|
Историческая информатика
Правильная ссылка на статью:
Лягушкина Л.А. Опыт классификации социального положения репрессированных в СССР с помощью метода опорных векторов // Историческая информатика. 2022. № 1. С. 128-139. DOI: 10.7256/2585-7797.2022.1.37719 URL: https://nbpublish.com/library_read_article.php?id=37719
Опыт классификации социального положения репрессированных в СССР с помощью метода опорных векторов
Лягушкина Людмила Алексеевна
ORCID: 0000-0003-4647-5215
кандидат исторических наук
научный сотрудник, Институт советской и постсоветской истории, НИУ ВШЭ
105066, Россия, Москва, г. Москва, Старая Басманная, 24/1с1
Lyagushkina Liudmila
PhD in History
Researcher, Institute of Soviet and Post-Soviet History, HSE
105066, Russia, Moskva, g. Moscow, Staraya Basmannaya, 24/1s1

|
luskom@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2585-7797.2022.1.37719
Дата направления статьи в редакцию:
20-03-2022
Дата публикации:
11-05-2022
Аннотация:
В статье рассматриваются различные подходы к классификации занятий в исторических исследованиях на примере базы данных «Жертвы политического террора в СССР», разработанной историко-просветительским обществом «Мемориал» (признано иностранным агентом и ликвидировано по решению суда). Необходимо обобщить разрозненные данные о профессии и занятиях репрессированных. В статье дается краткий обзор методов, которыми ранее уже решалась эта задача: от ручного отнесения тех или иных занятий и профессий репрессированных к разным общественным группам, которые существовали в 1930-х годах в СССР, до полностью автоматической кластеризации. Далее предлагается новый способ: применить для классификации машинное обучение «с учителем»: использовать уже разделенные в рамках предыдущих исследований на группы записи для обучения алгоритма и последующей автоматической разметки. Наилучшим из опробованных способов оказался метод опорных векторов, который на тестовой выборке показал точность 95%. Рассматриваются преимущества и ограничения подобной классификации, главным из которых является то, что некоторые общественные группы определяются систематически более плохо. Тем не менее, применение этой методики позволило крайне быстро разметить 350 тыс. новых записей из базы данных. Разметка на основе обработанных историком «тренировочных» данных представляется перспективным методологическим направлением для исторической информатики.
Ключевые слова:
исторические базы данных, разметка данных, историческая информатика, отечественная история, СССР, машинное обучение, сталинизм, метод опорных векторов, политические репрессии, классификация данных
Abstract: The article describes various approaches to the classification of occupations in historical research, using the example of the database "Victims of political terror in the USSR". A brief overview of the methods by which this problem was previously solved is given: from manual assignment of certain occupations and professions of the repressed to different social groups that existed in the 1930s in the USSR, to automatic clustering. Further, a new method is proposed: to apply supervised machine learning for classification: use records already divided into groups during the author’s previous studies for training the algorithm and automatic labeling. The best of the tested methods turned out to be the support vector machine, which showed an accuracy of 95% on the test sample. The advantages and limitations of such a classification are considered, with the main limitation appears to be that some social groups are systematically defined more poorly. Nevertheless, the application of this technique made possible to mark up 350 thousand new records from the database extremely quickly. Markup based on the "training" data processed by the historian appears to be a promising direction for historical data science.
Keywords: historical data bases, data markup, historical data science, Russian history, USSR, machine learning, Stalinism, support vector machine, political terror, classification
Машинное обучение все активнее начинает использоваться в гуманитарных науках, однако именно в исторических исследованиях примеров его применения пока немного. Чаще всего подобные методы можно встретить в междисциплинарных статьях по экономической истории, демографии, юриспруденции. Например, машинное обучение помогло с огромной точностью выделить в материалах переписей населения Великобритании сведения о предпринимателях [1], найти одних и тех же людей или членов семей в первичных материалах американских переписей 1900, 1910 и 1920 годов [2], или даже выделить ключевые темы в судебных решениях Великобритании до начала Промышленной революции [3]. Тем не менее, и историкам иногда приходится решать задачи, в которых без современных методов анализа данных не обойтись. В частности, одна из распространенных прикладных задач для исследователей, где машинное обучение может быть крайне полезно – это классификация.
Классификация занятий репрессированных в исторических исследованиях
На российском материале в литературе уже неоднократно поднимался вопрос о классификации занятии репрессированных в СССР, сведения о которых внесены в базу данных «Жертвы политического террора в СССР» [4], созданную международным историко-просветительским обществом «Мемориал»* (внесен Минюстом РФ в список иностранных агентов). Этот богатый источник, в котором более трех миллионов записей о людях, которые подвергались репрессиям в СССР в 1917-1991 годах, неоднократно становился предметом изучения.
Для описания процесса репрессий очень важно понимать, кем являлись жертвы террора. Однако в базе данных «Мемориала» занятия репрессированных представлены очень разнообразно и с разной степенью подробности. У одних написана, например, просто профессия или социальная группа – «колхозник» или «рабочий», у других указано еще и место работы («колхозник колхоза "12-я годовщина Октября"»), иногда весьма подробно указана и должность, и место («землекоп "Союзводстроя" при ГОГРЭС»). Такие различия в формате описания занятий объясняются как спецификой создания этой базы данных (она основана на «Книгах памяти» жертв репрессий, составлявшихся в разных регионах по разным принципам [см. вводную статью на сайте базы данных: 4]), так и огромным объемом записей (даже в рамках одной «Книги памяти» могли быть различия в подходах к набору информации).
Стоит также учитывать, что в некоторых случаях база данных может содержать не совсем достоверную информацию о занятиях репрессированных из-за сложности самого источника, на основе которого она составлялась. Например, в годы террора нередки были случаи, когда незадолго до ареста человека увольняли с какой-либо должности, он устраивался на гораздо менее значимые позиции, и именно они попадали в «Книгу памяти». Тем не менее, исследования, в которых такие сведения проверялись и сопоставлялись, не выявили существенного искажения картины [5, с. 160, 6, с. 34–36]. Соответственно, «Книги памяти» могут оказаться не самым лучшим источником биографической информации о жизни конкретного человека, однако, в целом, должны корректно отражать общую картину.
Исследователи по-разному подходили к вопросу о том, как обобщить занятия жертв репрессий. Одно направление в историографии пыталось восстановить социальное положение репрессированных в соответствии с классификацией Всесоюзной переписи населения 1939 г. М. Илич при анализе «Ленинградского мартиролога» опиралась на классификацию социальных групп (рабочие, колхозники, служащие, кооперированные и некооперированные кустари, единоличники, другие) из переписи 1939 г. При этом исследовательница сделала дополнительную разбивку определенных групп – например, добавив категории «служителей религиозного культа», которые по переписи должны были относиться к категории «другое», или сделав дополнительные категории для разных служащих [7, с. 323–324]. Е. М. Мишина использовала адаптированную классификацию занятий из переписи 1939 г., которая построена по отраслям промышленности: например, колхозники и единоличники входят в единую категорию «сельскохозяйственные занятия» [6, с. 216–224]. Автор данной статьи в своем диссертационном исследовании опиралась на классификацию из внутренней статистики арестов НКВД [8, с. 158–159]. Эта классификация во многом повторяет социальные группы из переписи, однако в ней также выделяется ряд групп, которые были важны в рамках проведения операций Большого террора (1937-1938 гг.) для органов госбезопасности – например, те же самые «служители религиозного культа». Подробнее об этой классификации будет сказано ниже.
Подход указанных выше авторов имеет ряд очевидных достоинств, самое главное из которых состоит в том, что социальное положение репрессированных можно сравнивать с составом населения по переписи. В итоге можно делать вывод о том, какие общественные слои были затронуты репрессиями больше. При этом разбивка репрессированных на группы по этим классификациям во всех случаях, насколько известно автору, происходила в ручном или полуавтоматическом режиме (поиском и автоматической заменой по определенным ключевым словам). Такой способ довольно затратен по времени и поэтому практически исключает возможность анализа сотен тысяч, а тем более миллионов, записей.
Второй возможный подход к классификации занятий – попытка их автоматически разбить. Например, политологи Ю. Жукова и Р. Талибова использовали всю базу «Мемориала» (на момент написания их статьи 2,6 млн человек) для того, чтобы посмотреть на долгосрочные эффекты репрессий на политическое поведение россиян и украинцев, а именно, на их явку на выборах в 2000-2010-х годах. Авторы попытались разбить репрессированных по следующим категориям: сельское хозяйство, лесная промышленность, промышленность, управление, пенсионеры, услуги, неработающие. К сожалению, в статье и в приложенных к ней дополнительных материалах (в т.ч. коде исследования на языке R) не показано, как именно происходило деление, но, по всей видимости, этот способ был не очень удачным: в 73% случаев данные либо отсутствовали, либо их не удалось разбить по указанным выше категориям [9, Online appendix, A.3].
Кроме того, автору известны попытки (в частности, в еще не опубликованной работе Жд. Р. Чуа, Ч. Беккера и К. Гилман из Дьюкского университета) работать с частью базы «Мемориала» с использованием международных классификаторов профессий ISCO (International Standard Classification of Occupations) или ESCO (European Skills, Competences, Qualifications и Occupations.). Это распространенный в социальных науках инструмент, который, к тому же, доступен в пакетах для языка R, что, опять-таки, делает разбивку профессий быстрой и возможной для большого массива данных [10]. Однако и у этого способа есть большие ограничения: во-первых, русский язык не поддерживается (соответственно, все занятия необходимо переводить на английский с неизбежными смысловыми потерями), во-вторых, классификатор разработан для современных, а не для исторических профессий (с 1930-х годов характер многих из них мог измениться) и без учета советской специфики.
Наконец, некоторые подходы к автоматической классификации занятий предпринимались участниками хакатона memo.data, организованного обществом «Мемориал» в 2017 году. Участники команды «Рубрикация профессий репрессированных» подсчитали, что всего в базе данных 500 тыс. различных написаний профессий. Путем предобработки данных, нормализации и лемматизации (приведения слов к нормальной словарной форме) удалось сократить список до 30 тыс. уникальных занятий. Самые частотные 200 профессий при этом покрывали 80% записей. Затем названия профессий были переведены в векторные представления при помощи модели Word2vec, которая работает при помощи нейронной сети, и кластеризованы. Участникам проекта показалось, что наиболее успешно разбиение на 10 кластеров, тем не менее, сами авторы признавали, что в них много ошибок [9]. Результат этой разбивки и классификации можно посмотреть в файле на GitHub [11]. В целом, данный способ представляется эффективным для большого массива данных, но не лишен очевидных недостатков: во-первых, нужно решить, что делать с теми 20% записей, которые покрывают 29 тыс. занятий; во-вторых, четко определить, как именно происходило выделение кластеров и насколько они соотносятся с «социальными группами» 1930-х годов.
Таким образом, в литературе пока не был найден оптимальный для больших объемов данных способ классификации занятий репрессированных. В данной статье будет рассказано о том, как совместить первый из указанных подходов с техническим воплощением из второго.
Классификация «с учителем» при помощи метода опорных векторов
В ходе подготовки диссертации и последующих исследований у автора данной статьи оказалась нормализованная база данных на 65 тысяч человек, репрессированных в рамках «Большого террора» (1937-1938) в пяти регионах РСФСР. В ней всем жертвам террора, у которых были прописаны занятия, описанным выше ручным или «полуавтоматическим» способом (поиском по ключевым словам) были присвоены те или иные категории их социального положения. В дальнейшем для изучения гендерного аспекта репрессий автор решил расширить временной (на 1941-1945 гг.) и географический масштаб работы (еще примерно на 20 регионов), что привело к необходимости классифицировать занятия еще примерно 320 тысяч человек. Для решения этой проблемы был выбран способ машинного обучения «с учителем»: обучив модель на своих исходных данных, можно применить ее для «новых» людей.
Конечно, с источниковедческой точки зрения гораздо корректнее было бы использовать для «обучения» модели не подготовленную человеком выборку (так как она не исключает субъективности), а уже готовый классификатор социальных положений из исторического источника конца 1930-х годов. Подобные классификаторы занятий в СССР существовали в более позднее время, однако для конца 1930-х годов ничего подобного автору найти не удалось. В некоторых случаях социальное положение репрессированных, наряду с их занятием, можно найти в следственных делах – такая графа была в анкетах арестованных. Однако более подробное изучение этого источника ставит под вопрос корректность заполнения графы о социальном положении со слов репрессированных. Возможно, что арестованные сами не до конца не понимали, что такое «социальная группа» [5, с. 163]. О том, что в ответ на прямой вопрос люди будут называть неверные социальные группы, переживали и статистики, готовившие Всесоюзную перепись населения 1937 года [12, с. 20]. Таким образом, создание подобной «идеальной» тренировочной базы данных пока можно считать перспективной задачей.
В рамках исследования для обучения модели был использован датасет (набор данных) с двумя основными переменными: во-первых, занятие человека, как оно было указано в базе данных «Мемориала», во-вторых, его социальное положение. Система классификации была несколько доработана по сравнению с диссертацией в процессе работы автора над другим проектом, совместным с А. М. Маркевичем. Репрессированные делились на 13 групп (классов), а именно: колхозники; рабочие; служащие; единоличники; кооперированные кустари; некооперированные кустари; домашние хозяйки, иждивенцы, пенсионеры; лица без определенных занятий и другие деклассированные элементы; служители религиозного культа; красноармейцы и младший начсостав; комсостав РККА; сотрудники НКВД; статус не определен. Последняя категория была введена для тех случаев, когда по занятию человека сложно определить, к какой группе по переписи он бы относился. Например, в эту группу попали заключенные, так как при проведении переписи 1939 года их учитывали либо по их занятиям в лагерях и колониях (так они пополняли ряды «рабочих»), либо по их занятиям до ареста (в случае тех, кто находился под следствием), либо же как «заключенных» (тех, кто был в тюрьме) [12, с. 119].
Далее этот датасет был загружен в программную среду Python и обрабатывался с использованием библиотеки scikit-learn. Тестировались разные настройки и методы предобработки исходного текста. Из опробованных мною моделей лучшие результаты показал линейный классификатор – метод опорных векторов (SVM) со стохастическим градиентным спуском (SGD). Этот классификатор часто используется, например, в спам-фильтрах. Общий принцип его работы заключается в следующем: классификатор пытается определить уравнение гиперплоскости, которая может оптимальным образом – с наибольшим расстоянием – распределить два класса по набору признаков. Объекты, попадающие по одну сторону, являются первым классом, по другую – вторым [13, с. 199–200].
Вначале исходные тексты с занятиями людей предобрабатывались при помощи регулярных выражений (regular expressions), языка, который помогает искать и заменять различные части в текстовых переменных. В частности, стандартные сокращения (например, «к-з») были заменены на полные наименования («колхоз»), наименования конкретных предприятий были по возможности удалены (например, счетовод артели «Красный грузчик» мог быть записан не служащим, а рабочим, из-за названия артели), удалены разные специальные символы, все буквы приведены к единому регистру. На рис. 1. можно видеть, как выглядел датасет после первичной предобработки.
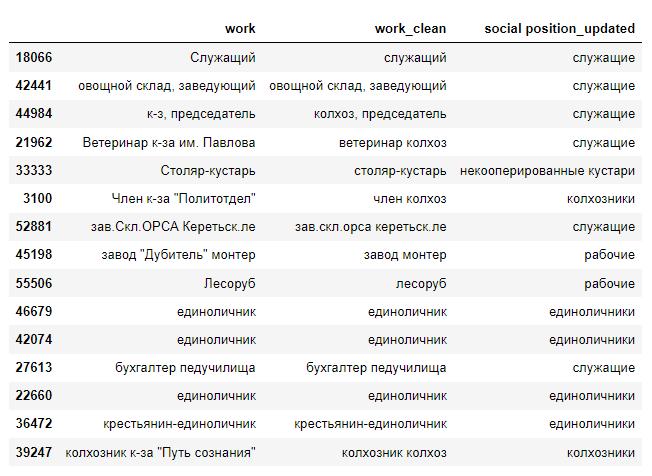
Рис. 1. Случайные примеры записей датасета перед началом обучения (скриншот из среды Jupyter Notebook). Переменная work показывает исходное значение в базе данных, work_clean – предобработанное, social position_updated – социальная позиция, к которой был отнесен тот или иной человек.
Затем имеющийся датасет был разделен на тренировочную (90%) и тестовую (валидационную) выборку (10%). При помощи инструмента TfidfVectorizer текстовые описания переменной «work_clean» были превращены в числовые вектора, учитывавшие важность упоминания каждого слова в наборе слов. Затем модель (SGDClassifier в пакете scikit-learn) обучалась на тренировочной выборке, затем применяла полученные данные на тестовой.
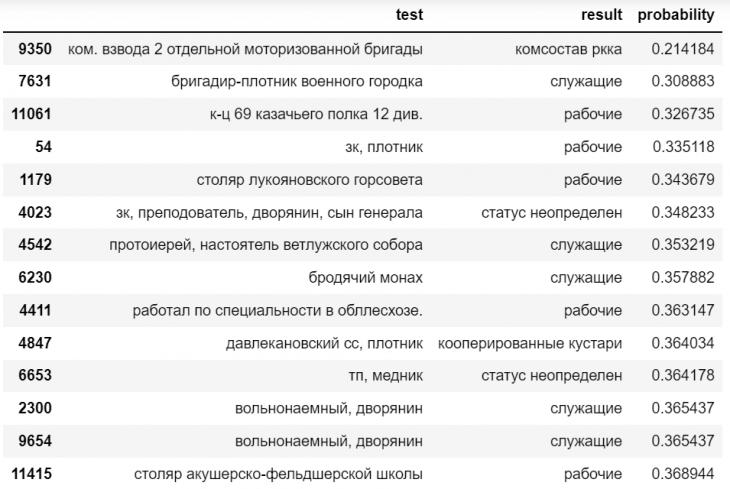
Рис. 2. Записи из тестовой выборки (переменная test), которые были отнесены к итоговому классу (result) c наименьшей вероятностью (probability) (скриншот из среды Jupyter Notebook).
Модель работает таким образом, что какое-то значение (класс) присваивается переменной в каждом случае. Однако понятно, что есть очень много спорных и сложных случаев, и в практическом смысле было бы важно при ручной проверке иметь возможность их автоматически подсветить. Поскольку сам метод опорных векторов не предполагает расчет вероятностей отнесения к тому или иному классу, для этого был использован дополнительный инструмент – CalibratedClassifierCV пакета scikit-learn. Он позволяет рассчитывать вероятность отнесения каждой записи к каждому из 13 классов. На рис. 2 представлены самые «спорные» случаи, когда та или иная запись была отнесена к итоговому классу с наименьшей вероятностью.
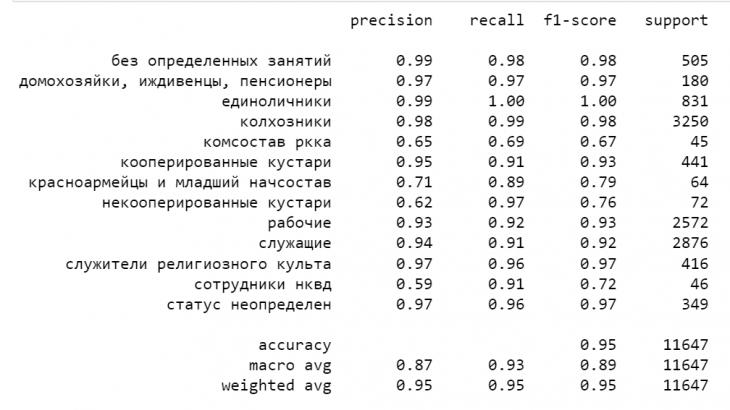
Рис. 3. Оценка успешности классификации моделью тестовой выборки (скриншот из среды Jupyter Notebook).
Результаты работы модели (на тестовой выборке) представлены на рис. 3. В целом, модель довольно успешно «предсказала» классы записей. Средняя точность (precision), то есть доля объектов, отнесенных классификатором к этому классу и при этом действительно являющимся положительными – 0,87, средняя взвешенная точность (с учетом численности категорий) – 0,95. То есть в 95% случаев классы на тестовой выборке были определены правильно.
Тем не менее, основной проблемой является то, что некоторые классы социального положения систематически определялись хуже. Самые худшие показатели были у категорий «красноармейцы и младший начсостав» и «комсостав» РККА, «некооперированные кустари», «сотрудники НКВД». Из-за их маленькой численности (в колонке Support рис. 3 можно видеть число наблюдений в тестовой выборке для каждой из категорий) их общий «вклад» в общий результат не такой большой, но недоучет отдельных категорий может в некотором случае повлиять на качественные выводы исследования.
В результате ручной проверки удалось выявить ряд типичных причин ошибок: во-первых, некоторые категории занятий автоматически плохо определялись из-за особенностей их написания, в особенности это касается групп военных «красноармейцы и младший начсостав» и «комсостав РККА». В такого рода записях много специфических сокращений и цифр (например, «198-й СП 66-й СД, ком. отделения»), важно сочетание слов («в/ч 5499, ком. роты»). Все это затрудняет классификацию по крайней мере на тех объемах данных, которые использовались для обучения (эта группа репрессированных, в целом, в нашем датасете была относительно небольшой – около 1%, 740 наблюдений). Во-вторых, плохо работала разбивка в сложных случаях, когда нужно выбрать из нескольких разных занятий. Например, в исследовании было решено размечать заключенных по их предыдущим занятиям, если это было указано, а если не указано, помечать как «статус не определен». В итоге запись «заключенный, сл. культа – ксендз» была размечена как «статус не определен», хотя по методологии ее нужно было отнести к категории «служители культа».
Таким образом, несмотря на некоторую условность подобной разметки репрессированных и неизбежность того, что ряд записей будет классифицирован неправильно, в результате применения этой методики удалось очень быстро разметить 320 тыс. записей о репрессированных в СССР. В результате ручной проверки случайных выборок (по 30 записей) из этих новых размеченных данных корректировались социальные группы от 6,6 до 10% записей, т.е. можно предположить, что, в среднем, 92% записей автоматически удалось классифицировать верно. Поскольку эти записи использовались в рамках исследования гендерного аспекта репрессий для сравнений между собой разных частей одной и той же выборки: двух волн террора (1937-1938 гг. и 1941-1945 гг.) и положения мужчин и женщин, кажется, что некоторый неизбежный процент ошибок в этой разбивке не должен заметно повлиять на качественные выводы исследования.
Вероятно, есть способы улучшить качество классификации. Во-первых, имело бы смысл добавить в обучающую выборку больше примеров классов (групп по социальному положению), которые мало представлены в ней. Например, больше примеров военных – их гораздо больше встречается в базе данных в период войны. Во-вторых, возможно, необходимо пересмотреть классификацию, объединить военных (у них две категории: комсостав и рядовой состав) и кустарей (они разбиты «некооперированные» и «кооперированные») в две соответствующие группы. В-третьих, возможно, определенные категории либо те наблюдения, где меньше всего «вероятность» отнесения к определенному классу (о чем говорилось выше по поводу рис. 2) лучше перепроверять вручную, если объем разметки относительно небольшой.
Наконец, важно, что автор не прибегал к более сложным инструментам обработки естественного языка (NLP). Например, возможно, имело бы смысл привлечь модели корпуса русского языка [14] и, как участники упоминавшегося выше проекта хакатона, использовать, например, инструмент word2vec. В таком случае, мы работали бы не только с теми словами, которые упоминаются в наборе данных, но и привлекли бы лексические вектора слов из корпуса русского языка, составленного на основе огромного количества текстов на русском языке. Это позволило бы расширить способность модели «понимать» близость тех или иных слов друг к другу, учитывать синонимичность. С другой стороны, возможно, что, с учетом специфики и узкой направленности текстов (мы классифицируем только описания занятий, работы, мест работы), это не позволило бы принципиально улучшить разбивку.
Представленный в статье способ классификации является одним из самых распространенных алгоритмов в машинном обучении. Автор, не являясь экспертом в этой области, не претендует на то, что для рассматриваемого случая он единственный оптимальный. Возможно, протестировав еще ряд различных способов и настроек, упомянутых выше, можно было бы добиться повышения точности предсказаний классов еще на несколько процентов.
Цель этой статьи – прежде всего показать, что методы машинного обучения в принципе могут находить применение в исторических исследованиях. И это далеко не единственный способ даже для тех же данных «Мемориала». Например, используя фамилии и имена репрессированных, а также данные об их национальности, можно «обучить» модель приблизительно определять национальность репрессированных по их фамилии в тех случаях, когда она не упоминалась. Очевидно, что этот способ будет содержать высокую долю ошибок, однако при большом объеме данных некоторое представление о национальном составе можно получить. Авторы еще одного исследования с базой данных «Мемориала» и «Память народа» использовали тот же метод опорных векторов для определения национальности военнослужащих по фамилии (при этом они определяли только то, относился ли человек к титульной русской национальности или нет) и утверждают, что точность предсказания составила 96,5% [15].
За годы работы в русле исторической информатики и digital humanities исследователями было создано большое количество баз данных. Часто они являются плодами длительной и кропотливой работы авторов по перенесению материалов из сложного источника в электронную форму. Нередко такие базы создаются для исследования конкретных вопросов, с ними работают только их авторы, а после окончания проекта они остаются в закрытом доступе. В дальнейшем кажется вполне возможным и перспективным использование подобных «авторских» баз в качестве «обучающего» материала для решения сходных методологических задач в разных междисциплинарных исследованиях, как это было продемонстрировано на примере базы данных репрессированных.
Библиография
1. Montebruno P., Bennett R., Smith H., Lieshout, C. Machine learning classification of entrepreneurs in British historical census data // Information Processing & Management. 2020. Vol. 57, № 3. P. 102210.
2. Price J., Buckles K., Leeuwen J. V., Riley I. Combining Family History and Machine Learning to Link Historical Records. Cambridge, MA: National Bureau of Economic Research, 2019. P. 101391.
3. Grajzl P., Murrell P. A machine-learning history of English caselaw and legal ideas prior to the Industrial Revolution I: generating and interpreting the estimates // Journal of Institutional Economics. 2021. Vol. 17, № 1. P. 1–19.
4. Жертвы политического террора в СССР [Электронный ресурс] // Международное общество «Мемориал». 2017. URL: https://base.memo.ru/ (дата обращения: 03.03.2022).
5. Лягушкина Л.А. К оценке информационного потенциала «Книг памяти» в сравнении со следственными делами жертв «Большого террора» // Исторический журнал: научные исследования. 2014. Vol. 2. С. 157–166.
6. Мишина Е.М. Время «тихого террора». Политические репрессии на Алтае в 1935 – первой половине 1937 г. Политическая энциклопедия. Москва, 2021. С. 216-224.
7. Ilic M. The Great Terror in Leningrad: Evidence from the Leningradskii martirolog // The Anatomy of Terror / ed. Harris J. Oxford University Press, 2013. P. 306–325.
8. Трагедия советской деревни. Коллективизация и раскулачивание. 1927—1939. Документы и материалы. Т. 5, кн. 2. М.: Российская политическая энциклопедия, 2006. С. 158-159.
9. Zhukov Y.M., Talibova R. Stalin’s terror and the long-term political effects of mass repression // Journal of Peace Research. 2018. Vol. 55, № 2. P. 267–283.
10. Occupations Classification. ESCO-ISCO relationship [Электронный ресурс] // R-Packages. URL: https://cran.r-project.org/web/packages/labourR/vignettes/occupations_retrieval.html (дата обращения: 03.03.2022)
11. Архив проекта хакатона memo.data на GitHub: Python. [Электронный ресурс] // GitHub. URL: https://github.com/fatayri/memodata/blob/9b9d82b12f382547b6fea4671c3c49373423e194/final_clusters.csv (дата обращения: 03.03.2022)
12. Жиромская В. Б., Киселев И. Н., Поляков Ю. А. Полвека под грифом "секретно": Всесоюзная перепись населения 1937 года. Москва: Наука, 1996. С. 20, 119.
13. Жерон О. Прикладное машинное обучение с помощью Scikit-Learn и TensorFlow. Концепции, инструменты и техники для создания интеллектуальных систем. СПб: Диалектика, 2018. С. 199-200.
14. RusVectōrēs: модели [Электронный ресурс] URL: https://rusvectores.org/ru/models/ (дата обращения: 05.03.2022).
15. Rozenas A., Talibova R., Zhukov Y.M. Fighting for Tyranny: State Repression and Combat Motivation [Working paper]. URL: https://www.royatalibova.com/_files/ugd/c3f304_38dc519b11794aa180a7527cf79cd406.pdf (дата обращения: 05.03.2022)
References
1. Montebruno, P., Bennett, R. J., Smith, H., & Lieshout, C. van. (2020). Machine learning classification of entrepreneurs in British historical census data. Information Processing & Management, 57(3), 102210. https://doi.org/10.1016/j.ipm.2020.102210
2. Price, J., Buckles, K., Van Leeuwen, J., & Riley, I. (2019). Combining Family History and Machine Learning to Link Historical Records (No. w26227; p. w26227). National Bureau of Economic Research. https://doi.org/10.3386/w26227
3. Grajzl, P., & Murrell, P. (2021). A machine-learning history of English caselaw and legal ideas prior to the Industrial Revolution I: Generating and interpreting the estimates. Journal of Institutional Economics, 17(1), 1–19. https://doi.org/10.1017/S1744137420000326
4. Victims of political terror in the USSR. (2017). International Society "Memorial". https://base.memo.ru/
5. Lyagushkina, L. A. (2014). To assess the information potential of the "Books of Memory" in comparison with the investigative cases of the victims of the "Great Terror". Historical Journal: Research Studies, 2, 157–166.
6. Mishina, E. M. (2021). The time of "quiet terror". Political repressions in Altai in 1935-the first half of 1937 (Political Encyclopedia).
7. Ilic, M. (2013). The Great Terror in Leningrad: Evidence from the Leningradskii martirolog. In J. Harris (Ed.), The Anatomy of Terror (pp. 306–325). Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199655663.003.0017
8. The tragedy of the Soviet village. Collectivization and dispossession. 1927-1939. Documents and materials. T. 5, book. 2. (2006), 158-159. Russian political encyclopedia.
9. Zhukov, Y. M., & Talibova, R. (2018). Stalin's terror and the long-term political effects of mass repression. Journal of Peace Research, 55(2), 267–283. https://doi.org/10.1177/0022343317751261
10. Occupations classification. ESCO-ISCO relationship. (n.d.). Retrieved March 18, 2022, from https://cran.r-project.org/web/packages/labourR/vignettes/occupations_retrieval.html
11. Hackathon project archive memo.data on GitHub [Python]. (2020). https://github.com/fatayri/memodata/blob/9b9d82b12f382547b6fea4671c3c49373423e194/final_clusters.csv (Original work published 2017)
12. Zhyromskaya, V. B., Kiselev, I. N., & Polyakov, Yu. A. (1996). Half a century classified as "secret": All-Union population census of 1937 (pp. 20, 119). Moscow: Nauka.
13. Geron, O. (2018). Applied Machine Learning with Scikit-Learn and TensorFlow. Concepts, tools and techniques for creating intelligent systems. Dialectics (pp. 199-200). Saint Petersburg.
14. RusVectōrēs: Models. (n.d.). Retrieved March 5, 2022, from https://rusvectores.org/ru/models/
15. Rozenas, A., Talibova, R., & Zhukov, Y. M. (2021). Fighting for Tyranny: State Repression and Combat Motivation. https://www.royatalibova.com/_files/ugd/c3f304_38dc519b11794aa180a7527cf79cd406.pd
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Рецензия на статью «Опыт классификации социального положения репрессированных в СССР с помощью метода опорных векторов»
Рецензируемая статья является одним из первых исторических исследований, в котором эффективно применяются методы искусственного интеллекта, конкретно – машинное обучение с учителем. В данной работе автор использует метод опорных векторов. Решается задача классификации занятий репрессированных в 1930-1940-х гг. по сведениям базы данных «Жертвы политического террора в СССР».
Занятия репрессированных – важная характеристика их социального облика, одна в некоторых случаях используемая база данных может содержать не вполне достоверную информацию по этому пункту. Нередко сведения по этому пункту вообще отсутствуют. Автор данной статьи отмечает, что попытки изучения и классификации занятий репрессированных предпринимались в течение последних десятилетий, однако признать их успешными не приходится.
Используемая автором база данных включает сведения о более чем 380 тысяч человек. Идея используемого метода машинного обучения «с учителем» заключается в том, что, обучив нейросеть на хорошо изученном датасете, применить полученную модель для основного массива данных.
В рамках исследования для обучения модели был использован набор данных с двумя основными переменными. Как отмечает автор, это «во-первых, занятие человека, как оно было указано в базе данных «Мемориала», во-вторых, его социальное положение. Репрессированные делились на 13 групп (классов), а именно: колхозники; рабочие; служащие» и др. Кроме того, вводится категория «статус не определен». На обучающей выборке формировалось правило соответствия занятий и социальных групп, далее на основе этого правила проводилось «распознавание» социального положения для всей совокупностей записей в базе данных.
Достоинством работы и несомненной новизной работы является использование в ходе исследования программной среды Python, в которой тестировались разные настройки и методы предобработки данных. Метод позволяет оценивать вероятность отнесения каждой записи (персоналии) в базе данных к каждому из 13 классов. Автор приводит примеры скриншотов результатов оценки успешности такой классификации. В целом модель дала высокие показатели «предсказания» классов занятий, средняя взвешенная точность – 95% на тестовой выборке.
Логично, что при этом некоторые классы социального положения определялись хуже, это относится к малочисленным социальным группам (например, «некооперированные кустари» и комсостав РККА). Применение этой методики позволило автору очень быстро разметить 320 тысяч записей по репрессированным в СССР и использовать результаты в исследовании гендерного аспекта репрессий. Это редкий пример работы историка с огромным массивом данных.
В заключительно части статьи автор рассматривает возможные способы улучшить качество классификации, например, добавить в обучающую выборку больше вариантов социальных групп, а также использовать более сложные инструменты обработки естественного языка (NLP).
Важный результат данной статьи – демонстрация того, что методы машинного обучения могут применяться в исторических исследованиях, однако, следует отметить, что это требует больших объемов обучающих выборок.
Статья требует дополнительной вычитки: в начале предложения после рис. 3 отсутствует пробел; в тексте несколько раз встречается сочетание «статус неопределен» вместо «статус не определен».
С учетом указанной правки статья, безусловно, заслуживает публикации в журнале «Историческая информатика», поскольку обладает научной новизной и оригинальностью. Статья написана хорошим языком, опирается на подробную историографию и будет интересна широкому кругу читателей журнала.
|
 Рус
Рус












