|
Software systems and computational methods
Правильная ссылка на статью:
Kiryanov D.A.
A Scalable Aggregation System Designed to Process 50,000 RSS Feeds
// Программные системы и вычислительные методы.
2022. № 4.
С. 20-38.
DOI: 10.7256/2454-0714.2022.4.39124 EDN: FLDOVB URL: https://nbpublish.com/library_read_article.php?id=39124
A Scalable Aggregation System Designed to Process 50,000 RSS Feeds /
Масштабируемая система агрегации, предназначенная для обработки 50 000 RSS-каналов
Кирьянов Денис Александрович
ORCID: 0000-0001-8502-8333
магистр, Балтийский государственный технический университет ВОЕНМЕХ имени Д. Ф. Устинова
190005, Россия, г. Санкт-Петербург, ул. 1-Я красноармейская, 1
Kiryanov Denis Aleksandrovich
Master's Degree, Department of Information Systems and Software Engineering, Baltic State Technical University "Voenmeh" anmed after D. F. Ustinov
190005, Russia, Saint Petersburg, 1st Krasnoarmeyskaya str., 1

|
dennis.kiryanov@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2022.4.39124
EDN: FLDOVB
Дата направления статьи в редакцию:
07-11-2022
Дата публикации:
30-12-2022
Аннотация:
Предметом исследования является архитектура системы агрегации RSS-каналов. Автор подробно рассматривает такие аспекты темы, как выбор правильной стратегии агрегации данных, подход к масштабированию распределенной системы, проектирование и реализация основных модулей системы, таких как модуль определения стратегии агрегации, модуль агрегации контента, модуль обработки данных, модуль поиска. Особое внимание в данном исследовании уделяется детальному описанию выбранных для реализации рассматриваемой системы библиотек и фреймворков, а также баз данных. Основная часть рассматриваемой системы реализована на языке программирования C# (.Net Core) и является кросс-платформенной. В исследовании описывается взаимодействие с основными хранилищами данных, использованных при разработке системы агрегации, которыми являются PostgreSQL и Elasticsearch. Основным выводом проведенного исследования является то, что перед разработкой системы агрегации необходимо проводить анализ публикационной активности источников данных, на основе которого возможно сформировать приемлемую стратегию обновления поискового индекса, сэкономив значительное количество вычислительных мощностей. Системы агрегации контента, подобные рассматриваемой в данном исследовании, должны быть распределенными, построенными на основе событийно-ориентированной и микросервисной архитектур. Данный подход позволит сделать систему устойчивой к высоким нагрузкам и сбоям, а также легко расширяемой. Особым вкладом автора в исследование темы является детальное описание высокоуровневой архитектуры RSS-агрегатора, рассчитанного на обработку 50 000 каналов.
Ключевые слова:
агрегация RSS, Elasticsearch, RabbitMQ, микросервисная архитектура, паттерн конкурирующих потребителей, масштабируемость, отказоустойчивость, кроссплатформенность, категоризация контента, экспертная система
Abstract: The subject of the study is the architecture of the RSS feed aggregation system. The author considers in detail such aspects of the topic as choosing the right data aggregation strategy, an approach to scaling a distributed system, designing and implementing the main modules of the system, such as an aggregation strategy definition module, a content aggregation module, a data processing module, a search module. Particular attention in this study is given to a detailed description of the libraries and frameworks chosen for the implementation of the system under consideration, as well as databases. The main part of the system under consideration is implemented in the C# programming language (.Net Core) and is cross-platform. The study describes the interaction with the main data stores used in the development of the aggregation system, which are PostgreSQL and Elasticsearch. The main conclusion of the study is that before developing an aggregation system, it is necessary to analyze the publication activity of data sources, on the basis of which it is possible to form an acceptable strategy for updating the search index, saving a significant amount of resources. computing power. Content aggregation systems, such as the one considered in this study, should be distributed, built on the basis of event-driven and microservice architectures. This approach will make the system resistant to high loads and failures, as well as easily expandable. The author's special contribution to the study of the topic is a detailed description of the high-level architecture of the RSS aggregator, designed to process 50,000 channels.
Keywords: RSS aggregation, Elasticsearch, RabbitMQ, microservice architecture, competing consumers pattern, scalability, fault tolerance, cross-platform, content categorization, expert system
1 Introduction
Within the current data-intensive era the content volume is increasing rapidly and there is an obvious need in specialized content aggregators, which aim at collecting data on a specific topic: medicine, finances, realty estate, etc. This article is about an RSS aggregator that collects data for IT professionals and is part of the DevsDay website [1].
DevsDay provides its users with aggregated IT-related content: news, meetups, blogposts, jobs, company reviews, etc., and RSS feed aggregation is the efficient way to get relevant data. Since there are a lot of IT specializations, like web development, DevOps, quality assurance or game development, there are thousands of authors on the Internet who publish related blogposts. Most companies also have their own blog and news feed, and these also need to be aggregated.
Building and maintaining such a large-scale content aggregator is a very complex task: tens of thousands of RSS feeds need to be processed, and the problem is exacerbated by the fact that many content sources provide data with different refresh rates and RSS formats, and some of them also restrict access to their content. Another problem is that the system should handle hundreds of search requests per second from web users and provide them with relevant content in a very fast way.
This paper follows the research on the methods of building content aggregation systems [2], and proposes a comprehensive architecture for a distributed RSS content aggregator, including crawler and search modules.
The described system has already been implemented and is expected to be integrated into DevsDay to replace their old RSS aggregation mechanism. Also, the developed system is designed to replace the search engine based on Postgres FTS [3] with Elasticsearch [4].
The paper is organized as follows. Section 2 contains the problem statement and related work analysis. Section 3 presents the proposed RSS aggregation system design. Section 4 briefly discusses the results of the developed system. Section 5 concludes the paper by presenting author’s conclusions and future directions.
2 Problem statement and analysis of related work
According to the DevsDay needs, the RSS feed aggregator should be able to solve the following tasks. First, it should be fast and fault-tolerant, should be able to cope with large amounts of data sources. Secondly, it should be able to select the appropriate content retrieval strategy in order to bypass frequently updated feeds in time and not lose content. Thirdly, the system should provide a special mechanism to prevent duplicates, spam and, for example, advertisements or other unwanted data. Finally, there should be an efficient search functionality implemented to allow users to search online through the aggregated data.
A crawler is a special program that automates web browsing operations using links and processes the content of web pages. The crawler often saves a web page or part of it in a database for further processing by other programs. The main principles of the web crawler’s design are explained in [2, 5, 6].
In general, crawling is a core mechanism of every web content aggregator. A crawling system is often divided into several layers, which are responsible for storing URLs to crawl, a distributed set of crawler modules for extracting content, a processing layer, and a database that stores aggregated content. RSS crawlers are no exception and follows these principles.
There is a large body of work available on web crawling, but this section focuses exclusively on crawling RSS feeds, with a brief description of the architecture of such systems.
The studies [7, 8] present RoSeS, a running system for large-scale content-based RSS filtering and aggregation, based on a declarative link aggregation model with precise semantics for links and aggregation queries. The RoSeS system has its own language that provides instructions for registering feeds, defining new feeds, and creating subscriptions.
The RoSeS system consists of three main layers, each responsible for RSS feeds processing: Acquisition, Evaluation, and Dissemination. The Acquisition layer transforms RSS documents into a continuous stream of RoSeS items and passes them to the Evaluation layer where these items are processed based on an algebraic multi-query plan. The Dissemination layer transforms the RoSeS items into different output formats (SMS, email, RSS/Atom feed, etc.) and notifying new items to corresponding user subscriptions.
In [9], an auto fill system was presented that allows aggregating RSS feeds. The paper also discusses the design and implementation of a relational database, as well as the CMS administration module.
In [10], the Atlas web application for aggregating RSS feeds from various news sources is described. Atlas provides special features for grouping and translating information into a readable format. It consists of a content loading module, a layer that stores aggregated data, and a web interface.
Paper [11] describes the RSS Watchdog system which is capable of news clustering and instant event monitoring over multiple RSS feeds. The system’s crawling engine runs periodically and handles RSS channels simultaneously. There is a parsing module that extracts news items from the feeds, and update module that checks if an item is new or duplicate. A clustering module is responsible for grouping the corresponding items into clusters and creating a series of clusters on each channel.
Paper [12] presents a new technique for creating news aggregation based on RSS feeds. It also describes automated methods for summarizing and classifying aggregated data.
Paper [13] presents an RSS-based news aggregator that aggregates relevant articles for a specific input keyword or key phrase. The system consists of three main stages: aggregation, pre-processing and processing stage. Aggregated articles go through the pre-processing stage to apply lowercasing, stop-word removal, lemmatization and stemming. At the processing stage, the system applies a TextRank summarization algorithm [14] on the aggregated articles.
Paper [15] discusses the Personalized News Service (PNS), a news aggregator which provides its users with personalized access to news collected from various sources. It has three main modules: a content scanning module, a content selection module, and a content presentation module.
The content scanning module aggregates news feeds based on a list of sources stored in the database. The content selection module provides personalized views based on personal interests, and the content presentation module provides a search function and identifies users by providing them with personalized news.
In [16], the authors focus on visual sentiment analysis of RSS feeds, presenting a tool that automatically extracts and analyzes RSS feeds in relation to positive and negative opinions. The proposed news similarity filter allows highlighting redundant news items.
Paper [17] introduces myDataSharer, which combines community and data into one entity, allowing participants to freely form communities of stakeholders and parties. The data is uploaded from a wide variety of formats, including RSS. The service provides visualization through charts, each user has a personalized homepage with an Ajax-based search functionality. myDataSharer forms a typical muti-tier web application, is implemented using Java and MySql, and runs on an Apache Tomcat server.
3 The proposed RSS aggregation system
The proposed system is able to process 50,000 RSS feeds, and its main performance benefits are fault tolerance and scalability, content filtering and categorization. The system chooses an aggregation strategy based on the statistics of data sources and reduces the cost of computing power.
3.1 System architecture
The considered RSS aggregation system was built using the .Net Core platform [18] and the C# programming language. It is a distributed modular system where each component can be easily scaled or modified. Thanks to the use of the .Net Core framework, the system is cross-platform, which means that its components can run on multiple operating systems, such as Windows or Linux.
The system’s high-level architecture is shown in Figure 1. Based on the previous research [2], it consists of an Aggregation Policy module (green), a Crawling module (red), a Processing module (blue) and a Search module (yellow). The following sections discuss them in detail.
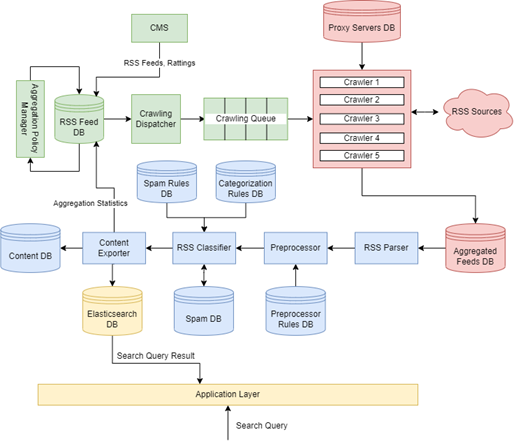
Figure 1 – The high-level architecture of the proposed RSS aggregator
3.2 Aggregation Policy module
The Aggregation Policy module has the duty of analyzing the RSS feeds and determining the order in which they should be bypassed by the crawler. It consists of the following components: an Aggregation Policy Manager to define strategies for updating RSS feeds; an RSS Feed Database that stores feeds; a Content Management System (CMS), which allows to add new feeds to the RSS Feeds Database and manage them; a Crawling Dispatcher component for generating a message with information about the sources to be scanned; a Crawling Queue to send the messages to the crawlers.
The main technical problem of this module is to set up the correct strategy for updating the RSS feeds, i.e., to determine the most appropriate time to rescan the feeds and not lose updates. Since the RSS aggregator does not know the exact moment at which new posts are created, it can only estimate the expected delay. This is a well-studied scientific problem, and many studies have been devoted to it.
Study [19] proposes a refresh strategy based on Lagrange multipliers optimization method. An alternative approach [20] to feeds monitoring based on Boltzmann learning takes into account the frequency of feed updates, as well as their content. Paper [21] shows the importance of the per-domain RSS feed scanning approach, since web pages of different domains change differently. It also shows that the crawl priority depends on the expected number of newly published items.
Paper [22] presents adaptive channel polling algorithms that learn from the previous behavior of the channels and predict their best update time. A theoretical foundation for improving the freshness of the aggregated data and the Poisson process verification is presented in [23]. In accordance with it, the homogeneous Poisson model is suitable for change events with a frequency of at least one month. But for smaller average intervals of change, the homogeneous Poisson model is not suitable. Experiments [24] show that the inhomogeneous Poisson process is the best choice for feeds that have a highly dynamic but periodic publishing nature.
The approaches described above require significant computational resources and their implementation is not trivial. Therefore, the Aggregation Policy module was developed using a strategy of periodic access to data sources, taking into account their publication activity.
According to a study [25], 17% of RSS feeds provide 97% of the data. This means that it is not necessary to scan every RSS feed at the same frequency, since most of them do not provide any updates for a long time. The proposed approach is to divide the data sources into three groups, as shown in Figure 2, for each of the groups, determine the frequency of scanning and then carry out crawling, processing the most frequently updated RSS feeds.
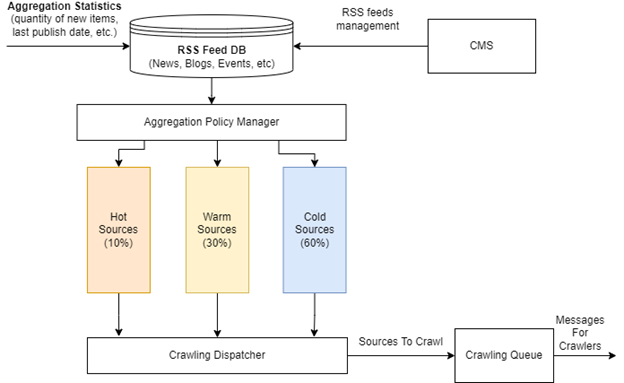
Figure 2 – Aggregation Policy module
The RSS Feed database component uses a PostgreSQL [26] relational database which is free and well-documented. The Aggregation Policy Manager processes this database and groups the RSS feeds into separate tables named Hot Sources, Warm Sources, and Cold Sources. The Hot Sources table contains up to 10% of all RSS feeds in the database that publish more than 8 feed items per day or are selected by a moderator as the most interesting feeds. The Warm Sources table contains up to 30% of all feeds with post activity from 3 to 8 items per day. The Cold Sources table contains the remaining feeds with a publish rate less than 3 items per day.
The algorithm of this application is associated with the problem of determining the frequency of scanning, which is explained below.
An analysis of 834,954 publications over the past 5 years from more than 300 news sources (IT news) and 93,620 publications from the most active IT bloggers and specialized sites (more than 250) over the same period (data provided by DevsDay) showed that the content on the Internet posted by sources is heterogeneous: 70% of articles, blogs and other publications are posted between 8 a.m. and 6 p.m.
The result of this analysis is shown in Figure 3, where the yellow color represents the percentage of news publications, and the blue color represents the publications of bloggers and specialized sites by hour.
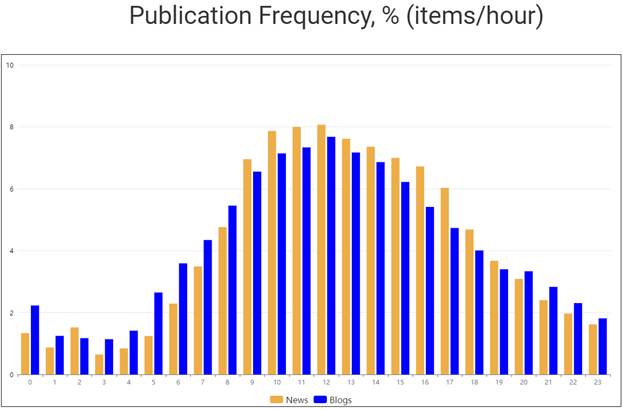
Figure 3 – Percentage of publication frequency (items/hour)
The statistics shown in Figure 3 means that some posts from the most active sources may be lost if the aggregation frequency is low. To prevent this from happening, the Aggregation Policy Manager automatically analyzes the aggregated feeds and determines the most appropriate crawling frequency for the Hot Sources and size for the Hot, Warm, and Cold Sources tables.
Currently, the Hot Sources feed crawl rate between 8 am and 6 pm averages 1 crawl/225 seconds. The rest of the time, uniform access to data sources is carried out at a frequency of 1 crawl/900 seconds. Feeds from the Warm Sources are less active and prioritized, and have a constant crawling rate of 1 crawl/1200 seconds. The Cold Sources table mainly contains blogger feeds that post very infrequently. The Cold Sources crawl rate is also constant at 1 crawl per hour.
This approach makes it possible to reduce the number of processed feeds and concentrate the computing resources of the RSS feed aggregation system on processing frequently updated sources. The estimated statistics for the proposed scanning strategy are shown in Table 1.
Table 1 – Estimated statistics for the proposed crawling strategy
|
Source Name
|
Threshold
|
Max Feeds
|
Messages per Crawl
|
Crawls per Day
|
Messages per Day
|
|
Hot Sources
|
10%
|
5,000
|
50
|
216
|
10,800
|
|
Warm Sources
|
30%
|
15,000
|
150
|
72
|
10,800
|
|
Cold Sources
|
60%
|
30,00
|
300
|
24
|
7,200
|
|
Total:
|
100%
|
50,000
|
500
|
312
|
28,800
|
Table 1 shows that the proposed crawling strategy requires up to 312 crawls per day to process a database of 50,000 RSS feeds. The system must also send 28,800 messages, each containing 100 channel URLs. Compared to a naive iterative crawl strategy with a constant crawl rate of 6 crawls per hour (144 per day), which requires processing 72,000 messages per day, this can be seen as a significant improvement in terms of increasing the frequency of crawling the most frequently updated feeds (216 crawls instead of 144) and the volume of messages processed (28,800 messages instead of 72,000 messages).
The last remaining component of the Aggregation Policy module, the Crawling Dispatcher module, accesses sources on a schedule, creates messages containing 100 RSS feeds to crawl, and then sends them to a Crawling Queue built on top of a 2-node RabbitMQ cluster [27-30], which is scalable and fault-tolerant.
The Crawling Queue module uses the competing consumers pattern [31-33] to distribute time-consuming tasks among multiple workers. This approach allows to process messages simultaneously and improve the overall performance of the Crawling module and other modules in the aggregation system that require parallel execution of tasks. In what follows, unless otherwise specified, this particular pattern is used.
3.3 Crawling module
According to Figure 1, the Crawling module consists of a distributed network of 5 crawlers running in parallel, a Proxy Servers database, and an Aggregated Feeds database (PostgreSQL). A crawler is an application that consumes messages from the Crawling Queue and performs a parallel download of each RSS feed in the message using an HttpClient [34].
The crawlers are only responsible for scanning RSS feeds and saving the response as is, without parsing it or performing some additional processing. Depending on the response speed of the RSS feed host, it can take up to 30 seconds to process a message containing 100 feeds. On average, the processing of such a message takes 4 seconds and requires up to 300 MB of RAM.
To avoid blocking IP addresses of the content aggregation system, proxy servers from the Proxy Servers database are used for each HTTP request. The crawler changes the proxy several times if there is a 403 forbidden error or any similar error restricting access to the RSS feed. Crawlers also register another errors and response time of the RSS feed hosts, and save this information to the Aggregation Feeds database.
3.4 Processing module
The Processing module processes the aggregated RSS feeds and makes them searchable by adding them to Elasticsearch database. It consists of the following components:
· An RSS Parser which is available for parsing RSS feeds;
· A Preprocessor responsible for sanitizing HTML markup, links normalization, etc.;
· An RSS Classifier which defines feed item topics and categories, and also detects spam and inappropriate content;
· A Content Exporter that saves processed data to the system’s databases.
3.4.1 RSS Parser
The RSS Parser consists of an Aggregated Feeds Migrator, a Parsing Queue, a cluster of RSS Parsers, and a Parsed Feeds database. A high-level architecture of the RSS Parser is shown in Figure 4.
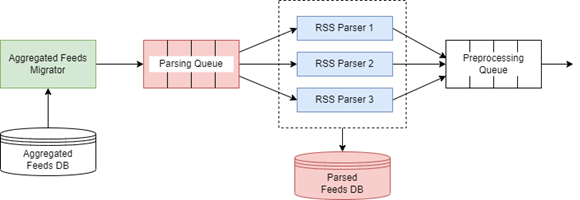
Figure 4 – High-level architecture of the RSS Parser
The Aggregated Feeds Migrator shown in Figure 4 is an application that queries the Aggregated Feeds database on schedule and sends recently added feed items to the Parsing Queue.
The Parsing Queue component is a RabbitMQ message queue which distributes parsing tasks among 3 RSS parsers for concurrent processing. RSS parsers are micro services that use the SyndicationFeed class [35] to deserialize the syndication feeds. This class is very useful and allows to get the image URLs, links, titles, categories, etc. of a feed item in a convenient way.
RSS parsers store parsed feed items in the Parsed Feeds database to prevent data loss and then push messages containing deserialized items to a Preprocessing Queue for further processing.
3.4.2 Preprocessor
As it was mentioned previously, the Preprocessor component is responsible for HTML sanitizing and links normalization, and includes the Preprocessing Queue, a cluster of 3 Preprocessors, a Preprocessor Rules database, and a Preprocessed Feed Items database. A high-level architecture of the Preprocessor is shown in Figure 5.
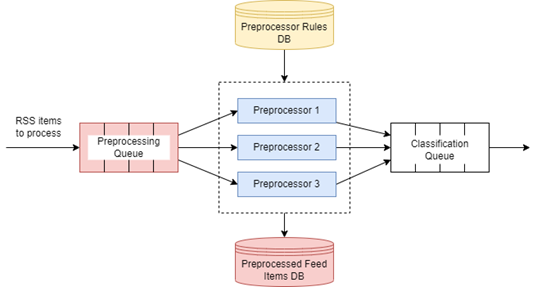
Figure 5 – High-level architecture of the Preprocessor
As shown in Figure 5, preprocessing starts from the moment RSS items are sent to the Preprocessing Queue by the RSS Parser component. The Preprocessing Queue is organized the same way as the Parsing Queue and has 3 Preprocessor workers performing tasks concurrently.
Preprocessor apps use special sanitizing rules in Preprocessed Rules database, such as lists of allowed HTML tags and attributes, available image extensions, rules for generating absolute URIs, lowercase and uppercase titles, etc. It is built using the Html Agility Pack [36], an HTML parser that allows read and write the DOM. XPpath [37, 38], an expression language is also used to navigate the DOM.
After HTML sanitization, preprocessors perform stemming [39, 40] using the PorterStemmer library [41], which is based on Porter's [42] stemming algorithm and is applicable to both Russian and English languages.
Figure 6 illustrates the difference between a crawled RSS feed item and a preprocessor output message.

Figure 6 - The difference between a crawled RSS feed item and a preprocessor output message
The RSS feed item shown in Figure 6.b is part of the RSS feed processed by the Crawler component. Then it was parsed by the RSS Parser and sent to the Preprocessor. The preprocessed output message shown in Figure 6.b is a JSON object containing a set of "stems" that is the result of stemming. It also contains HTML encoded markup in the "content" property, formatted publication date ("publishDate"), language, title, etc.
Preprocessors save processed data to the Preprocessed Feed Items database to prevent data loss on failure and then push feed items for further classification to the Classification Queue.
3.4.3 RSS Classifier
The RSS Classifier consists of 3 message queues: Classification Queue, Categorization Queue, and Export Queue. There are also 2 clusters of workers, each including 3 microservices: a cluster of Spam Detectors, and a cluster of Categorizators. A high-level architecture of the RSS Classifier component is shown in Figure 7.
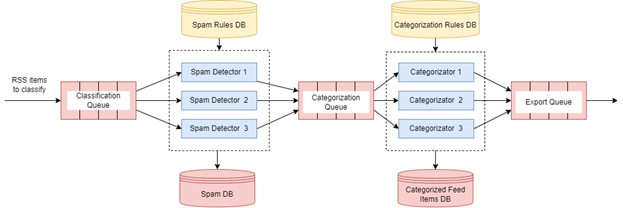
Figure 7 – High-level architecture of the RSS Classifier
As it shown in Figure 7, the Spam Detector services consume messages from the Classification Queue and detect spam and inappropriate content based on rules from the Spam Rules database.
Spam detection is a very topical scientific problem and is currently being actively studied [43-48]. This problem is often solved by combining machine learning algorithms with rule-based expert systems, as well as by directly scanning text for spam.
The Spam Rules database contains a list of spam words and phrases, blacklisted URLs and email addresses, which are used by Spam detectors. In the current implementation, Spam Detectors scan each RSS feed item for a direct match of the spam word or phrase. Scanning is also performed on the “stems” collection of the feed item’s JSON object. If there is a match, the incoming feed item is treated as spam and added to the Spam database, otherwise it is placed in a categorization queue for further processing.
The categorization and classification of aggregated content is also considered a popular research topic and a growing trend. This problem is usually solved using natural language processing, machine learning methods [49-51], and rule-based expert systems [52-55]. In general, these methods involve keyword extraction and analysis.
Regarding the business logic of the RSS aggregation system under consideration, the purpose of text categorization is to associate aggregated feed items with predefined categories using some criteria. In turn, the classification of RSS feeds includes determining their main topic and deciding which group they belong to.
The categories are relatively coarse-grained, such as “software testing”, “gadgets”, “open-source software”, “games”, “devops”, “databases”, “programming”, etc. An example of the topic could be a word or phrase, for example: “Postgres administration”, “memory management”, “Linux desktop”, etc.
Each Categorizator in the Categorization cluster is a rule-based expert system built on top of NRules [56], an open-source production engine for .Net based on the Rete matching algorithm [57, 58]. It applies over 200 XML-formatted rules from the categorization rules database to the RSS feed item's "stems" collection and decides which category and topic it belongs to.
For example, after analyzing the “stems” for the RSS feed item shown in Figure 6, it will be categorized as “front-end development” with four related topics: “CSS”, “CSS selectors”, “fonts”, “language”.
Finally, Categorizators perform preliminary saving data processed to the Categorized Feed Items database and push messages to the Export Queue.
3.4.4 Content Exporter
The Content Exporter alternately saves the data to the Content database, which is the main storage for aggregated RSS feeds, then saves the crawl statistics to the RSS Feed database, and finally updates the Elasticsearch database, which is used to search the aggregated data.
Similar to the component’s design described above, it uses an approach of worker scaling of three per cluster. Thus, there are three app clusters containing Content Exporters, RSS Feed DB Exporters, and ES Exporters. The microservices use the RSS Feed DB Queue and Elasticsearch Queue to distribute tasks.
A high-level design of the Content Exporter is shown in Figure 8.
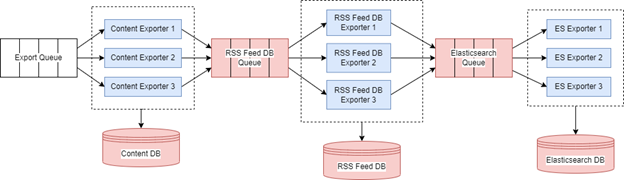
Figure 8 - High-level design of the Content Exporter
3.5 Search module
The Search module is based on Elasticsearch, which is a high-scalable search system available to query very large volumes of data in real time. Due to its flexibility and performance, Elasticsearch has been successfully used in many projects [59-64].
Elasticsearch provides the More Like This (MLT) query [65] that allows to find similar documents for a given set of documents. This function is used in the system to display related RSS feed items for a search query.
Communication between Elasticsearch and other system components is implemented using the REST API [66] that comes with Elasticsearch.
4 Results
The developed system was tested on approximately 50,000 data sources, including newsletters from popular news sources, as well as rarely updated personal blogs. The system showed good results in terms of performance and data processing speed. On average, new data appears in the search index within 30 seconds of a crawl task appearing.
The proposed data source crawling strategy has also shown to be effective: it was found that the number of sources publishing more than 8 items per day drops sharply as the total number of aggregated sources increases and does not exceed 5%.
The number of sources in the test dataset publishing 3 to 8 articles per day was approximately 14%. Thus, it is expected that the system in production will be focused mainly on processing about 20% of actively updated sources.
The number of workers for processing tasks from message queues in the described system architecture was determined experimentally and is considered sufficient to process 50,000 data sources. If necessary, the system can be easily expanded by adding new workers.
5 Conclusions and future work
In this paper, it has been proposed an RSS feed aggregation system available to process 50,000 feeds. The system consists of the Aggregation Policy module, the Crawling module, the Processing module, each of which has been described in detail. The described aggregation system has been implemented and will be put into production next year.
The system uses a crawling strategy based on an analysis of the frequency of publication of data sources. According to this strategy, the source database is divided into three parts, containing frequently updated data sources, medium updated data sources, and rarely updated sources, with the largest amount of computing resources allocated to the first two groups.
Thanks to this approach, it was possible to increase the frequency of bypassing the most frequently updated RSS feeds, reducing the total number of HTTP requests.
The fault tolerance of the developed system is ensured by the independence of its components and the possibility of adding new nodes.
In the future, the author would like to focus on the analysis of aggregated data and the improvement of the aggregation policy and architecture of the system as a whole.
Библиография
1. IT в России [Электронный ресурс]. URL: https://devsday.ru/ (дата обращения: 07.11.2022).
2. Кирьянов Д. А. Исследование методов построения систем агрегации контента // Программные системы и вычислительные методы. 2022. № 1. URL: https://doi.org/10.7256/2454-0714.2022.1.37341 (дата обращения: 07.11.2022).
3. PostgreSQL: Documentation. Chapter 12. Full Text Search [Электронный ресурс]. URL: https://www.postgresql.org/docs/current/textsearch-intro.html (дата обращения: 07.11.2022).
4. Elasticsearch: The Official Distributed Search & Analytics Engine [Электронный ресурс]. URL: https://www.elastic.co/elasticsearch/ (дата обращения: 07.11.2022).
5. Christopher Olston, Marc Najork. Web Crawling // Foundations and Trends. 2010. №3. URL: http://dx.doi.org/10.1561/1500000017 (дата обращения: 07.11.2022).
6. Shkapenyuk V., Suel T. Design and implementation of a high-performance distributed Web crawler //Proceedings of the 18th International Conference on Data Engineering. San Jose, CA, USA. 2002. URL: https://doi.org/10.1109/ICDE.2002.994750 (дата обращения: 07.11.2022).
7. Horincar R., Amann B., Artières T. Best-Effort Refresh Strategies for Content-Based RSS Feed Aggregation // Web Information Systems Engineering – WISE 2010. URL: https://doi.org/10.1007/978-3-642-17616-6_24 (дата обращения: 07.11.2022).
8. Jordi Creus, Bernd Amann, Nicolas Travers, Dan Vodislav. RoSeS: a continuous query processor for large-scale RSS filtering and aggregation // Proceedings of the 20th ACM international conference on Information and knowledge management (CIKM '11). 2011. URL: https://doi.org/10.1145/2063576.2064016 (дата обращения: 07.11.2022).
9. Korotun O., Vakaliuk T., Oleshko V. Development of a Web-Based System of Automatic Content Retrieval Database. 2020. URL: http://dx.doi.org/10.2139/ssrn.3719834 (дата обращения: 07.11.2022).
10. Hernandez M. A., Stolfo S. J. Real-world Data is Dirty: Data Cleansing and the Merge/Purge Problem // Data Mining and Knowledge Discovery. 1998. URL: http://dx.doi.org/10.1023/A:1009761603038 (дата обращения: 07.11.2022).
11. Chih-Lin Hu, Chung-Kuang Chou. RSS watchdog: an instant event monitor on real online news streams // Proceedings of the 18th ACM conference on Information and knowledge management (CIKM '09). 2009. URL https://doi.org/10.1145/1645953.1646321 (дата обращения: 07.11.2022).
12. Teng Z., Liu Y., Ren F. Create Special Domain News Collections through Summarization and Classification // IEEJ Transactions on Electrical and Electronic Engineering. 2010. URL: https://doi.org/10.1002/TEE.20493 (дата обращения: 07.11.2022).
13. Alaa Mohamed, Marwan Ibrahim, Mayar Yasser, Mohamed Ayman, Menna Gamil, Walaa Hassan. News Aggregator and Efficient Summarization System // International Journal of Advanced Computer Science and Applications(IJACSA). 2020. URL: http://dx.doi.org/10.14569/IJACSA.2020.0110677 (дата обращения: 07.11.2022).
14. Balcerzak B., Jaworski W., Wierzbicki A. Application of textrank algorithm for credibility assessment // 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT). 2014. URL: https://doi.org/10.1109/WI-IAT.2014.70 (дата обращения: 07.11.2022).
15. Paliouras G., Mouzakidis A., Moustakas V., Skourlas C. PNS: A Personalized News Aggregator on the Web // Intelligent Interactive Systems in Knowledge-Based Environments. 2008. URL: https://doi.org/10.1007/978-3-540-77471-6_10 (дата обращения: 07.11.2022).
16. Wanner F., Rohrdantz C., Mansmann F., Oelke D., Keim D. A. Visual Sentiment Analysis of RSS News Feeds Featuring the US Presidential Election in 2008 // Workshop on Visual Interfaces to the Social and the Semantic Web (VISSW2009). 2009. URL: http://ceur-ws.org/Vol-443/paper7.pdf (дата обращения: 07.11.2022).
17. O'Shea M., Levene M. Mining and visualising information from RSS feeds: a case study // International Journal of Web Information Systems. 2011. URL: https://doi.org/10.1108/17440081111141763 (дата обращения: 07.11.2022).
18. What is .NET? Introduction and overview [Электронный ресурс]. URL: https://learn.microsoft.com/en-us/dotnet/core/introduction (дата обращения: 07.11.2022).
19. Sia K. C., Cho J., Cho H. Efficient Monitoring Algorithm for Fast News Alerts // IEEE Transactions on Knowledge and Data Engineering. 2007. URL: https://doi.org/10.1109/TKDE.2007.1041 (дата обращения: 07.11.2022).
20. Roitman H., Carmel D., Yom-Tov E. Maintaining dynamic channel profiles on the web // Proceedings of the VLDB Endowment. 2008. URL: https://doi.org/10.14778/1453856.1453878 (дата обращения: 07.11.2022).
21. Adam G., Bouras C. J., Poulopoulos, V. Efficient extraction of news articles based on RSS crawling // 2010 International Conference on Machine and Web Intelligence. 2010. URL: https://doi.org/10.1109/ICMWI.2010.5647851 (дата обращения: 07.11.2022).
22. Horincar R., Amann B., Artières T. Online refresh strategies for content based feed aggregation // World Wide Web. 2015. URL: https://doi.org/10.1007/s11280-014-0288-y (дата обращения: 07.11.2022).
23. Junghoo Cho, Hector Garcia-Molina. Synchronizing a Database to Improve Freshness // Proceedings of the International Conference on Management of Data (SIGMOD). 2000. URL: http://dx.doi.org/10.1145/342009.335391 (дата обращения: 07.11.2022).
24. Ka Cheung Sia, Junghoo Cho, Hyun-Kyu Cho. Efficient Monitoring Algorithm for Fast News Alert // IEEE Transaction of Knowledge and Data Engineering. 2007. URL: https://doi.org/10.1109/TKDE.2007.1041 (дата обращения: 07.11.2022).
25. Travers N., Hmedeh Z., Vouzoukidou N., du Mouza C., Christophides V., Scholl, M. RSS feeds behavior analysis, structure and vocabulary // International Journal of Web Information Systems. 2014. URL: https://doi.org/10.1108/IJWIS-06-2014-0023 (дата обращения: 07.11.2022).
26. PostgreSQL: The World's Most Advanced Open Source Relational Database [Электронный ресурс]. URL: https://www.postgresql.org (дата обращения: 07.11.2022).
27. Messaging that just works-RabbitMQ [Электронный ресурс]. URL: https://www.rabbitmq.com/ (дата обращения: 07.11.2022).
28. Hong X. J., Sik Yang H., Kim Y. H. Performance Analysis of RESTful API and RabbitMQ for Microservice Web Application // 2018 International Conference on Information and Communication Technology Convergence (ICTC). 2018. URL: https://doi.org/10.1109/ICTC.2018.8539409 (дата обращения: 07.11.2022).
29. Rostanski M., Grochla K., Seman A. Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ // Proc. Of Federated Conference on Computer Science and Information Systems. 2014. URL: http://dx.doi.org/10.15439/978-83-60810-58-3 (дата обращения: 07.11.2022).
30. Ganzha M., Maciaszek L., Paprzycki M. Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ // Proceedings of the 2014 Federated Conference on Computer Science and Information Systems. 2014. URL: http://dx.doi.org/10.15439/2014F48 (дата обращения: 07.11.2022).
31. Competing Consumers pattern [Электронный ресурс]. URL: https://learn.microsoft.com/en-us/azure/architecture/patterns/competing-consumers (дата обращения: 07.11.2022).
32. Competing Consumers [Электронный ресурс]. URL: https://www.enterpriseintegrationpatterns.com/patterns/messaging/CompetingConsumers.html (дата обращения: 07.11.2022).
33. Work Queues (using the .NET Client) [Электронный ресурс]. URL: https://www.rabbitmq.com/tutorials/tutorial-two-dotnet.html (дата обращения: 07.11.2022).
34. Make HTTP requests with the HttpClient class [Электронный ресурс]. URL: https://learn.microsoft.com/en-us/dotnet/fundamentals/networking/http/httpclient (дата обращения: 07.11.2022).
35. SyndicationFeed Class [Электронный ресурс]. URL: https://learn.microsoft.com/en-us/dotnet/api/system.servicemodel.syndication.syndicationfeed (дата обращения: 07.11.2022).
36. Html Agility Pack [Электронный ресурс]. URL: https://html-agility-pack.net/ (дата обращения: 07.11.2022).
37. Robie J., Dyck M., Spiegel J. XML path language (XPath) [Электронный ресурс]. 2017. URL: https://www.w3.org/TR/xpath/ (дата обращения: 07.11.2022).
38. Cebollero M., Natarajan J., Coles, M. XQuery and XPath // Pro T-SQL Programmer's Guide. Apress, Berkeley, CA. 2015. URL: https://doi.org/10.1007/978-1-4842-0145-9_13 (дата обращения: 07.11.2022).
39. Lovins, J. B. Development of a stemming algorithm // Mech. Transl. Comput. Linguistics. 1968. URL: https://aclanthology.org/www.mt-archive.info/MT-1968-Lovins.pdf (дата обращения: 07.11.2022).
40. Jabbar A., Iqbal S., Tamimy M. I. Empirical evaluation and study of text stemming algorithms // Artifcial Intelligence Review. 2020. URL: https://doi.org/10.1007/s10462-020-09828-3 (дата обращения: 07.11.2022).
41. PorterStemmer 1.0.0 [Электронный ресурс]. URL: https://www.nuget.org/packages/PorterStemmer (дата обращения: 07.11.2022).
42. Willett P. The Porter stemming algorithm: then and now // Program: electronic library and information systems. 2006. URL: https://doi.org/10.1108/00330330610681295 (дата обращения: 07.11.2022).
43. Choi J., Jeon C. Cost-Based Heterogeneous Learning Framework for Real-Time Spam Detection in Social Networks with Expert Decisions // IEEE Access. 2021. №9. URL: http://dx.doi.org/10.1109/ACCESS.2021.3098799 (дата обращения: 07.11.2022).
44. Md Khairul Islam, Al Amin, Rakibul Islam. Spam-Detection with Comparative Analysis and Spamming Words Extractions // 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO). 2021. URL: https://doi.org/10.1109/ICRITO51393.2021.9596218 (дата обращения: 07.11.2022).
45. Huiting Zheng, Jiabin Yuan, Long Chen. Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation // Energies. 2017. URL: https://doi.org/10.3390/en10081168 (дата обращения: 07.11.2022).
46. Chih-Hung Wu. Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks // Expert Systems with Applications. 2009. URL: https://doi.org/10.1016/j.eswa.2008.03.002 (дата обращения: 07.11.2022).
47. Koggalahewa D., Xu Y., Foo E. An unsupervised method for social network spammer detection based on user information interests // Journal of Big Data. 2022. URL: https://doi.org/10.1186/s40537-021-00552-5 (дата обращения: 07.11.2022).
48. Rudy Prabowo, Mike Thelwall. A comparison of feature selection methods for an evolving RSS feed corpus // Information Processing & Management. 2006. URL: https://doi.org/10.1016/j.ipm.2006.03.018 (дата обращения: 07.11.2022).
49. Philip J. Hayes, Laura E. Knecht, Monica J. Cellio. A news story categorization system // Proceedings of the second conference on Applied natural language processing (ANLC '88). 1988. URL: https://doi.org/10.3115/974235.974238 (дата обращения: 07.11.2022).
50. Vasantha Kumar V, Sendhilkumar S. Developing a conceptual framework for short text categorization using hybrid CNN-LSTM based Caledonian crow optimization // Expert Systems with Applications. 2023. URL: https://doi.org/10.1016/j.eswa.2022.118517 (дата обращения: 07.11.2022).
51. Christos Bouras, Vassilis Poulopoulos, Vassilis Tsogkas. Adaptation of RSS feeds based on the user profile and on the end device // Journal of Network and Computer Applications. 2010. URL: https://doi.org/10.1016/j.jnca.2010.02.004 (дата обращения: 07.11.2022).
52. Wichert A. A categorical expert system “Jurassic” // Expert Systems with Applications. 2000. URL: https://doi.org/10.1016/S0957-4174(00)00029-4 (дата обращения: 07.11.2022).
53. Carvalho J. P., Rosa H., Brogueira G., Batista F. MISNIS: An intelligent platform for twitter topic mining // Expert Systems with Applications. 2017. URL: https://doi.org/10.1016/j.eswa.2017.08.001 (дата обращения: 07.11.2022).
54. Garrido A., Buey M., Escudero S., Peiro A., Ilarri S., Mena E. The GENIE Project-A Semantic Pipeline for Automatic Document Categorisation // Proceedings of the 10th International Conference on Web Information Systems and Technologies. 2014. URL: https://doi.org/10.5220/0004750601610171 (дата обращения: 07.11.2022).
55. Кирьянов Д. А. Гибридная категориальная экспертная система для использования в агрегации контента // Программные системы и вычислительные методы. 2021. URL: https://doi.org/10.7256/2454-0714.2021.4.37019 (дата обращения: 07.11.2022).
56. Nikolayev S. NRules-Open source rules engine for .NET [Электронный ресурс]. URL: https://nrules.net/ (дата обращения: 07.11.2022).
57. Charles L. Forgy. Rete: A fast algorithm for the many pattern/many object pattern match problem // Artificial Intelligence. 1982. URL: https://doi.org/10.1016/0004-3702 (дата обращения: 07.11.2022).
58. Kun Qu, Ting Gong, Jianfei Shao. Design and Implementation of System Generator Based on Rule Engine // Procedia Computer Science. 2020. URL: https://doi.org/10.1016/j.procs.2020.02.054 (дата обращения: 07.11.2022).
59. Shah N., Willick D., Mago V. A framework for social media data analytics using Elasticsearch and Kibana // Wireless Networks. 2022. URL: https://doi.org/10.1007/s11276-018-01896-2 (дата обращения: 07.11.2022).
60. Cea D., Nin J., Tous R., Torres J., Ayguadé E. Towards the Cloudification of the Social Networks Analytics // Modeling Decisions for Artificial Intelligence. MDAI 2014. Lecture Notes in Computer Science. 2014. URL: https://doi.org/10.1007/978-3-319-12054-6_17 (дата обращения: 07.11.2022).
61. Zhao Yifan, Wang Kuisheng, Chen Lianguo. Design and analysis of intelligent retrieval system for drilling data and completion data based on cloud platform // Journal of Physics: Conference Series. 2020. URL: http://dx.doi.org/10.1088/1742-6596/1607/1/012026 (дата обращения: 07.11.2022).
62. Rosenberg J., Josue Balandrano Coronel, Meiring J., Gray S., Brown T. Leveraging Elasticsearch to Improve Data Discoverability in Science Gateways // Proceedings of the Practice and Experience in Advanced Research Computing on Rise of the Machines (learning) (PEARC '19). 2019. URL: https://doi.org/10.1145/3332186.3332230 (дата обращения: 07.11.2022).
63. Kumar P., Kumar P., Zaidi N., Rathore V.S. Analysis and Comparative Exploration of Elastic Search, MongoDB and Hadoop Big Data Processing // Soft Computing: Theories and Applications. Advances in Intelligent Systems and Computing. 2018. URL: https://doi.org/10.1007/978-981-10-5699-4_57 (дата обращения: 07.11.2022).
64. Josue Balandrano Coronel, Stephen Mock. DesignSafe: Using Elasticsearch to Share and Search Data on a Science Web Portal // Proceedings of the Practice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact (PEARC17). 2017. URL: https://doi.org/10.1145/3093338.3093386 (дата обращения: 07.11.2022).
65. More Like This Query [Электронный ресурс]. URL: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-mlt-query.html (дата обращения: 07.11.2022).
66. REST APIs | Elasticsearch Guide [8.5] [Электронный ресурс]. URL: https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html (дата обращения: 07.11.2022).
References
1. IT in Russia. Retrieved November, 7, 2022, from https://devsday.ru/
2. Kiryanov, D.A. (2022). Research on the methods of creating content aggregation systems. Software systems and computational methods. doi: 10.7256/2454-0714.2022.1.37341
3. PostgreSQL: Documentation. Chapter 12. Full Text Search. Retrieved November, 7, 2022, from https://www.postgresql.org/docs/current/textsearch-intro.html
4. Elasticsearch: The Official Distributed Search & Analytics Engine. Retrieved November, 7, 2022, from https://www.elastic.co/elasticsearch/
5. Olston, C., Najork, C. (2010). Web Crawling. Foundations and Trends. doi: 10.1561/1500000017
6. Shkapenyuk, V., Suel, T. (2002). Design and implementation of a high-performance distributed Web crawler. In Proceedings of the 18th International Conference on Data Engineering. San Jose, CA, USA. doi: 10.1109/ICDE.2002.994750
7. Horincar, R., Amann, B., Artières, T. (2010). Best-Effort Refresh Strategies for Content-Based RSS Feed Aggregation. Web Information Systems Engineering – WISE 2010. doi: 10.1007/978-3-642-17616-6_24
8. Creus, J., Amann, B., Travers, N., Vodislav, D. (2011). RoSeS: a continuous query processor for large-scale RSS filtering and aggregation. In Proceedings of the 20th ACM international conference on Information and knowledge management (CIKM '11). doi: 10.1145/2063576.2064016
9. Korotun, O., Vakaliuk, T., Oleshko, V. (2020). Development of a Web-Based System of Automatic Content Retrieval Database. SSRN. doi: 10.2139/ssrn.3719834
10. Hernandez, M.A., Stolfo, S.J. (1998). Real-world Data is Dirty: Data Cleansing and the Merge/Purge Problem. Data Mining and Knowledge Discovery. doi: 10.1023/A:1009761603038
11. Chih-Lin, Hu, Chung-Kuang, Chou. (2009). RSS watchdog: an instant event monitor on real online news streams. In Proceedings of the 18th ACM conference on Information and knowledge management (CIKM '09). doi: 10.1145/1645953.1646321
12. Teng, Z., Liu, Y., Ren, F. (2010). Create Special Domain News Collections through Summarization and Classification. IEEJ Transactions on Electrical and Electronic Engineering. doi: 10.1002/TEE.20493
13. Alaa Mohamed et al. (2020) News Aggregator and Efficient Summarization System. International Journal of Advanced Computer Science and Applications(IJACSA). doi: 10.14569/IJACSA.2020.0110677
14. Balcerzak, B., Jaworski, W., Wierzbicki, A. (2014). Application of textrank algorithm for credibility assessment. 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT). doi: 10.1109/WI-IAT.2014.70
15. Paliouras, G., Mouzakidis, A., Moustakas, V., Skourlas, C. (2008). PNS: A Personalized News Aggregator on the Web. Intelligent Interactive Systems in Knowledge-Based Environments. doi: 10.1007/978-3-540-77471-6_10
16. Wanner, F., Rohrdantz, C., Mansmann, F., Oelke, D., Keim, D.A. (2009). Visual Sentiment Analysis of RSS News Feeds Featuring the US Presidential Election in 2008. Workshop on Visual Interfaces to the Social and the Semantic Web (VISSW2009). Retrieved November, 7, 2022, from http://ceur-ws.org/Vol-443/paper7.pdf
17. O'Shea M., & Levene M. (2011). Mining and visualising information from RSS feeds: a case study. International Journal of Web Information Systems. doi: 10.1108/17440081111141763
18. What is .NET? Introduction and overview. Retrieved November, 7, 2022, from https://learn.microsoft.com/en-us/dotnet/core/introduction
19. Sia, K.C., Cho, J., Cho, H. (2007). Efficient Monitoring Algorithm for Fast News Alerts. IEEE Transactions on Knowledge and Data Engineering. doi: 10.1109/TKDE.2007.1041
20. Roitman, H., Carmel, D., Yom-Tov, E. (2008). Maintaining dynamic channel profiles on the web. In Proceedings of the VLDB Endowment. doi: 10.14778/1453856.1453878
21. Adam, G., Bouras, C.J., Poulopoulos, V. (2010). Efficient extraction of news articles based on RSS crawling. 2010 International Conference on Machine and Web Intelligence. doi: 10.1109/ICMWI.2010.5647851
22. Horincar, R., Amann, B., Artières, T. (2015). Online refresh strategies for content based feed aggregation. World Wide Web. doi: 10.1007/s11280-014-0288-y
23. Junghoo, Cho, Hector, Garcia-Molina. (2000). Synchronizing a Database to Improve Freshness. In Proceedings of the International Conference on Management of Data (SIGMOD). doi: 10.1145/342009.335391
24. Sia, K.C., et al. (2007). Efficient Monitoring Algorithm for Fast News Alert. IEEE Transaction of Knowledge and Data Engineering. doi: 10.1109/TKDE.2007.1041
25. Travers, N., et al. (2014). RSS feeds behavior analysis, structure and vocabulary. International Journal of Web Information Systems. doi: 10.1108/IJWIS-06-2014-0023
26. PostgreSQL: The World's Most Advanced Open Source Relational Database. Retrieved November, 7, 2022, from https://www.postgresql.org
27. Messaging that just works-RabbitMQ. Retrieved November, 7, 2022, from https://www.rabbitmq.com/
28. Hong, X.J., Sik, Yang, H., Kim Y.H. (2018). Performance Analysis of RESTful API and RabbitMQ for Microservice Web Application. 2018 International Conference on Information and Communication Technology Convergence (ICTC). doi: 10.1109/ICTC.2018.8539409
29. Rostanski, M., Grochla, K., Seman, A. (2014). Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ. In Proc. Of Federated Conference on Computer Science and Information Systems. doi: 10.15439/978-83-60810-58-3
30. Ganzha, M., Maciaszek, L., Paprzycki, M. (2014). Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems. doi: 10.15439/2014F48
31. Competing Consumers pattern. Retrieved November, 7, 2022, from https://learn.microsoft.com/en-us/azure/architecture/patterns/competing-consumers
32. Competing Consumers. Retrieved November, 7, 2022, from https://www.enterpriseintegrationpatterns.com/patterns/messaging/CompetingConsumers.html
33. Work Queues (using the .NET Client). Retrieved November, 7, 2022, from: https://www.rabbitmq.com/tutorials/tutorial-two-dotnet.html
34. Make HTTP requests with the HttpClient class. Retrieved November, 7, 2022, from https://learn.microsoft.com/en-us/dotnet/fundamentals/networking/http/httpclient
35. SyndicationFeed Class. Retrieved November, 7, 2022, from https://learn.microsoft.com/en-us/dotnet/api/system.servicemodel.syndication.syndicationfeed
36. Html Agility Pack. Retrieved November, 7, 2022, from https://html-agility-pack.net/
37. Robie, J., Dyck, M., Spiegel, J. XML path language (XPath). (2017). Retrieved November, 7, 2022, from https://www.w3.org/TR/xpath/
38. Cebollero, M., Natarajan, J., Coles, M. (2015). XQuery and XPath. Pro T-SQL Programmer's Guide. Apress, Berkeley, CA. doi: 10.1007/978-1-4842-0145-9_13
39. Lovins, J.B. (1968). Development of a stemming algorithm. Mech. Transl. Comput. Linguistics. Retrieved November, 7, 2022, from https://aclanthology.org/www.mt-archive.info/MT-1968-Lovins.pdf
40. Jabbar, A., Iqbal, S., Tamimy, M.I. (2020). Empirical evaluation and study of text stemming algorithms. Artifcial Intelligence Review. doi: 10.1007/s10462-020-09828-3
41. PorterStemmer 1.0.0. Retrieved November, 7, 2022, from https://www.nuget.org/packages/PorterStemmer
42. Willett, P. (2006). The Porter stemming algorithm: then and now. Program: electronic library and information systems. doi: 10.1108/00330330610681295
43. Choi, J., Jeon, C. (2021). Cost-Based Heterogeneous Learning Framework for Real-Time Spam Detection in Social Networks with Expert Decision. IEEE Access. doi: 10.1109/ACCESS.2021.3098799
44. Islam, M.K., et al. (2021). Spam-Detection with Comparative Analysis and Spamming Words Extractions. 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO). doi: 10.1109/ICRITO51393.2021.9596218
45. Zheng, H., Yuan, J., Chen, L. (2017). Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation. Energies. doi: 10.3390/en10081168
46. Chih-Hung, Wu. (2009). Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks. Expert Systems with Applications. doi: 10.1016/j.eswa.2008.03.002
47. Koggalahewa, D., Xu, Y., Foo, E. (2022). An unsupervised method for social network spammer detection based on user information interests. Journal of Big Data. doi: 1186/s40537-021-00552-5
48. Prabowo, R., & Thelwall, M. (2006). A comparison of feature selection methods for an evolving RSS feed corpus. Information Processing & Management. doi: 10.1016/j.ipm.2006.03.018
49. Hayes, P.J., Knecht, L.E., Cellio, M.J. (1988). A news story categorization system. In Proceedings of the second conference on Applied natural language processing (ANLC '88). 1988. doi: 10.3115/974235.974238
50. Vasantha, Kumar, V., Sendhilkumar, S. (2023). Developing a conceptual framework for short text categorization using hybrid CNN-LSTM based Caledonian crow optimization. Expert Systems with Applications. doi: 10.1016/j.eswa.2022.118517
51. Bouras, C., Poulopoulos, V., Tsogkas, V. (2010). Adaptation of RSS feeds based on the user profile and on the end device. Journal of Network and Computer Applications. doi: 10.1016/j.jnca.2010.02.004
52. Wichert, A. (2000). A categorical expert system “Jurassic”. Expert Systems with Applications. doi: 10.1016/S0957-4174(00)00029-4
53. Carvalho, J.P., Rosa, H., Brogueira, G., Batista, F. (2017). MISNIS: An intelligent platform for twitter topic mining. Expert Systems with Applications. doi: 10.1016/j.eswa.2017.08.001
54. Garrido, A., Buey, M., Escudero, S., Peiro, A., Ilarri, S., Mena, E. (2014). The GENIE Project-A Semantic Pipeline for Automatic Document Categorisation. In Proceedings of the 10th International Conference on Web Information Systems and Technologies. doi: 10.5220/0004750601610171
55. Kiryanov, D.A. (2021). Hybrid categorical expert system for use in content aggregation. Software systems and computational methods. doi: 10.7256/2454-0714.2021.4.37019
56. Nikolayev, S. NRules-Open source rules engine for .NET. Retrieved November, 7, 2022, from https://nrules.net/
57. Forgy, C.L. (1982). Rete: A fast algorithm for the many pattern/many object pattern match problem. Artificial Intelligence. doi: 10.1016/0004-3702
58. Qu, Kun & Gong, Ting & Shao, Jianfei. (2020). Design and Implementation of System Generator Based on Rule Engine. Procedia Computer Science. 166. 517-522. doi: 10.1016/j.procs.2020.02.054
59. Shah, N., Willick, D., Mago, V. (2022). A framework for social media data analytics using Elasticsearch and Kibana. Wireless Networks. doi: 10.1007/s11276-018-01896-2
60. Cea, D., Nin, J., Tous, R., Torres, J., Ayguadé, E. (2014). Towards the Cloudification of the Social Networks Analytics. Modeling Decisions for Artificial Intelligence. MDAI 2014. Lecture Notes in Computer Science. doi: 10.1007/978-3-319-12054-6_17
61. Zhao, Yifan & Wang, Kuisheng & Chen, Lianguo. (2020). Design and analysis of intelligent retrieval system for drilling data and completion data based on cloud platform. Journal of Physics: Conference Series. doi: 10.1088/1742-6596/1607/1/012026
62. Rosenberg, J., et al. (2019). Leveraging Elasticsearch to Improve Data Discoverability in Science Gateways. In Proceedings of the Practice and Experience in Advanced Research Computing on Rise of the Machines (learning) (PEARC '19). doi: 10.1145/3332186.3332230
63. Kumar, P., Kumar, P., Zaidi, N., Rathore, V.S. (2018). Analysis and Comparative Exploration of Elastic Search, MongoDB and Hadoop Big Data Processing. Soft Computing: Theories and Applications. Advances in Intelligent Systems and Computing. doi: 10.1007/978-981-10-5699-4_57
64. Coronel, J.S., & Mock, S. (2017). DesignSafe: Using Elasticsearch to Share and Search Data on a Science Web Portal. In Proceedings of the Practice and Experience in Advanced Research Computing 2017 on Sustainability, Success and Impact (PEARC17). doi: 10.1145/3093338.3093386
65. More Like This Query. Retrieved November, 7, 2022, from https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-mlt-query.html
66. REST APIs | Elasticsearch Guide [8.5]. Retrieved November, 7, 2022, from https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.htm
Результаты процедуры рецензирования статьи
Рецензия скрыта по просьбе автора
|
 Рус
Рус









