysis of the influence of distribution laws on the performance of the experimental network sample was performed and estimates of the efficiency of channel use and the average packet generation time in network segments, as well as histograms of delays according to distribution laws, were obtained.
Keywords: uniform distribution, exponential distribution, Erlang distribution, packet switching, delays, client-server application, traffic analysis, data transmission, generating packages, Stochastic models
Введение
Генерация пакетов – это процесс создания и отправки пакетов данных через сеть. Это важная функция, которая используется в современных компьютерных сетях для передачи информации между устройствами. Генерация пакетов осуществляется программным обеспечением, которое позволяет создавать и отправлять пакеты данных с заданными параметрами.
Генерация пакетов в компьютерных сетях позволяет решать следующие задачи:
- · тестирование сети: генерация пакетов может помочь проверить работоспособность сети и выявить проблемы, такие как низкая пропускная способность и задержки;
- · тестирование безопасности: генерация пакетов может помочь проверить защиту сети от вредоносных программ, хакерских атак и несанкционированного доступа к данным;
- · тестирование производительности: генерация пакетов может помочь оценить производительность сети и определить ее пропускную способность;
- · тестирование новых приложений: генерация пакетов может помочь проверить работу новых приложений в сети и выявить возможные проблемы;
- · тестирование настройки сети: генерация пакетов может помочь проверить правильность настройки сети и выявить возможные ошибки в конфигурации.
Назначение генерации пакетов состоит в том, чтобы обеспечить эффективную передачу данных в сети. Это достигается путем разбиения больших объемов данных на меньшие блоки, которые могут быть переданы через сеть более быстро и надежно. Кроме того, генерация пакетов позволяет управлять потоком данных и контролировать качество обслуживания в сети.
Преимущества генерации пакетов включают высокую скорость передачи данных, эффективное использование сетевых ресурсов и возможность обеспечения надежности и безопасности передачи данных. Генерация пакетов также позволяет оптимизировать сетевую инфраструктуру и улучшить производительность сетевых приложений.
Начальный момент и эксцесс – это две основные характеристики, которые могут использоваться для описания распределения трафика в сети [1].
Начальный момент – это числовая характеристика, которая описывает распределение данных относительно их среднего значения. Начальный момент первого порядка равен нулю, а начальный момент второго порядка равен дисперсии случайной величины.
В контексте сетевого трафика начальный момент может использоваться для описания распределения объема или длительности пакетов в трафике. Например, начальный момент второго порядка может использоваться для определения дисперсии размеров пакетов в трафике.
Эксцесс – это числовая характеристика, которая описывает форму распределения данных. Эксцесс может быть положительным, отрицательным или равным нулю. Положительный эксцесс означает, что распределение имеет более тяжелые хвосты и более высокий пик, чем нормальное распределение. Отрицательный эксцесс означает, что распределение имеет более легкие хвосты и более низкий пик, чем нормальное распределение. Эксцесс равный нулю означает, что распределение имеет форму нормального распределения.
В контексте сетевого трафика эксцесс может использоваться для описания формы распределения размеров пакетов в трафике. Например, положительный эксцесс может указывать на наличие тяжелых хвостов в распределении размеров пакетов, что может означать наличие крупных пакетов или необычных событий в трафике. Отрицательный эксцесс может указывать на наличие легких хвостов в распределении размеров пакетов, что может означать отсутствие крупных пакетов и однородность трафика.
Кроме того, начальный момент и эксцесс могут быть использованы для сравнения различных типов трафика или различных сетевых устройств. Например, анализ начального момента и эксцесса может помочь в сравнении трафика, проходящего через различные маршрутизаторы или переключатели. Это может помочь выявить проблемы с производительностью сетевых устройств или определить оптимальную конфигурацию сети.
Постановка проблемы
В современном мире компьютерные сети играют ключевую роль в передаче и обработке информации. Одной из важных задач при проектировании и оптимизации таких сетей является моделирование трафика, в частности, генерации пакетов данных. Стохастические модели генерации пакетов являются одними из наиболее часто используемых подходов для решения этой задачи.
Однако, существующие модели не всегда адекватно отражают реальные условия передачи данных в компьютерных сетях, что приводит к неточностям при прогнозировании и оптимизации параметров сети.
Целью данной работы является исследование стохастических моделей генерации пакетов в компьютерных сетях, основанных на равномерном, экспоненциальном и распределении Эрланга. Будут проведены теоретический и экспериментальный анализ этих моделей, а также сравнение их точности и эффективности при моделировании реального трафика.
Равномерное распределение – это распределение вероятности, при котором все значения в заданном диапазоне имеют одинаковую вероятность появления. Другими словами, каждое значение в этом диапазоне имеет одинаковую вероятность быть выбранным.
Например, если генерируется случайное число от 1 до 6 с равномерным распределением, то каждое число от 1 до 6 будет иметь вероятность 1/6 быть выбранным.
Равномерное распределение широко используется в различных областях, включая статистику, физику, экономику, инженерию, компьютерные науки и многие другие. Оно является одним из простейших и наиболее понятных видов распределения вероятности, и поэтому часто используется в качестве модели случайного процесса.
Равномерное распределение может быть дискретным или непрерывным. В случае непрерывного равномерного распределения все значения в определенном интервале равновероятны и распределение задается формулой f(x) = 1/(b-a), где a и b – концы интервала, а f(x) – плотность вероятности в точке x.
Равномерное распределение также может использоваться для создания псевдослучайных чисел, которые используются в компьютерных приложениях для генерации случайных последовательностей.
Равномерное распределение имеет несколько свойств, которые могут быть полезны при его анализе или использовании в моделировании. Некоторые из этих свойств включают:
- · математическое ожидание равномерного распределения равно среднему значению всех возможных значений в заданном диапазоне. Для непрерывного равномерного распределения это будет равно (a+b)/2, где a и b – концы интервала;
- · дисперсия равномерного распределения определяется формулой (b-a)^2/12 для непрерывного равномерного распределения;
- · гистограмма равномерного распределения будет иметь прямоугольную форму, если диапазон значений равномерно разделен на несколько интервалов.
Равномерное распределение также может быть использовано для решения различных задач, таких как определение вероятности того, что случайная величина попадет в определенный диапазон значений, или для нахождения оптимальных значений в задачах оптимизации.
Для генерации пакетов с использованием равномерного распределения необходимо выполнить следующие шаги:
- Определить интервал, в котором будет генерироваться равномерно распределенное время между последовательными пакетами.
- Используя генератор случайных чисел, сгенерировать случайные значения с равномерным распределением в заданном интервале. Эти случайные значения будут представлять время между последовательными пакетами, отправляемыми в сеть.
- Повторять шаг 2, чтобы сгенерировать необходимое количество пакетов.
- Важно учитывать, что время между отправкой пакетов должно быть больше, чем время передачи пакета, чтобы избежать коллизий и утечек пакетов в сети.
Экспоненциальное распределение – это статистическое распределение вероятностей, которое описывает время между двумя последовательными событиями в процессе Пуассона.
Например, время между получением двух пакетов данных в компьютерных сетях может быть описано экспоненциальным распределением.
Основные свойства экспоненциального распределения:
- · оно имеет единственный параметр, который называется параметром масштаба (обычно обозначается как λ);
- · функция плотности вероятности экспоненциального распределения имеет форму f(x) = λ * exp(-λx), где x – время между двумя событиями. Эта функция показывает вероятность того, что время между двумя событиями не превысит заданное значение x.;
- · экспоненциальное распределение является распределением без памяти, то есть вероятность наступления события не зависит от того, сколько времени прошло с момента предыдущего события;
- · среднее время между двумя событиями в экспоненциальном распределении, т.е. математическое ожидание равно 1/λ, а дисперсия равна 1/λ^2;
Экспоненциальное распределение обладает свойством отсутствия памяти. Это означает, что вероятность наступления события в любой момент времени не зависит от того, сколько времени прошло с момента предыдущего события. Например, если среднее время между двумя звонками в call-центре равно 5 минутам, то вероятность того, что следующий звонок произойдет в течение следующей минуты, равна 1/5, независимо от того, сколько времени прошло с момента предыдущего звонка.
Стоит отметить, что экспоненциальное распределение является одним из основных распределений, используемых в статистическом анализе данных, и его свойства могут быть использованы для оценки параметров других распределений и для проверки статистических гипотез.
Для генерации пакетов с использованием экспоненциального распределения необходимо выполнить следующие шаги:
- Определить параметр λ экспоненциального распределения, который описывает среднее время между двумя последовательными событиями.
- Используя генератор случайных чисел [2], сгенерировать случайные значения с экспоненциальным распределением с параметром λ. Эти случайные значения будут представлять время между последовательными пакетами, отправляемыми в сеть.
- Повторять шаг 2, чтобы сгенерировать необходимое количество пакетов.
- Важно учитывать, что время между отправкой пакетов должно быть больше, чем время передачи пакета, чтобы избежать коллизий и утечек пакетов в сети.
Распределение Эрланга – это математическая модель, используемая для описания времени между двумя последовательными событиями в процессе Пуассона [3].
Процесс Пуассона – это стохастический процесс, в котором случайные события происходят независимо друг от друга с постоянной интенсивностью.
Распределение Эрланга определяет вероятность того, что количество событий, произошедших в фиксированном временном интервале, будет равно заданному значению. Данное распределение может быть использовано для моделирования времени между вызовами в центре обработки вызовов, времени между прибытием клиентов в магазине или времени между двумя последовательными срабатываниями определенного события в производственном процессе.
В общем случае распределение Эрланга может быть представлено как сумма k независимых случайных величин, каждая из которых имеет экспоненциальное распределение с параметром λ.
Распределение Эрланга является особой формой гамма-распределения.
Параметр k в распределении Эрланга называется формой распределения, а параметр λ – интенсивностью.
Математическое ожидание распределения Эрланга равно k/λ, а дисперсия равна k/λ2.
Существует несколько методов для вычисления вероятностей для распределения Эрланга, включая использование таблиц и специальных программных пакетов.
Если процесс Пуассона является неоднородным, то можно использовать распределение Эрланга с переменной интенсивностью. В этом случае параметр λ будет зависеть от времени.
Если количество событий, которые могут произойти в фиксированном временном интервале, не ограничено, то вместо распределения Эрланга может быть использовано распределение Вейбулла или распределение Парето.
Для генерации пакетов с использованием распределения Эрланга необходимо выполнить следующие шаги:
- Определить форму и интенсивность распределения Эрланга, то есть параметры k и λ.
- Сгенерировать k независимых случайных величин с экспоненциальным распределением, используя генератор случайных чисел.
- Сложить сгенерированные значения, чтобы получить время между k событиями в процессе Пуассона с интенсивностью λ.
- Это время будет являться временем между отправкой последовательных пакетов в сеть.
- Повторять шаги 2-4, чтобы сгенерировать необходимое количество пакетов.
- Важно учитывать, что время между отправкой пакетов должно быть больше, чем время передачи пакета, чтобы избежать коллизий и утечек пакетов в сети.
Методология и условия исследования
Была собрана экспериментальная установка, состоящая из клиента и сервера, на котором было установлено программное обеспечение для анализа входящего трафика Wireshark [4] (рис. 1)
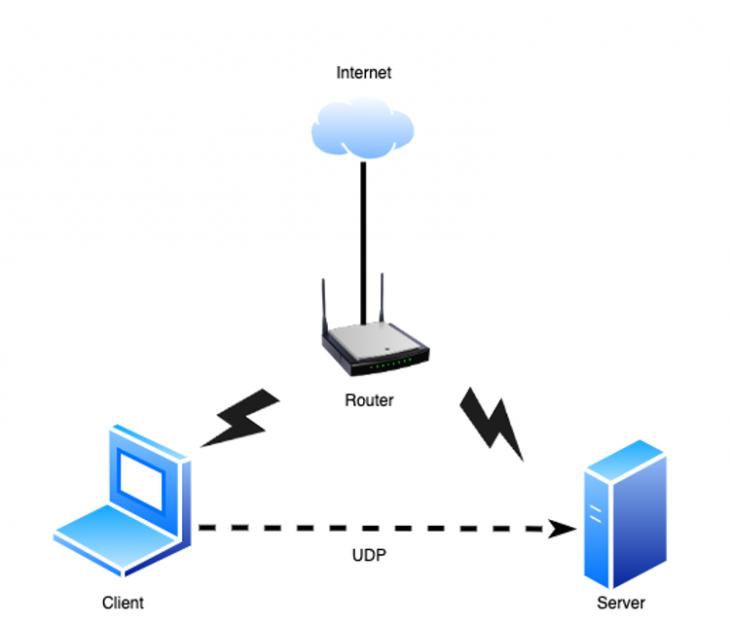
Рис. 1 – Экспериментальная установка
Экспериментальная установка состоит из:
- · клиента – Lenovo Ideapad 3;
- · сервера – HP Pavilion G6;
- · маршрутизатора - ASUS RT-AX53U;
- · пропускная способность канала 100 Мбит/с.
Разработанное клиент-серверное приложение написано на языке программирования Java. Объем программы: 774 Кбайт. Установка не требуется [5].
Версия операционной системы для клиентского и серверного приложений: MS Windows 7 – 11, Mac OS X, Linux
Для запуска приложения на клиенте и на сервере требуется установленная на любой операционной системе (Windows 7 – 11, Mac OS X, Linux) реализация спецификации платформы Java, включающая в себя компилятор и библиотеки классов (Jdk-17).
Клиент генерирует пакеты данных на сервер (рис. 2). Сервер получает пакеты (рис. 3) и анализирует получаемый трафик с помощью программы Wireshark.
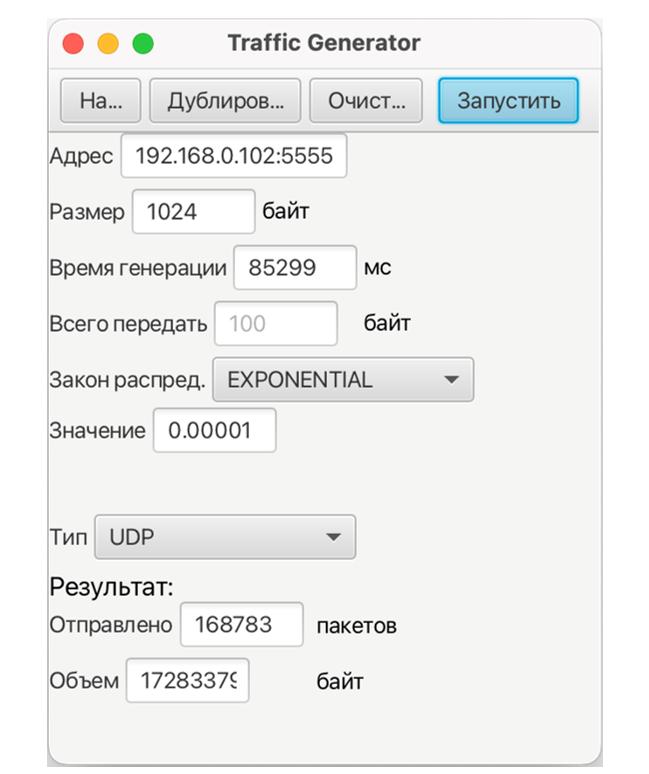
Рис. 2 – Генерация пакетов клиента с Экспоненциальным распределением
В данном окне указываются следующие параметры генерации: Адрес и порт сервера, Размер пакета, Время генерации пакетов, Размер передаваемого файла, Закон распределения, Параметры закона распределения, Тип трафика.
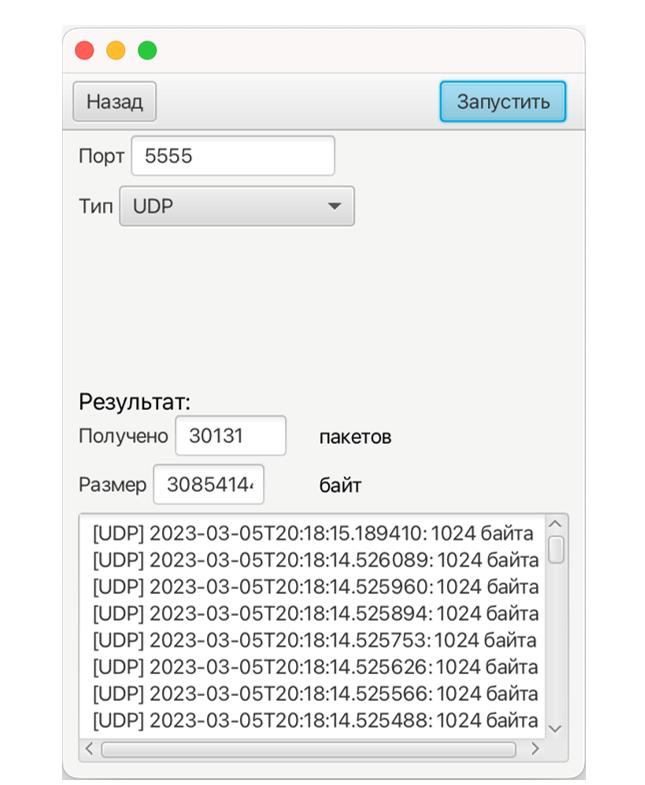
Рис. 3 – Принятие пакетов сервера
В данном окне происходит настройка сервера и указываются Порт и Тип трафика.
Эксперимент состоит из 3-основных этапов:
1. Выбрать по очереди закон распределения для каждого эксперимента (Эрланга, экспоненциальный, равномерный).
2. В каждом эксперименте установить размер пакета (несколько разных значений). Было выбрано 3 разных размера пакета, в которых размер полезных данных составляет – S (64 байта), M (512 байт), L (1024 байта).
3. Генерация пакетов происходит 120 секунд (2 минуты)
Результаты и анализ исследования
С использованием известных формул математической статистики, определяются моментные характеристики временных интервалов. В работе использованы статистики до 3-го порядка, которые позволяют судить о характере распределения интервалов. [5,6].
Среднее значение интервала между соседними пакетами (1) вычисляется для оценки частотности пакетов в сети. Это позволяет определить, с какой регулярностью пакеты передаются по сети. Оценивая этот параметр, можно управлять потоком данных, что важно для поддержания качества услуг в сети.
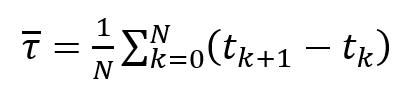 (1) (1)
где – моменты времени поступления пакетов;
N – количество анализируемых интервалов.
Выборочная дисперсия (2) – это статистический параметр, показывающий насколько велико отклонение каждого элемента выборки от её среднего значения. Этот показатель отражает степень разброса данных в выборке. Данный параметр полезен при анализе данных, чтобы понять, насколько данные изменяются или различаются.
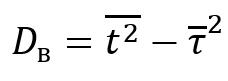 (2) (2)
где – второй начальный момент.
Второй начальный момент (3) своего рода статистической величины – это математическое ожидание квадрата этой величины. С его помощью можно оценить разброс наблюдаемых значений относительно нуля. Это важная характеристика при анализе случайных величин, особенно при использовании статистического моделирования и прогнозирования.
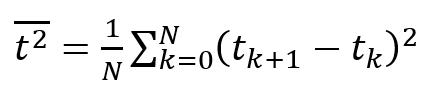 (3) (3)
Коэффициент вариации (4) – это статистический показатель, который определяет относительное изменение или разброс наблюдений в данной выборке. Чем больше коэффициент вариации, тем больше разброс данных в выборке. Используется для сравнения уровня изменчивости различных данных.
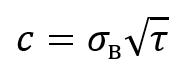 (4) (4)
где – стандартное отклонение
Асимметрия (5) – это статистический показатель, который характеризует степень отклонения распределения выборки от симметричного. Это позволяет оценить асимметрию распределения данных. Если асимметрия положительна, то распределение смещено вправо, если отрицательна – влево. Асимметрия равна нулю для симметричного распределения. Расчет асимметрии особенно важен при анализе данных для правильного выбора статистического подхода для анализа.
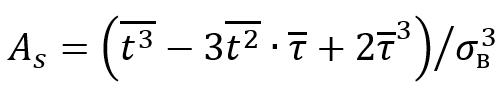 (5) (5)
где – третий начальный момент
Третий начальный момент (6) – это математическое ожидание куба случайной величины. Он используется для расчета коэффициента асимметрии, который характеризует степень отклонения распределения данных от симметричного. Данный параметр нужен для понимания формы распределения набора данных. Он дает информацию о том, является ли распределение набора данных скошенным и, если да, в какую сторону. Это важный параметр при выборе статистического подхода к анализу данных.
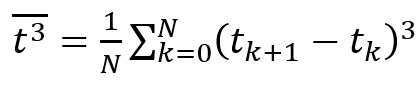 (6) (6)
Для расчета моментных характеристик данные из лог-файлов из Wireshark были импортированы в MS Excel. Будут учитываться пакеты, направляемые от клиента на сервер. В таблице 1 представлены данные разработанного клиент-серверного приложения, а в таблице 2 – данные программы Netem [7].
Таблица 1. Средние моментные характеристики интервала между пакетами по законам распределения с помощью разработанного клиент-серверного приложения
|
Закон распределения
|
Равномерный
|
Экспоненциальный
|
Эрланга
|
| |
2,1E-04
|
2,0E-04
|
1,4E-04
|
| |
1,1E-07
|
2,3E-07
|
2,1E-07
|
| |
4,1E-09
|
6,2E-09
|
6,8E-09
|
| |
1,3E-07
|
1,9E-07
|
1,8E-07
|
| |
2,2005
|
2,2192
|
3,0606
|
| |
~0
|
>0
|
>0
|
|
Время(с)
|
120
|
Таблица 2. Средние моментные характеристики интервала между пакетами по законам распределения с помощью программы Netem
|
Закон распределения
|
Равномерный
|
Экспоненциальный
|
Эрланга
|
| |
1,52E-03
|
2,19E-03
|
4,5E-02
|
| |
0,8E-06
|
2,9E-07
|
2,4E-06
|
| |
4,4E-09
|
5,1E-09
|
7,1E-09
|
| |
0,9E-06
|
3,3E-07
|
1,9E-06
|
| |
1,7955
|
2,4991
|
2,8375
|
| |
~0
|
>0
|
>0
|
|
Время(с)
|
120
|
|
| |
|
|
|
|
Исходя из расчета средних моментных характеристик интервала между пакетами по законам распределения с помощью разработанного клиент-серверного приложения и программы Netem можно сделать вывод, что разработанное приложение более точнее генерирует пакеты с задержками по законам распределения. Разница точности ~14% в пользу разработанного клиент-серверного приложения.
Коэффициент вариации показывает отличие трафика от пуассоновского потока и совместно с асимметрией позволяет судить о степени весомости хвостов распределений интервалов между пакетами
Второй начальный момент показывает дисперсию случайной величины, то есть меру разброса значений вокруг среднего значения. Чем больше значение второго начального момента, тем больше разброс значений и тем менее предсказуемым является процесс генерации пакетов. Наиболее меньший разброс наблюдается в равномерном распределении.
Третий начальный момент случайной величины показывает среднее значение ее куба. Если 3 начальный момент не равен нулю, то это говорит о том, что вероятности для значений, находящихся на разных расстояниях от среднего значения, не симметричны. Для равномерного распределения третий начальный момент самый низкий.
Асимметрия случайной величины показывает, насколько ее распределение отличается от симметричного. Если асимметрия равна нулю, то распределение симметрично. Если асимметрия больше нуля, то распределение скошено вправо (больше значений находится справа от среднего значения) и распределение имеет более тяжелый правый хвост. Для равномерного распределения асимметрия практически равна 0, для распределения Эрланга и Экспоненциального больше 0.
Если коэффициент вариации больше нуля, то это говорит о том, что разброс значений случайной величины относительно ее среднего значения велик. Таким образом, чем больше значение коэффициента вариации, тем выше уровень изменчивости случайной величины. В равномерном распределении коэффициент вариации самый маленький [8,9].
По полученным задержкам были построены гистограммы распределений.
При распределении Эрланга (рис. 4) значение задержки максимально на интервалах 336-430 мс. С увеличением интервалов задержка уменьшается.
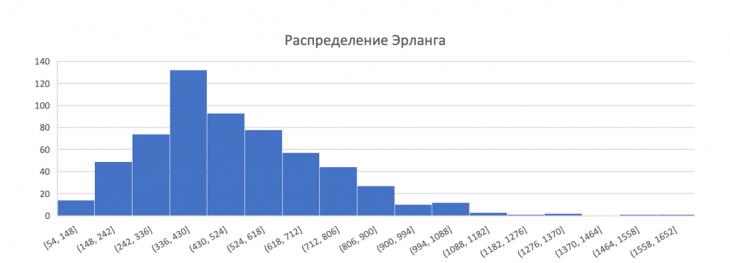
Рис. 4 – Полученная гистограмма распределения Эрланга
При Экспоненциальном распределении (рис. 5) задержки максимальные на коротких интервалах времени.
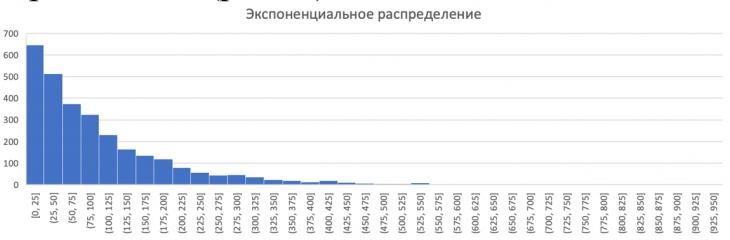
Рис. 5 – Полученная гистограмма Экспоненциального распределения
При Равномерном распределении (рис. 6) задержки для разных интервалов составляют 300 мс. Что значительнее хуже из вышеперечисленных.
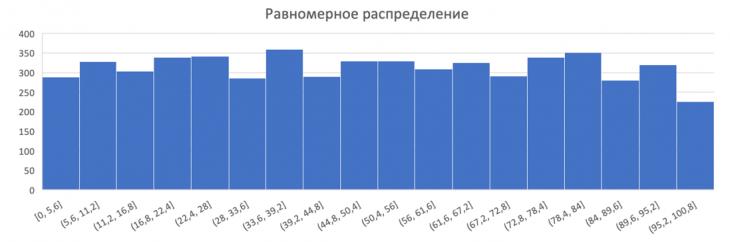
Рис. 6 – Полученная гистограмма Равномерного распределения
Объем, переданный за 2 минуты по каждому закону распределения включал в себя как полезные данные, так и служебные. В зависимости от размера пакета эффективность полезных данных менялась [10] (рис. 7). Максимальная эффективность достигалась при больших размерах пакетов.
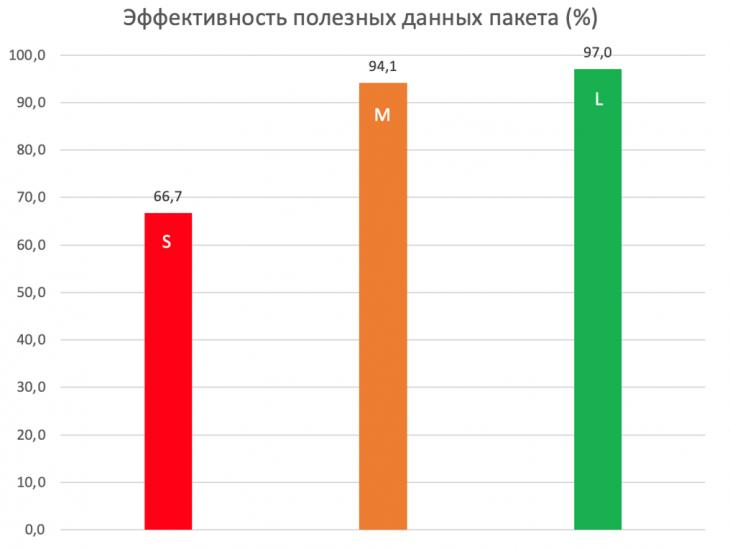
Рис. 7 – Эффективность полезных данных (S – 64 байта, M – 512 байт, L – 1024 байта)
В ходе эксперимента при пересылке данных происходили мелкие потери пакетов, в среднем менее 50 пакетов (<0.01%).
В процессе генерации пакетов от клиента, входящий трафик на сервере нагружал канал. В зависимости от размера пакета и закона распределения, нагрузка имела разные значения (рис. 8). При распределении Эрланга загруженность канала оказалась самой большой, что говорит о большей эффективности данной модели.
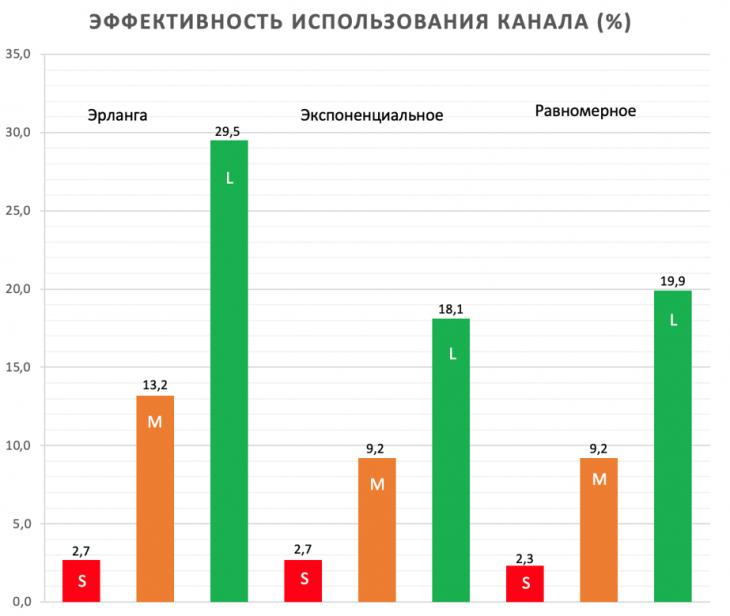
Рис. 8 – Загруженность канала по законам распределения (S – 64 байта, M – 512 байт, L – 1024 байта)
Считается, что для загруженных систем Ethernet и Fast Ethernet хорошим значением показателя использования сети является 30%. Это значение соответствует отсутствию длительных простоев в работе сети и обеспечивает достаточный запас в случае пикового повышения нагрузки [11]. Самым эффективным по загруженности канала законом стал трафик, генерируемый по распределению Эрланга, с размером пакета полезных данных 1024 байта (29,5%).
Этот же результат подтверждает среднее время генерации пакета. В зависимости от размера пакета и закона распределения, время имело разные значения (рис. 9) [12]. Модель с распределением Эрланга показала наименьшее среднее время генерации пакетов.
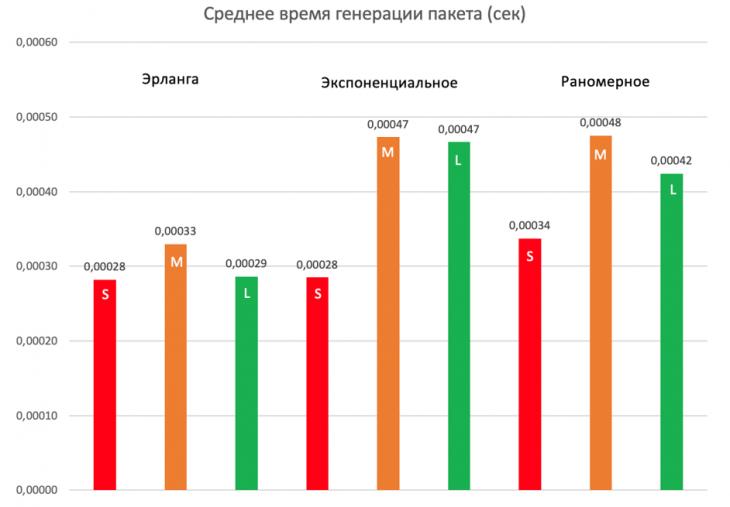
Рис. 9 – Среднее время генерации пакетов по законам распределения (S – 64 байта, M – 512 байт, L – 1024 байта)
Вывод
Генерация пакетов с задержками по стохастическим законам распределения (равномерное, экспоненциальное, Эрланга) имеет большое значение при моделировании и анализе работы сетевых систем. Также генерация пакетов с задержками по вышеупомянутым законам распределения позволяет проводить тестирование и отладку сетевых приложений и устройств в условиях, близких к реальным. Это позволяет выявлять возможные проблемы и улучшать работу сетевых систем. В результате эксперимента был предложен алгоритм, позволяющий восстанавливать моментные характеристики случайной величины интервала между пакетами для дальнейшего использования моделей массового обслуживания. Также, выполнен анализ влияния законов распределения на производительность экспериментального образца сети и получены оценки эффективности использования канала и среднего времени генерации пакетов в сегментах сети, а также гистограммы задержек по законам распределения. Наибольшая эффективность полезных данных наблюдается при размере пакета 1056 байт (1024 байт полезных данных). Наибольшая производительность канала наблюдается при использовании распределения Эрланга, с размером полезных данных 512 байт и 1024 байт. Также, данный факт подтверждает среднее время генерации одного пакета, которое показывает при распределении Эрланга наибольшую производительность
Библиография
1. Жукова Г.Н. Карта коэффициентов асимметрии и эксцесса в преподавании теории вероятностей и математической статистики// Концепт 2015. №8. С. 1-4.
2. Дмитриев Е.И., Медведев А.В. P-генератор случайных чисел, распределенных по экспоненциальному закону// Актуальные проблемы авиации и космонавтики 2011. №7. Том 1. С. 316-317.
3. Распределение Эрланга URL: http://algolist.ru/maths/matstat/erlang/index.php#:~:text=%D0%A0%BC. (Дата обращения 06.03.2023).
4. Как пользоваться Wireshark для анализа трафика. URL: https://losst.pro/kak-polzovatsya-wireshark-dlya-analiza-trafika (Дата обращения 06.03.2023).
5. Приложение для генерации пакетов в компьютерных сетях с помощью стохастических моделей распределения. URL: https://elibrary.ru/item.asp?id=50133060
6. Тарасов В.Н., Бахарева Н.Ф., Горелов Г.А., Малахов С.В. Анализ входящего трафика на уровне трех моментов распределений временных интервалов// Информационные технологии 2014. №9. С. 54-59.
7. Эмуляция влияния глобальных сетей. URL: https://habr.com/ru/articles/24046/ (Дата обращения 10.05.2023).
8. Руководство по настройке производительности. URL: http://www.regatta.cs. msu.su/doc/usr/share/man/info/ru_RU/a_doc_lib/aixbman/prftungd/2365c91.htm (Дата обращения 10.05.2023).
9. Алгоритмы сети Ethernet/Fast Ethernet. URL: https://intuit.ru/studies/professional_retraining/943/courses/57/lecture/1690?page=2 (Дата обращения 10.05.2023).
10. Снабжение пакетов данных точными временными метками в системах сетевого мониторинга. URL: http://www.treatface.ru/solutions/sistemy-setevogo-monitoringa/snabzhenie-paketov-dannykh-tochnymi-vremennymi-metkami-v-sistemakh-setevogo-monitoringa (Дата обращения 10.05.2023)
References
1. Zhukova, G.N. (2015). A Map of Skewness and Kurtosis Coefficients in Teaching Probability Theory and Mathematical Statistics. Concept, 8, 1-4.
2. Dmitriev, E.I., & Medvedev, A.V. (2011). P-Exponential Random Number Generator. Actual Problems of Aviation and Astronautics, 7, 316-317.
3. Erlang distribution. (Accessed March 6, 2023). Retrieved from http://algolist.ru/maths/matstat/erlang/index.php#:~:text=%D0%A0%BC
4. How to use Wireshark for traffic analysis. (Accessed March 6, 2023). Retrieved from https://losst.pro/kak-polzovatsya-wireshark-dlya-analiza-trafika
5. Yakupov, D.O. (2023). Application for generating packets in computer networks using stochastic distribution models. Retrieved from https://elibrary.ru/item.asp?id=50133060
6. Tarasov, V.N., Bakhareva, N.F., Gorelov, G.A., & Malakhov, S.V. (2014). Analysis of incoming traffic at the level of three moments of time interval distributions. Information Technology, 9, 54-59.
7. Emulation of the influence of global networks. (Accessed May 10, 2023). Retrieved from https://habr.com/ru/articles/24046/
8. Performance Tuning Guide. (Accessed May 10, 2023). Retrieved from http://www.regatta.cs msu.su/doc/usr/share/man/info/ru_RU/a_doc_lib/aixbman/prftungd/2365c91.html
9. Ethernet/Fast Ethernet network algorithms. (Accessed May 10, 2023). Retrieved from https://intuit.ru/studi/professional_retraining/943/sources/57/lecture/1690?page=2
10. Providing data packets with accurate timestamps in network monitoring systems. (Accessed May 10, 2023). Retrieved from http://www.treatfake.ru/solutions/network-monitoring-systems/accurate-time-stamping-of-data-packets-in-network-monitoring-systems
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования. Статья, исходя из названия, должна быть посвящена исследованию стохастических моделей генерации пакетов в компьютерных сетях. Содержание статьи соответствует заявленной теме.
Методология исследования включает в себя использование таких методов исследования как анализ и синтез данных. Также ценно, что автор активно применяет графический инструментарий для демонстрации полученных научных результатов.
Актуальность исследования вопросов, связанных с применением стохастических моделей генерации пакетов в компьютерных сетях, не вызывает сомнения. Решение существующих проблем в данном направлении позволит значительно ускорить технологическую модернизацию российской экономики, тем самым обеспечить вклад в достижение национальных целей развития Российской Федерации на период до 2030 года, определённых в Указе Президента России от 07.05.2024 года.
Научная новизна в представленном на рецензирование материале присутствует. В частности, она может быть связана с представленной на рисунке 1 схемой экспериментальной установки (при условии, что это авторская разработка).
Стиль, структура, содержание. Стиль изложения научный. Структура статьи автором не выстроена. Рекомендуется при доработке статьи сформировать следующие структурные элементы: «Введение», «Постановка проблемы», «Методология и условия исследования», «Результаты исследования», «Обсуждение результатов исследования», «Выводы и дальнейшие направления исследования». Ознакомление с содержанием позволяет сделать вывод о том, что автор немного сбивчиво излагает полученные результаты (что, вероятнее всего, обусловлено отсутствием чётко выраженной структуры исследования). Также автору рекомендуется добавить анализ каждого графического объекта, т.к. в текущей редакции в статье содержатся только отсылки констатационного формата («на рисунке представлено то-то»). Читателя интересуют выводы, формируемые авторам по каждому графическому объекту. Представляется выигрышным добавление в текст статьи таблицы, содержащей список ключевых авторских идей и проблем, решаемых при реализации данных рекомендаций. Более того, автору необходимо внимательно вычитать статью на предмет орфографических и пунктуационных ошибок как в тексте статьи, так и в списке литературы.
Библиография. Сформированный автором библиографический список состоит из 10 наименований, из которых только 2 представляют собой научные публикации. При проведении доработки статьи автору рекомендуется расширить количество изученных источников, в т.ч. добавив иностранные научные публикации.
Апелляция к оппонентам. При проведении доработки статьи и расширении числа источников, являющихся научными публикациями, автору следует сравнить полученные научные результаты с итогами исследований, проведённых другими авторами в России и за рубежом. Это позволит также усилить научную новизну исследования и привлечь дополнительную читательскую аудиторию.
Выводы, интерес читательской аудитории. С учётом всего вышеизложенного, заключаем о том, что автором выбранная тема исследования, научные статьи по которой будут востребованы у читательской аудитории. При этом статья требует доработки по указанным в тексте рецензии замечаниям.
Результаты процедуры повторного рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензируемая статья посвящена исследованию стохастических моделей процесса создания и отправки пакетов данных через компьютерные сети.
Методология исследования базируется на использовании собранной авторами публикации экспериментальной установки, состоящей из клиента и сервера, на котором было установлено программное обеспечение языке программирования Java для анализа входящего трафика Wireshark.
Актуальность работы авторы связывают с тем, что генерация пакетов – важная функция, которая используется в современных компьютерных сетях для передачи информации между устройствами путем разбиения больших объемов данных на меньшие блоки, которые могут быть переданы через сеть более быстро и надежно, кроме этого появляется возможность управлять потоком данных и контролировать качество обслуживания в сети.
Научная новизна рецензируемого исследования: предложен алгоритм, позволяющий восстанавливать моментные характеристики случайной величины интервала между пакетами для дальнейшего использования моделей массового обслуживания; получены оценки эффективности использования канала и среднего времени генерации пакетов в сегментах сети, а также гистограммы задержек по различным законам распределения; выявлено, что наибольшая производительность канала наблюдается при использовании распределения Эрланга.
Структурно в статье выделены следующие разделы: Введение, Постановка проблемы, Методология и условия исследования, Результаты и анализ исследования, Вывод и Библиография.
Авторами выполнен эксперимент по описанной в статье схеме, показаны средние моментные характеристики интервала между пакетами по законам распределения с помощью разработанного клиент-серверного приложения, приведены полученные гистограммы распределения Эрланга, экспоненциального и равномерного распределений, отражена эффективность полезных данных. Отмечено, что наибольшая эффективность полезных данных наблюдается при размере пакета 1056 байт (1024 байт полезных данных), наибольшая производительность канала наблюдается при использовании распределения Эрланга с размером полезных данных 512 байт и 1024 байт.
Библиографический список включает 10 источников – электронные интернет-ресурсы и научные публикации отечественных ученых по рассматриваемой теме. В тексте публикации имеются адресные отсылки к списку литературы, подтверждающие наличие апелляции к оппонентам.
Из недостатков публикации, требующих своего устранения, стоит отметить, что формулы 1 – 6 не отражаются в тексте статьи, размещенной в информационной системе издательства – это делает невозможным проведение оценки их смыслового содержания. Кроме этого отсутствуют расшифровки условных обозначений на рисунках 7, 8 и 9, а также подписи осей на рисунках 4, 5 и 6.
Рецензируемый материал соответствует направлению журнала «Программные системы и вычислительные методы», отражает результаты проведенного авторского исследования, может вызвать интерес у читателей, может быть рекомендован к опубликованию после доработки в соответствии с высказанным замечанием.
Результаты процедуры окончательного рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
В статье исследуются стохастические модели генерации пакетов в компьютерных сетях. Основное внимание уделяется сравнению равномерного, экспоненциального распределений и распределения Эрланга в контексте их точности и эффективности при моделировании реального сетевого трафика. Методология исследования включает теоретический анализ выбранных стохастических моделей и их экспериментальную проверку с использованием клиент-серверной установки. Применение программного обеспечения Wireshark для анализа входящего трафика позволяет детально оценить характеристики генерируемых пакетов. Программное обеспечение, используемое для генерации пакетов, написано на языке Java и тестировалось на различных операционных системах, что обеспечивает широкую применимость результатов исследования. Актуальность исследования обоснована значимостью точного моделирования сетевого трафика для обеспечения стабильности и безопасности компьютерных сетей. В условиях быстро растущего объема данных и усложняющихся сетевых структур, точное моделирование и анализ сетевого трафика являются критически важными для поддержания эффективной работы сетевых инфраструктур. Научная новизна работы заключается в сравнении различных стохастических моделей генерации пакетов и в разработке методики для более точного моделирования реального сетевого трафика. Авторы приводят новые данные о точности и эффективности различных моделей, что позволяет более объективно оценивать их применение в реальных сетевых условиях. Статья написана в ясном и доступном стиле, с четкой структурой, что облегчает восприятие материала. Введение плавно вводит в тему исследования, подробно объясняя необходимость и значимость генерации пакетов. Основная часть статьи посвящена детальному описанию моделей и экспериментальной установки, а также анализу полученных результатов. Заключение подводит итоги исследования и формулирует основные выводы. Выводы статьи четко сформулированы и обоснованы экспериментальными данными. Авторы приходят к заключению, что модель распределения Эрланга показала наибольшую производительность и точность в моделировании реального сетевого трафика, что подтверждается полученными результатами. Также отмечается, что использование данной модели позволяет улучшить параметры сети и повысить эффективность ее работы. Статья представляет интерес для широкой аудитории, включая исследователей в области компьютерных сетей, разработчиков программного обеспечения и специалистов по сетевой безопасности. Работа способствует углублению понимания процессов генерации пакетов и улучшению методов моделирования сетевого трафика, что имеет важное практическое значение. Статью рекомендую принять к публикации, так как она представляет собой ценный вклад в область исследования стохастических моделей генерации пакетов в компьютерных сетях и обладает высокой научной и практической значимостью.
Рекомендация: междисциплинарные исследования могут существенно обогатить данную работу. Следует изучить возможность применения стохастических моделей генерации пакетов в смежных областях, таких как интернет вещей (IoT), облачные вычисления и большие данные. Сотрудничество с исследователями из других областей для проведения междисциплинарных исследований и обмена опытом будет способствовать развитию новых идей и подходов.
|
 Рус
Рус
























