|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Плешакова Е.С., Гатауллин С.Т., Осипов А.В., Романова Е.В., Марунько А.С.
Применение методов тематического моделирования в задачах распознавания темы текста для обнаружения телефонного мошенничества
// Программные системы и вычислительные методы.
2022. № 3.
С. 14-27.
DOI: 10.7256/2454-0714.2022.3.38770 EDN: RPLSLQ URL: https://nbpublish.com/library_read_article.php?id=38770
Применение методов тематического моделирования в задачах распознавания темы текста для обнаружения телефонного мошенничества
Плешакова Екатерина Сергеевна
ORCID: 0000-0002-8806-1478
кандидат технических наук
доцент, кафедра Информационной безопасности, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, пр-д 4-Й вешняковский, 12к2, корпус 2
Pleshakova Ekaterina Sergeevna
PhD in Technical Science
Associate Professor, Department of Information Security, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th Veshnyakovsky Ave., 12k2, building 2

|
espleshakova@fa.ru
|
|
 |
Другие публикации этого автора
|
|
Гатауллин Сергей Тимурович
кандидат экономических наук
декан факультета «Цифровая экономика и массовые коммуникации» Московского технического университета связи и информатики; ведущий научный сотрудник Департамента информационной безопасности Финансового университета при Правительстве РФ
111024, Россия, г. Москва, ул. Авиамоторная, 8А
Gataullin Sergei Timurovich
PhD in Economics
Dean of "Digital Economy and Mass Communications" Department of the Moscow Technical University of Communications and Informatics; Leading Researcher of the Department of Information Security of the Financial University under the Government of the Russian Federation
8A Aviamotornaya str., Moscow, 111024, Russia
|
|
stgataullin@fa.ru
|
|
|
Другие публикации этого автора
|
|
Осипов Алексей Викторович
кандидат физико-математических наук
доцент, Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, ул. 4-Й вешняковский, 4, корпус 2
Osipov Aleksei Viktorovich
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th veshnyakovsky str., 4, building 2
|
|
avosipov@fa.ru
|
|
|
Другие публикации этого автора
|
|
Романова Екатерина Владимировна
кандидат физико-математических наук
доцент, кафедра Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Москва, пр-кт Ленинградский, 49/2
Romanova Ekaterina Vladimirovna
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.
|
|
EkVRomanova@fa.ru
|
|
|
Другие публикации этого автора
|
|
|
Марунько Анна Сергеевна
студент, кафедра Департамент анализа данных и машинного обучения, Финансовый университет при Правительстве Российской Федерации
125167, Россия, г. Moskow, ул. Leningradskiy Prospect, 49/2
Marun'ko Anna Sergeevna
Student, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
49/2 Leningradskiy Prospect str., Moscow, 125167, Russia
|
|
marunko94@gmail.com
|
|
|
|
DOI: 10.7256/2454-0714.2022.3.38770
EDN: RPLSLQ
Дата направления статьи в редакцию:
09-09-2022
Дата публикации:
16-09-2022
Аннотация:
Интернет возник как мощная инфраструктура для всемирной коммуникации и взаимодействия людей. Некоторое неэтичное использование этой технологии спам, фишинг, тролли, киберзапугивание, вирусы вызвало проблемы при разработке механизмов, гарантирующих доступные и безопасные возможности ее использования. В настоящее время проводится множество исследований обнаружения спама, фишинга. Выявление телефонного мошенничества стало критически важным, поскольку влечет огромные потери. Алгоритмы машинного обучения и обработки естественного языка используются для анализа огромного количества текстовых данных. Выявление мошенников производится с применением интеллектуального анализа текста и может быть реализовано путем анализа терминов слова или фразы. Одной из сложных задач является разделение этих огромных неструктурированных данных на кластеры. Для этих целей существует несколько моделей тематического моделирования. В данной статье представлено применение этих моделей, в частности LDA, LSI и NMF. Сформирован набор данных. Проведен предварительный анализ данных и построены признаки для моделей в задаче по распознаванию темы текста. Рассмотрены подходы извлечения ключевых фраз в задачах распознавания темы текста. Приведены ключевые понятия этих подходов. Показаны недостатки этих моделей, предложены направления по улучшению алгоритмов обработки текстов. Проведена оценки качества моделей. Усовершенствованы модели благодаря подбору гиперпараметра и изменению функции предобработки данных.
Ключевые слова:
обработка естественного языка, информационная безопасность, машинное обучение, анализ текста, LDA, LSI, NMF, тематическое моделирование, телефонное мошенничество, фишинг
Abstract: The Internet has emerged as a powerful infrastructure for worldwide communication and human interaction. Some unethical use of this technology spam, phishing, trolls, cyberbullying, viruses caused problems in the development of mechanisms that guarantee affordable and safe opportunities for its use. Currently, many studies are being conducted to detect spam and phishing. The detection of telephone fraud has become critically important, as it entails huge losses. Machine learning and natural language processing algorithms are used to analyze a huge amount of text data. Fraudsters are identified using text mining and can be implemented by analyzing the terms of a word or phrase. One of the difficult tasks is to divide this huge unstructured data into clusters. There are several thematic modeling models for these purposes. This article presents the application of these models, in particular LDA, LSI and NMF. A data set has been formed. A preliminary analysis of the data was carried out and signs were constructed for models in the task of recognizing the subject of the text. The approaches of keyword extraction in the tasks of text topic recognition are considered. The key concepts of these approaches are given. The disadvantages of these models are shown, and directions for improving text processing algorithms are proposed. The evaluation of the quality of the models was carried out. Improved models thanks to the selection of hyperparameters and changing the data preprocessing function.
Keywords: natural language processing, information security, machine learning, text analysis, LDA, LSI, NMF, thematic modeling, phone fraud, phishing
Статья подготовлена в рамках государственного задания Правительства Российской Федерации Финансовому университету на 2022 год по теме «Модели и методы распознавания текстов в системах противодействия телефонному мошенничеству» (ВТК-ГЗ-ПИ-30-2022).
Введение
Интеллектуальный анализ текста может быть реализован путем анализа терминов слова или фразы. NLP (Natural Language Processing) позволяет решать такие задачи как распознавание текста, распознавание конфиденциального или спам сообщения, распознавание тем, классификация документов. Анализ помогает обработать текстовые данные в бизнес-аналитике или изучить впечатления людей о бренде в маркетинге на основе постов в социальных сетях, а также для обнаружения фишинга. Фишинг является наиболее распространенных атакой, при которой пытаются украсть конфиденциальную информацию, выдавая себя за законный источник. Используемым методом фишинга являются фишинговые электронные письма. Для решения этой проблемы могут быть использованы методы обработки естественного языка и машинного обучения. Практическая значимость обучения моделей распознавать смысл текста заключается в создании основы для дальнейшего, более глубокого анализа.
Естественный язык, как правило, структурирован и имеет свои правила: грамматика, синтаксис, семантика (то, как слова со своими значениями формируют предложения, у которых тоже есть свои значения) [2,3].
Распознавание темы текста – это классификация или его обобщение. Когда тексту присваивается тема, сначала его необходимо сократить и вынести из него главный смысл. Тогда будет возможно отнести его к какой-либо тематике [4]. Мы использовали модели обобщения текста для распознавания его темы, так как задача распознавания темы текста предполагает не только обыкновенную классификацию, но и исследование паттернов (шаблонов). Более того, исследования паттернов и классические модели обобщения текста позволяют воспользоваться обучением без учителя.
Корпус текстов является векторным пространством, где каждый текст – это отдельный вектор. При этом измерения каждого вектора – это число уникальных слов и/или фраз во всём векторном пространстве. Наполнение вектора – веса терминов в тексте. Данная концепция, в основном, используется в каждом способе построения признаков из текстовых данных, а различает их то, как определяются слова/фразы и их веса [5].
Для определения темы текста или его сокращения есть мы будем использовать такие концепции как извлечение ключевых фраз и моделирование тем.
Создание набора данных и его предобработка
Набор данных, который мы сформировали для обучения и тестирования, получен с сайта проекта Project Gutenberg. Представляет собой разнообразные сборники сказок разных народов мира. Каждая книга была представлена единым файлом, но для моделей семейства Topic modeling (Моделирование тем) необходимо иметь набор данных из множества файлов. То есть, каждая сказка должна быть в отдельном файле. Чтобы разделить около 50 книг на отдельные файлы, была построена специальная функция с помощью регулярных выражений. Функция включает в себя разбивку текстов на файлы, а также очистку от «выбросов».
Таким образом, получился набор данных из 1651 сказки, с которым можно более подробно ознакомиться по ссылке: https://github.com/AnnBengardt/Course_paper_ML/tree/main/Dataset.
После создания набора данных необходимо выполнить его предобработку для дальнейшего построения корпуса и моделей. Предобработка включает в себя: удаление букв не из английского алфавита (Æ, Œ, Ö, Å и т. д.), очистка от html-тэгов, от специальных символов (~, *, $ и т. д.), от соединений (I'm, he'll, we'd и т. д.), от повторов символов, от английских стоп-слов, от чисел. Также будет проведена лемматизация слов.
Реализация извлечения ключевых фраз (Keyphrases Extraction)
В извлечении ключевых фраз есть два подхода. Первый – Collocation (Словосочетание) – работает на основе N-грамм [6-8]. Идея заключается в том, что необходимо построить корпус, где каждый документ – это часть одного текста, абзац или предложение. Далее, с помощью токенизации корпус трансформируется в одно большое предложение, по которому алгоритм, можно сказать, «прокатывается», рассматривая каждую N-грамму и подсчитывая либо просто частоту повторений, либо PMI (Pointwise Mutual Information – Поточечная взаимная информация) по формуле (1):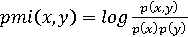 (1) (1)
Где p – это вероятность возникновения термина или двух терминов вместе.
После подсчёта одной из метрик алгоритм сортирует их, тогда можно вывести и проанализировать самые релевантные и нерелевантные N-граммы.
Второй подход извлечения ключевых фраз – взвешенное извлечение фраз на основе тэгов (Weighted tag-based phrase extraction). Сначала алгоритм извлекает все фразы с существительными с помощью тэгов частей речи (Part of Speech tags), это часто встречающийся инструмент в NLP. Далее, к полученным выдержкам из текста применяется модель TF-IDF. Соответственно, самые релевантные фразы – те, которые имеют самые высокие веса в полученной матрице.
Collocations хорошо реализован в библиотеке NLTK в виде BigramCollocationFinder и TrigramCollocationFinder для поиска словосочетаний из двух и, соответственно, трёх слов. Для подсчёта подходящих фраз воспользуемся способом обычных частот (raw frequency).
Реализуем CollocationFinder как к полному набору данных, так и только к первым пяти.

Рисунок 1. Биграммы и триграммы для всех и первых пяти текстов
В результате мы видим, какие биграммы и триграммы являются самыми часто встречаемыми для всех данных (первая строка). В первом случае это довольно общие фразы, которые мало о чём могут сообщить: old man, next day, upon time lived, early next morning. Однако, во втором случае можно уже проследить имена главных героев: Earl St. Clair, Robin Redbreast, Elfin King. Также видна тема про рождество северных народов: cold winters day, Merry Yule (Рождество в Скандинавии).
Реализуем взвешенное извлечение фраз на основе тэгов. Функция keywords из genism.summarization создаёт результат для каждой сказки, у всех слов и фраз имеется свой вес, определяющий их значимость в тексте.

Рисунок 2. Результат взвешенного извлечения фраз на основе тэгов
В целом, извлечение ключевых фраз помогает представить, о чём идёт речь в некоторых текстах. Однако этого недостаточно, чтобы сделать окончательные выводы, особенно если нет понимания контекста. Следовательно, обратимся к более подходящему для задачи семейству моделей – Topic Modeling.
Построение признаков для моделирования тем
Была использована библиотека Gensim, созданной специально для решения задач распознавания тем текста с помощью машинного обучения без учителя [9-11]. Каждая модель в Gensim использует разные способы векторизации текста и построения признаков из полученного векторного пространства, но в то же время каждой модели достаточно получить представление текстового корпуса в виде мешка слов (Bag of words) и словаря соответствий (пары индекс – слово). Таким образом, для моделирования достаточно лишь преобразовать набор текстов в мешок слов.
Ради повышения эффективности будущих моделей перед преобразованием в общем лексиконе корпуса были выделены биграммы моделью Phrases.

Рисунок 3. Результат работы модели Gensim Phrases
На рисунке 3 можно заметить, что некоторые слова слились в биграммы через нижнее подчёркивание: seven_year, shake_head.
Далее, с помощью gensim.corpora.Dictionary был создан словарь со всеми уникальными словами, которые используются в корпусе, и их индексами. Изначально словарь состоит из 25 743 слов, что избыточно для поиска отдельных тем и может, напротив, ухудшить модели. Чтобы успешно выполнить поставленную задачу, необходимо избавиться от выбросов.
Изначально были выбраны условия удалить слова, встретившиеся по всему набору данных менее 20 раз, а также те слова, которые появились в более 60% текстов. После нескольких итераций выяснилось, что более эффективный набор лексикона получается при параметрах 15 раз и 75%.
По окончанию очистки длина словаря составила 4963 слова, и теперь из него можно создать мешок слов. Для этого у объекта dictionary тоже есть функция – doc2bow. Таким образом каждый текст в корпусе векторизуется на основе общего словаря.
Построение моделей: LSI, LDA, NMF Моделирование тем (Topic Modeling) это большое семейство моделей, в данной работе для решения поставленной задачи будут использованы три разновидности: латентно-семантическое индексирование (LSI), латентное размещение Дирихле (LDA), неотрицательное матричное разложение (NMF) [12].
Главный принцип модели LSI похожие слова и фразы используются в одинаковом контексте и, поэтому, часто встречаются вместе. Таким образом можно обнаружить термины, которые коррелируют друг с другом и тем самым создают тематику текста [13].
Алгоритм LSI основан на сингулярном разложении. Это алгебраическая концепция, используемая в том числе и для обобщения текста. Сингулярное разложение позволяет представить исходную матрицу M в таком виде, что (2):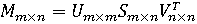 (2) (2)
Где:
U – это такая унитарная матрица размерностью m x m, что UTU = Imxm. При этом I – это единичная матрица, а столбцы U показывают левые сингулярные векторы.
S – диагональная матрица m x n с положительными вещественными числами на диагонали. Также может быть представлена вектором размерностью m, в котором находятся сингулярные значения.
VT – это такая унитарная матрица n x n, что VTV = Inxn. При этом I – это единичная матрица, а ряды V показывают правые сингулярные векторы.
В LSI сингулярное разложение прежде всего используется для примерного определения ранга матрицы, когда идёт определение исходной матрицы M от матрицы M^. M^ в свою очередь – это обрезанная часть исходной матрицы с рангом k и может быть определена сингулярным разложением как:
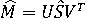 (3) (3)
Где S^ — это обрезанная часть исходной матрицы S, состоящая теперь из k самых больших значений матрицы S.
На сегодняшний день модель LDA является самой популярной и хорошо изученной моделью во многих областях и многочисленных наборах инструментов, таких как Machine Learning for Language Toolkit (MALLET). LDA напоминает LSI в том, что оба подхода предполагают, что один текстовый документ находится под влиянием сразу нескольких тем с разными вероятностями. Однако в случае с LDA эти вероятности находятся под влиянием размещения Дирихле для лучшего обобщения данных. Размещение Дирихле можно назвать «распределением распределений» [14]. По окончании алгоритма получаются распределения тем для каждого текста, с помощью которых можно выявить ключевые составляющие слова для каждой тематики.
NMF — это метод матричной факторизации (линейной алгебры) без учителя, который позволяет одновременно выполнять как уменьшение размерности, так и кластеризацию. NMF оперирует лишь над неотрицательными матрицами. Получив неотрицательную матрицу V на вход, которая, как правило, является построенным для моделирования признаком, NMF ищет такие матрицы W и H, чтобы их произведение примерно воспроизводило исходную матрицу V. Также для получения лучших результатов примерного восстановления матрицы V применяется нормализация (L2 или Евклидова норма).
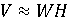 (4) (4)
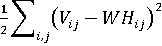 (5) (5)
Реализации всех выбранных моделей самостоятельно строят и используют необходимые им признаки. Так, например, LDA использует сугубо обычную частоту терминов и Мешок слов, а LSI – TF-IDF. Вследствие этого для последующего моделирования этих трёх подходов необходимо создать лишь Мешок слов. Автоматизированные модели впоследствии сами трансформируют его в необходимые признаки.
Для оценки качества моделей в данной работе будет использована отдельная модель – Coherence Model (Модель Согласованности). Она оценивает несколько метрик моделирования через «конвейер»: сегментация (деление слов в текстах на пары для подсчёта оценки); подсчёт вероятностей (так же, как и в PMI, вычисляются вероятности возникновения каждого слова и пар слов вместе); измерение подтверждения (с помощью полученных вероятностей идёт расчёт оценки, насколько хорошо слово А из пары АБ поддерживает слово Б и наоборот). Далее, все значения агрегируются в одно через математическую функцию и получается конечная оценка согласованности (Coherence Score).
Более того, существуют несколько вариантов подсчёта оценки, реализованные в Модели согласованности. В данной работе будут использованы методы «UMass» и «CV» для сравнения и оценки результатов моделирования.
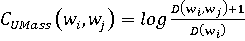 (6) (6)
Где D(wi, wj) – сколько раз эта пара слов появилась вместе, D(wi) – сколько раз это слово появилось одно [8].
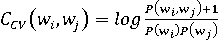 (7) (7)
Где P(w) – вероятность увидеть слово в контекстном окне, P(wi, wj) – вероятность увидеть два слова вместе в контекстном окне.
Модель Gensim LSI (Латентно-семантическое индексирование) строится на основе мешка слов и словаря, но внутри мешок слов преобразовывается в матрицу TF-IDF. Рисунок 4 демонстрирует один из способов визуализации полученных тем: так как в модели LSI подразумевается, что слова можно распределить на два направления, которые ведут к разным темам, то веса могут быть и положительными, и отрицательными.

Рисунок 4. Результат построения модели LSI
Для оценки моделей будут использованы метрики согласованности тем (Topic coherence). В Gensim они все реализованы в виде отдельной модели – Coherence Model. Рассчитав метрики CV и UMass, получаем результат:
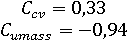
Латентное размещение Дирихле (LDA) работает именно с мешком слов, никак не преобразовывая в дальнейшем этот признак. Также модель вновь требует словарь и два параметра для распределения – alpha, eta. Они будут заданы как auto. Результатом модели тоже являются темы в заданном раннее количестве, но без деления на направления, то есть все веса положительные (рис. 5).

Рисунок 5. Результат построения модели LDA
Оценка модели несколько ниже, чем в случае с LSI:
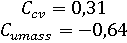
Неотрицательное матричное разложение (NMF), как и модели выше, построена на словаре и мешке слов. Полученные темы с принадлежащими им фразами и словами представлены на рисунке 6 (результат представлен без весов, но, как и в случае с LDA, здесь они только положительные).

Рисунок 6. Результат построения модели NMF
Оценка модели:
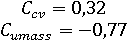
Подбор гиперпараметра и выбор лучшей модели
В первой итерации получились не самые удовлетворительные результаты. Необходимо максимизировать используемые метрики и выяснить, какое количество тем подходит для каждой модели, а затем выбрать лучшую из них для предсказания тем текстов на тестовой выборке.
Для каждого вида модели были реализованы отдельные функции для их многократного построения и сбора статистики метрик в зависимости от количества тем, на которые делится набор текстов. Будет рассмотрен вариант, что в корпусе присутствуют от 5 до 25 отдельных тем.
Полученный результат представлен на рисунке 7-9: все графики получились разнообразными, при этом LDA и NMF примерно сходятся в результатах, сколько должно быть раздельных тем (19 и 14), а LSI предоставила совсем иной ответ (6 тем).
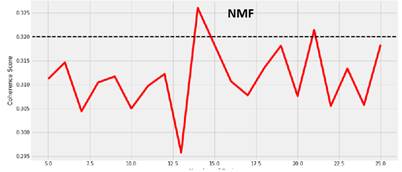
Рисунок 7. Графики метрик для модели NMF
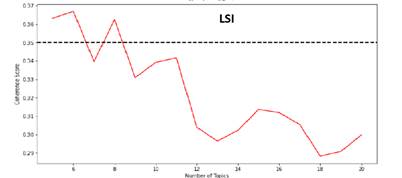
Рисунок 8. Графики метрик для модели LSI
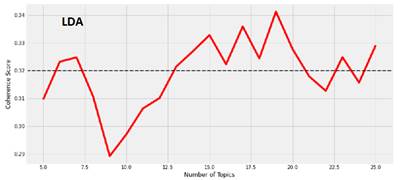
Рисунок 9. Графики метрик для модели LDA
Итак, лучшими моделями можно выбрать LSI с 6 темами (CCV = 0.3669) и LDA c 19 темами (CCV = 0.3412).
Интерпретация результатов моделирования
Интерпретируем результаты двух выбранных лучших моделей и проверить, какое из двух исконно противоположных предположений окажется более подходящим.
Один из возможных путей наглядно показать то, как текстовый корпус был разделён в разных моделях, — это таблица распределения тем по текстам.

Рисунок 10. Таблица распределения тем по текстам для модели LSI
На основе результатов, продемонстрированных на рисунке 10, делаем вывод, что несмотря на лучшие показатели метрик по сравнению с другими моделями, почти все тексты попали в одну категорию. Данная таблица говорит о том, что, скорее всего, выборка нуждается в улучшении: больше файлов с более разнообразным наполнением. Более того, по описаниям тем видно, что остались слова, засоряющие корпус. Это могло произойти в том числе из-за того, что некоторые сказки написаны в старой стилистике, которую не учитывает модуль stopwords, поэтому такие слова, как «thee», «thy», «sayth», не были удалены.
Несмотря на неудовлетворительный результат модели LSI, следует проверить итоги построения модели LDA с разделением на 19 тем.

Рисунок 11. Таблица распределения тем по текстам для модели LDA
В этот раз видна совершенно другая картина: документы почти равномерно распределены по тематикам, лишь несколько из которых выделяются. При этом невооружённым глазом по столбцу с описаниями можно определить наполнения всех этих выделенных тем. Так, например, темы №3 и №10 явно сформировались от скандинавских мифов: giant, Thor, Loki, Odin, Asgard, bear, monster. Темы №15 и №16 объединяют русские сказки: tsar, Ivan, serpent, Baba Yaga. Тема №12 повествует о море и обо всём, что с ним связано: sea, fish, fisherman, ship, water, sail и так далее.
Данная модель LDA, хоть и с несколько меньшим значением метрик, показала гораздо более удачные результаты. По таблице распределения темы действительно видны, теперь попробуем визуализировать её более наглядно с помощью интертопической карты дистанций (Intertopic Distance Map).
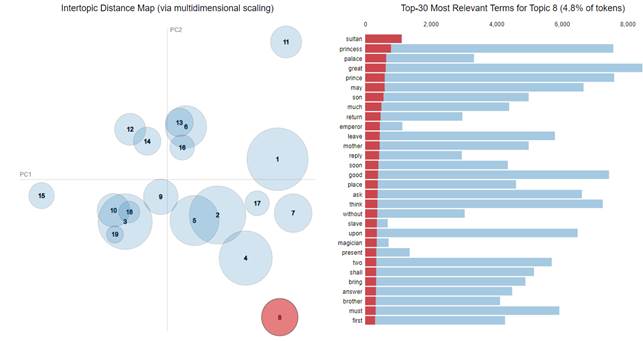
Рисунок 12. Интертопическая карта дистанций
Каждая тема представлена на карте кружком – чем больше его размер, тем больше слов из словаря входит в эту тему. Также справа представлены 30 самых подходящих к этой теме терминов. Красный цвет показывает предсказанную частоту термина для выбранной темы, синий – частота термина по всему корпусу. Если для слова шкала полностью закрашена красным, то оно полностью принадлежит теме, как и представлено на рисунке 12: слово sultan встречается только в теме №8 (арабские сказки). Более того, на самой карте можно наблюдать, насколько темы удалены друг от друга. В данном случае есть примеры полного поглощения: темы №18 и №19 являются подразделами темы №3.
Рационально будет выбрать модель LDA с 19 темами для распознавания тем текстов из тестового набора. Таблица для отображения результатов будет показывать две доминирующих тематики для каждого текста.

Рисунок 13. Таблица распознанных тем текстов из тестовой выборки
На рисунке 13 отчётливо видны северные мифы, рассказы про животных, про королей и путешествия.
Полностью с программной реализацией данной работы можно ознакомиться в открытом репозитории по ссылке: https://github.com/AnnBengardt/Course_paper_ML.
Заключение
Интеллектуальный анализ текста является важной задачей в различных направлениях. Интернет перенасыщен информацией и знаниями, которые могут запутать пользователей и заставить их тратить дополнительное время на поиск подходящей информации по конкретным темам. И наоборот, необходимость анализа коротких текстов стала более актуальной по мере роста популярности микроблогов. Проблема распознавания тем из текста связана с тем, что он содержит относительно небольшие объемы и зашумленные данные, которые могут привести к неточному распознаванию темы. Тематическое моделирование может решить эту проблему, поскольку считается мощным методом, который может помочь в обнаружении и анализе контента. Тематическое моделирование, область интеллектуального анализа текста, используется для обнаружения скрытых шаблонов. Тематическое моделирование и кластеризация документов два важных ключевых термина, схожих по концепциям и функциям. В этой статье тематическое моделирование выполняется с использованием методов LSI, LDA, NMF. В работе было исследовано применение моделей для обработки естественного языка LSI, LDA, NMF. Для наглядности мы сформировали набор данных состоящий из различных текстов. Данные методы показали разные результаты. Для выбора лучшей проведена максимизация метрик. Что позволило выделить две модели LSI и LDA. Экспериментальные результаты показывают, что после улучшении выборки модель LDA показала гораздо более удачные результаты. На основе полученных результатов можно проводить более углубленный анализ текста. Данная работа позволила определить наилучшую модель для распознавания темы и может быть оптимизирована для решения различных задач. В том числе данный метод можно применить для обнаружения фишинговых электронных писем.
Библиография
1. C. Chen, K. Wu, V. Srinivasan, X. Zhang. Battling the Internet Water Army: Detection of Hidden Paid Posters. http://arxiv.org/pdf/1111.4297v1.pdf, 18 Nov 2011
2. D. Yin, Z. Xue, L. Hong, B. Davison, A. Kontostathis, and L. Edwards. Detection of harassment on web 2.0. Proceedings of the Content аnalysis in the Web, 2, 2009
3. T. Kohonen. Self-organization and associative memory. 2d ed. New-York, Springer-Verlag, 1988
4. Y. Niu, Y. min Wang, H. Chen, M. Ma, and F. Hsu. A quantitative study of forum spamming using contextbased analysis. In In Proc. Network and Distributed System Security (NDSS) Symposium, 2007
5. В.В. Киселёв. Автоматическое определение эмоций по речи. Образовательные технологии. №3, 2012, стр. 85-89
6. Р.А. Внебрачных. Троллинг как форма социальной агрессии в виртуальных сообществах. Вестник Удмуртского университета, 2012, Вып.1, стр. 48-51
7. С.В. Болтаева, Т.В. Матвеева. Лексические ритмы в тексте внушения. Русское слово в языке, тексте и культурной среде. Екатеринбург, 1997, стр. 175-185
8. Gamova, A. A., Horoshiy, A. A., & Ivanenko, V. G. (2020, January). Detection of fake and provokative comments in social network using machine learning. In 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus) (pp. 309-311). IEEE.
9. Mei, B., Xiao, Y., Li, H., Cheng, X., & Sun, Y. (2017, October). Inference attacks based on neural networks in social networks. In Proceedings of the fifth ACM/IEEE Workshop on Hot Topics in Web Systems and Technologies (pp. 1-6).
10. Cable, J., & Hugh, G. (2019). Bots in the Net: Applying Machine Learning to Identify Social Media Trolls.
11. Machová K., Porezaný M., Hreškova M. Algorithms of Machine Learning in Recognition of Trolls in Online Space //2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). – IEEE, 2021. – С. 000349-000354.
12. Τσανταρλιώτης Π. Identification of troll vulnerable tergets in online social networks. – 2016.
13. Mihaylov, T., Mihaylova, T., Nakov, P., Màrquez, L., Georgiev, G. D., & Koychev, I. K. (2018). The dark side of news community forums: Opinion manipulation trolls. Internet Research.
14. Zhukov D., Perova J. A Model for Analyzing User Moods of Self-organizing Social Network Structures Based on Graph Theory and the Use of Neural Networks //2021 3rd International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency (SUMMA). – IEEE, 2021. – С. 319-322.
References
1. C. Chen, K. Wu, V. Srinivasan, X. Zhang. Battling the Internet Water Army: Detection of Hidden Paid Posters. http://arxiv.org/pdf/1111.4297v1.pdf, 18 Nov 2011
2. D. Yin, Z. Xue, L. Hong, B. Davison, A. Kontostathis, and L. Edwards. Detection of harassment on web 2.0. Proceedings of the Content analysis in the Web, 2, 2009
3. T. Kohonen. Self-organization and associative memory. 2d ed. New York, Springer Verlag, 1988
4. Y. Niu, Y. min Wang, H. Chen, M. Ma, and F. Hsu. A quantitative study of forum spamming using context-based analysis. In In Proc. Network and Distributed System Security (NDSS) Symposium, 2007
5. V.V. Kiselev. Automatic detection of emotions by speech. Educational technologies. No. 3, 2012, pp. 85-89
6. R.A. Extramarital. Trolling as a form of social aggression in virtual communities. Bulletin of the Udmurt University, 2012, Issue 1, pp. 48-51
7. S.V. Boltaeva, T.V. Matveev. Lexical rhythms in the text of suggestion. Russian word in language, text and cultural environment. Yekaterinburg, 1997, pp. 175-185
8. Gamova, A. A., Horoshiy, A. A., & Ivanenko, V. G. (2020, January). Detection of fake and provocative comments in social network using machine learning. In 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus) (pp. 309-311). IEEE.
9. Mei, B., Xiao, Y., Li, H., Cheng, X., & Sun, Y. (2017, October). Inference attacks based on neural networks in social networks. In Proceedings of the fifth ACM/IEEE Workshop on Hot Topics in Web Systems and Technologies (pp. 1-6).
10. Cable, J., & Hugh, G. (2019). Bots in the Net: Applying Machine Learning to Identify Social Media Trolls.
11. Machová K., Porezaný M., Hreškova M. Algorithms of Machine Learning in Recognition of Trolls in Online Space //2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). – IEEE, 2021. – P. 000349-000354.
12. Τσανταρλιώτης Π. Identification of troll vulnerable tergets in online social networks. – 2016.
13. Mihaylov, T., Mihaylova, T., Nakov, P., Marquez, L., Georgiev, G. D., & Koychev, I. K. (2018). The dark side of news community forums: Opinion manipulation trolls. internet research.
14. Zhukov D., Perova J. A Model for Analyzing User Moods of Self-organizing Social Network Structures Based on Graph Theory and the Use of Neural Networks //2021 3rd International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency ( SUMMA).-IEEE, 2021.-P. 319-322.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
В представленной на рецензирование статье рассматриваются вопросы использования методов тематического моделирования в задачах распознавания темы текста для обнаружения телефонного мошенничества.
Методология исследования базируется на применении методов обработки естественного языка и машинного обучения, методов LSI, LDA, NMF. Актуальность работы обусловлена тем, что решение таких задач как распознавание текста, распознавание конфиденциального или спам сообщения, распознавание тем, классификация документов может быть использовано также для обнаружения телефонного мошенничества.
Научная новизна рецензируемого исследования, по мнению рецензента заключается в предложенной модели для распознавания темы и может быть применена для решения различных задач, в том числе для обнаружения фишинговых электронных писем.
В статье структурно выделены следующие разделы: Введение, Создание набора данных и его предобработка, Реализация извлечения ключевых фраз (Keyphrases Extraction), Построение признаков для моделирования тем, Подбор гиперпараметра и выбор лучшей модели, Интерпретация результатов моделирования, Заключение и Библиография.
Авторами был сформирован набор данных для обучения и тестирования с сайта проекта Project Gutenberg и представляет собой разнообразные сборники сказок разных народов мира – набор данных из 1651 сказки. По этой обучающей выборке были построены модели машинного обучения для распознавания темы текста трех разновидностей: латентно-семантическое индексирование (LSI), латентное размещение Дирихле (LDA), неотрицательное матричное разложение (NMF), проведено их сравнение.
Библиографический список включает 14 источников – публикации отечественных и зарубежных ученых, а также интернет-ресурсы по теме статьи. В тексте имеются адресные ссылки на литературные источники.
В качестве замечаний и пожеланий можно отметить следующие моменты. Во-первых, в наименовании статьи говорится о применении тематического моделирования «для обнаружения телефонного мошенничества», а в тексте речь идет о преимущественно о фишинговых атаках – разновидности интернет-мошенничества с целью получения доступа к конфиденциальным данным пользователей – логинам и паролям. Представляется, что здесь имеет место некоторое несоответствие, поскольку классический телефон представляет собой аппарат для передачи и приёма только лишь звука на расстоянии и вовсе не обязательно имеет выход в Интернет. Во-вторых, наименования не всех разделов в статье выделены особым полужирным шрифтом, что не способствует улучшению восприятия материала. В-третьих, рисунки 2-6, отражающие результаты построения моделей машинного обучения и представляющие собой скрин-шоты экрана, плохо читаются из-за слишком мелкого текста и нечеткого изображения.
Рецензируемый материал соответствует направлению журнала «Программные системы и вычислительные методы», подготовлен на актуальную тему, содержит теоретические обоснования и прикладные разработки, обладает элементами научной новизны и практической значимости, может вызвать интерес у читателей, однако, по мнению рецензента, перед опубликованием статья должна быть доработана в соответствие с высказанными замечаниями.
|
 Рус
Рус









