|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Пекунов В.В.
Индукция правил трансформации естественно-языковой постановки задачи в смысловую модель порождения решающей программы
// Программные системы и вычислительные методы.
2020. № 3.
С. 29-39.
DOI: 10.7256/2454-0714.2020.3.33789 URL: https://nbpublish.com/library_read_article.php?id=33789
Индукция правил трансформации естественно-языковой постановки задачи в смысловую модель порождения решающей программы
Пекунов Владимир Викторович
доктор технических наук
Инженер-программист, ОАО "Информатика"
153000, Россия, Ивановская область, г. Иваново, ул. Ташкентская, 90
Pekunov Vladimir Viktorovich
Doctor of Technical Science
Software Engineer, JSC "Informatika"
153000, Russia, Ivanovskaya oblast', g. Ivanovo, ul. Tashkentskaya, 90

|
pekunov@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2020.3.33789
Дата направления статьи в редакцию:
30-08-2020
Дата публикации:
26-10-2020
Аннотация:
В данной работе рассматривается проблема автоматического синтеза (индукции) правил преобразования естественно-языковой постановки задачи в смысловую модель задачи, по которой может быть порождена решающая данную задачу программа. Данная проблема рассматривается применительно к системе порождения, распознавания и трансформации программ PGEN++. На основании анализа литературных источников выбран комбинированный подход к решению данной проблемы, в рамках которого правила преобразования естественно-языковой постановки в смысловую модель задачи генерируются автоматически, а спецификации порождающих классов и правила порождения программы по модели пишутся вручную, специалистом в конкретной предметной области. В рамках объектно-событийных моделей впервые предложен механизм автоматической генерации распознающих скриптов и сопутствующих им сущностей (CSV-таблиц, XPath-функций). Генерация производится на основании анализа обучающей выборки, включающей предложения, описывающие объекты предметной области, в сочетании с экземплярами таких объектов. Анализ выполняется путем поиска уникальных ключевых слов и характерных грамматических отношений с последующим применением простых элиминативно-индуцирующих схем. Также предложен механизм автоматической генерации правил восполнения/достраивания первичных распознанных моделей до полноценных смысловых. Такая генерация выполняется путем анализа отношений между объектами обучающей выборки с учетом информации из спецификаций классов предметной области. Предложенные схемы опробованы на предметной области "Простая обработка векторных данных", показана успешная трансформация естественно-языковых постановок (как входящих в обучающую выборку, так и модифицированных) в смысловые модели с последующим порождением решающих поставленные задачи программ.
Ключевые слова:
обработка естественно-языковых текстов, порождение программ, синтез кода, индукция правил, элиминативная индукция, обучающая выборка, грамматический разбор, предметно-ориентированный язык, XPath-функции, регулярные выражения
Abstract: The author considers a problem of automatic synthesis (induction) of the rules for transforming the natural language formulation of the problem into a semantic model of the problem. According to this model a program that solves this problem can be generated. The problem is considered in relation to the system of generation, recognition and transformation of programs PGEN ++. Based on the analysis of literary sources, a combined approach was chosen to solve this problem, within which the rules for transforming the natural language formulation into a semantic model of the problem are generated automatically, and the specifications of the generating classes and the rules for generating a program from the model are written manually by a specialist in a specific subject area. Within the framework of object-event models, for the first time, a mechanism for the automatic generation of recognizing scripts and related entities (CSV tables, XPath functions) was proposed. Generation is based on the analysis of the training sample, which includes sentences describing objects in the subject area, in combination with instances of such objects. The analysis is performed by searching for unique keywords and characteristic grammatical relationships, followed by the application of simple eliminative-inducing schemes. A mechanism for the automatic generation of rules for replenishing / completing the primary recognized models to full meaning ones is also proposed. Such generation is performed by analyzing the relations between the objects of the training sample, taking into account information from the specifications of the classes of the subject area. The proposed schemes have been tested on the subject area "Simple vector data processing", the successful transformation of natural language statements (both included in the training set and modified) into semantic models with the subsequent generation of programs solving the assigned tasks is shown.
Keywords: natural-language processing, program generation, code synthesis, rules induction, eliminative induction, training sample, grammar parsing, domain-specific language, XPath-functions, regular expressions
Введение
В настоящее время технологии искусственного интеллекта активно развиваются, находя применение при решении разнообразных научно-технических и практических задач. Особенное внимание при этом уделяется технологиям, связанным с разработкой естественно-языковых интерфейсов, позволяющих резко упростить взаимодействие человека с техникой, а также технологиям, позволяющим полностью или частично автоматизировать решение различных интеллектуальных и творческих задач. В таких условиях особенно актуальна задача автоматической генерации программного кода, решающего некоторую проблему, по естественно-языковому описанию данной проблемы (см., например, [1, 2]). Относительно несложно построить систему, решающую такую задачу для какой-либо определенной предметной области [3], значительно сложнее построить универсальную систему, способную приобретать знания о решении конкретной проблемы в произвольной предметной области [4]. Соответствующая задача в полной мере не решена и также является актуальной. В данной работе такая задача рассматривается на примере системы порождения, идентификации и преобразования программ PGEN++ [3].
Можно выделить четыре основных подхода к приобретению знаний в системах автоматической генерации программного кода: а) ручное составление правил вывода/восполнения модели задачи, б) автоматическое составление правил на основе некоторого набора обучающих пар «постановка задачи – программа» (может быть определен вручную [5] или собран на каких-либо интернет-ресурсах, подобных GitHub или StackOverflow [6, 7]), в) прямое применение обучающего набора (без вывода правил) и г) комбинированный. Первый подход [8] достаточно надежен, но требует участия человека и весьма затратен по времени. Второй подход [6] участия человека не требует и показывает достаточно хорошие (однако более слабые в сравнении с первым подходом) по качеству результаты. Третий подход [5, 9] также не требует участия человека, однако не вполне детерминирован и, как следствие, требует достаточно совершенных схем контроля результата (см., например, [9]), сложных как с синтаксической, так и с семантической точки зрения. Наиболее перспективным, вероятно, является четвертый подход (см., например, [4]), позволяющий сочетать достоинства различных вариантов и, вероятно, являющийся наиболее уместным для систем класса DSL (Domain Specific Language). Такие системы ориентированы на порождение программ в четко формализованных предметных областях, изначально отличаются наличием четких формальных правил (A) вывода конечного кода (созданных вручную) и требуют лишь определения дополнительных правил (Б) трансформации естественно-языковых описаний задачи во входные DSL-описания, что является существенно более простой процедурой, чем построение правил трансляции естественно-языковых описаний непосредственно в программный код [5, 8, 9]. Как следствие, такие системы выдают достаточно качественные результаты, нередко полностью лишенные ошибок.
На основании данного анализа было принято решение строить механизм приобретения знаний в системе порождения программ PGEN++ (фактически являющейся DSL-системой) на базе четвертого подхода. При этом правила вывода кода из смысловой модели программы составляются вручную, а правила преобразования естественно-языковой постановки в смысловую модель генерируются автоматически, в процессе приобретения знаний. Полученное решение данной проблемы в контексте базовой схемы (на основе объектно-событийных моделей, отображаемых в XML-документы), применяемой в PGEN++, является новым.
Целью данной работы являлось повышение эффективности разработки правил трансформации естественно-языковых описаний задачи (на русском языке) в решающий программный код. Для достижения данной цели ставились задачи:
а) добиться полной автоматизации процесса составления правил (Б) восполнения модели в DSL-системе PGEN++, который в схожих работах [4] автоматизирован лишь частично (вручную составлялись CSR-правила). Полной автоматизации должна способствовать четкая формализованность классов и правил соединения объектов этих классов в PGEN++, позволяющая максимально упростить синтез правил (Б) восполнения первичных моделей;
б) добиться полной автоматизации процесса составления правил (Б) первичного распознавания объектов из естественно-языковой постановки. Такие правила будут генерироваться путем анализа заданного набора примеров «постановка – фрагменты DSL(XML)-модели задачи». При этом, следуя идеям работы [10], можно избежать решения проблемы полного распознавания смысла исходного текста. Достаточно ограничиться задачами выявления идентифицирующих повторяющихся грамматических отношений между ключевыми элементами входных предложений, составления словарей допустимых слов (элементов таких отношений), выявления порядка следования неязыковых элементов-параметров (чисел, идентификаторов на латинице) в предложениях и их сопоставления значениям полей объектов, входящих в XML-постановку проблемы.
Общее описание процесса преобразования естественно-языковой постановки задачи в решающий программный код
В системе PGEN++ [3] используется двухстадийная схема преобразования естественно-языковой постановки задачи в программный код: на первой стадии текст на естественном языке преобразуется в смысловую XML-модель [2] (может быть отображена в визуально-блочную диаграмму), на второй стадии XML-модель однозначно отображается в решающе-порождающую объектно-событийную модель, которая генерирует решающую программу (описание данного процесса выходит за рамки настоящей работы). Нас интересует первая стадия – преобразование текстовой постановки (в данном случае – на русском языке) в XML-модель, которое, в свою очередь, является двухэтапным процессом:
а) на первом этапе ко входному тексту применяются распознающие скрипты, которые, с помощью наборов регулярно-логических выражений, разбивают текст на предложения, определяют классы объектов, описываемые этими предложениями (здесь может задействоваться слой грамматического разбора link-grammar [11], выявляющий грамматические связи между словами предложения, имеющий интерфейс (на базе XPath-функций) с регулярно-логическими выражениями), создают первичный набор из несвязанных объектов, формирующих первичную XML-модель, заполняют поля этих объектов;
б) на втором этапе к первичной XML-модели применяются специальные правила достраивания и трансформации (слабые ограничения на основе синтаксиса XPath, см. [2]), которые восполняют модель (превращая ее в порождающую), добавляя необходимые отсутствующие объекты и соединяя их связями.
Соответственно, приобретение знаний о преобразовании естественно-языковых постановок в порождающие XML-модели включает два основных этапа: индукцию распознающих скриптов для каждого класса текущей предметной области и индукцию правил достраивания и трансформации. Как будет показано далее, для выполнения этих этапов вполне достаточно наличия наперед заданных базовых знаний о предметной области (спецификаций классов данной области и правил соединения объектов этих классов в модель задачи) и набора обучающих пар вида «предложение – объекты со связями», где предложение исчерпывающим образом указывает на класс и (в явной или неявной форме) описывает значения полей соответствующего объекта.
Формально опишем каждую обучающую пару как (G, S), где G – объект модели (для которого известны связи f(G)), S – предложение, порождающее данный объект.
Индукция распознающих скриптов
Выходными данными этого этапа являются распознающие (индуцирующие) скрипты, вспомогательные XPath-функции для обеспечения интерфейса со слоем грамматического разбора, CSV-таблицы синонимического или трансляционного (справочного) характера.
Построение распознающих скриптов ведется последовательно, класс за классом. Для каждого класса C в обучающей выборке обнаруживается множество пар (GC, S), где GC – один из объектов, относящихся к классу C. Далее в предложениях S выделяются фрагменты-параметры P (последовательности латинских букв или цифр, являющихся некими параметрами текущего объекта), для которых делается допущение о неизменности порядка их следования в такого рода предложениях. Формируется простой распознающий шаблон в виде группы регулярно-логических выражений, выделяющих очередное предложение и выявляющих требуемое количество фрагментов-параметров.
На основе прямого сопоставления значений полей объектов GC значениям выделенных параметров P составляются схемы заполнения полей, которые могут включать константы, значения P и/или некие уникальные значения Ti, которые взаимно однозначно сопоставляются обнаруженным в i-ых предложениях характерным словам Wi (для этого составляются CSV-таблицы пар (Ti, Wi), которые формируются с применением простых элиминативно-индукционных методов). Очевидно, что
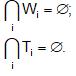
Выделенные схемы заполнения полей записываются в индуцирующие скрипты.
Далее, с помощью библиотеки грамматического разбора link-grammar в предложениях S обнаруживаются связки A вида «действие – объект действия» и формируются две синонимические CSV-таблицы – T1 (варианты глаголов, выражающих действие) и T2 (варианты существительных, выражающих объект действия). Формируются первые индуцирующие правила, обращающиеся к слою грамматического разбора (с этой целью составляются соответствующие XPath-функции, работающие с виртуальными XML-документами – результатами грамматического разбора), выявляющие связки «действие – объект действия» и проверяющие соответствующие слова-члены связок по таблицам T1 и T2. Далее в предложениях S, относящихся к объектам GC класса C, выявляются уникальные слова U, наличие которых позволяет однозначно говорить о том, что данные предложения действительно описывают объекты именно класса C. Если Wi – слова из i-го предложения, относящегося к объектам GC, а Wj – слова из прочих предложений, то
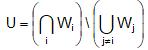 . .
Если такие уникальные слова U обнаруживаются, то для каждого из них определяется типовая цепь связок со словами главной связки A «действие - объект действия». Если для некоего Uk такая однозначная цепь связок существует, формируется дополнительное индуцирующее правило, которое проверяет наличие в выделенном предложении соответствующего слова, находящегося в такой характерной цепи связок с элементами связки A. На этом формирование индуцирующих скриптов завершается и начинается составление правил достраивания, которое будет рассмотрено в следующем пункте.
Предположим, что строится распознающий скрипт для класса «Обработка векторных данных» для предметной области «Простая обработка векторных данных». Пусть обучающая выборка содержит предложения для различных классов, в том числе для данного – два предложения (и, соответственно, два разных объекта, значения полей которых указаны):
(GС1, S1) = ((IVar = «V»; Op = «Min»; OVar = «min»; ID = «MinVmin»), «Найдем минимум вектора V и поместим результат в скаляр min.»);
(GС2, S2) = ((IVar = «V»; Op = «Max»; OVar = «max»; ID = «MaxVmax»), «Найдем также максимум вектора V и поместим результат в скаляр max»).
Приведем фрагмент построенного распознающего скрипта:
@global_unique(MAIN,infinity):-
()->{V0}()->{V3}()->{VRES0}()->{V4}()->{VRES1}
(([^w.]+(w+)->{P0}[^w.]+(w+)->{P1}[^.]*.)->{Grammar.ru{SENTENCE}}(*PRUNE))?=>{
xpathf(SENTENCE,'MVv1oi',$V0,'результат','true'),dbconsts1(V0),
xpathf(SENTENCE,'NXv0io','результат',$V3,'true'),dbtables0(V3,$VRES0),
xpathf(SENTENCE,'NXv0io','результат',$V4,'true'),dbtables1(V4,$VRES1)
}.
@auto:-MAIN:"//P0/text()" => "IVar",MAIN:"//VRES0/text()" => "Op",MAIN:"//P1/text()" => "OVar",MAIN:"//VRES0/text()"+ MAIN:"//P0/text()"+MAIN:"//VRES1/text()" => "ID".
В верхней части данного фрагмента отчетливо обозначены: схемы выделения двух фрагментов-параметров P0 и P1, а также индуцирующие правила, определяющие грамматические отношения уникального для данного класса слова «результат» с элементами главной связки «действие – объект действия» (MVv1oi), а также со словом («минимум» или «максимум»), детерминирующим вид обработки (NXv0io), причем осуществляется трансляция данного слова в значения («Min»/«Max» и «min»/«max») для заполнения полей объекта (по формируемым таблицам dbtables0.csv и dbtables1.csv соответственно). В нижней части фрагмента обозначена схема заполнения полей объекта непосредственно значениями параметров P0 и P1, а также таблично транслированными значениями VRES0 и VRES1.
В качестве примера также приведем текст автоматически сгенерированной XPath-функции NXv0io, возвращающей правое слово (по известному левому) в грамматическом отношении типа «NXv»:
* NXv0io($i0,&$o1): (count(/*/Link[Name/text()="NXv" and Right/Value/text()=$i0 and set($o1,Left/Value/text())]) > 0).
Индукция правил достраивания и трансформации
Выходными данными этого этапа является набор XPath-подобных правил достраивания [2]. Для их составления используется тот же набор пар (GC, S), причем известны связи f(GC) для каждого из объектов GC.
Выявляется набор классов, к которым относятся объекты GC и типы реализованных связей f(GC) между контактами классов: фактически строится сеть классов (C, E), где каждой дуге – типу связи E = (C1, C2) соответствует набор реализованных связей f(GC) между объектами GC1 и GC2. Для каждой дуги E осуществляется попытка создания правила достраивания. В настоящее время строятся только правила восполнения [2], как наиболее полные и универсальные (в конструирующем режиме они способны достроить как связь между существующими объектами, так и отсутствующие объекты вместе со связями, а в проверочном режиме данные правила позволяют проконтролировать наличие объектов и требуемых связей).
Алгоритм составления каждого правила вполне тривиален, поскольку строятся только те типы связей, которые присутствуют между объектами классов, входящих в обучающую выборку, причем вся необходимая информация о структуре таких связей известна заранее (определена в спецификациях порождающих классов текущей предметной области). Необходимо учитывать лишь следующие обстоятельства:
а) если предполагается возможность создание правилом нового объекта, то необходимо позаботиться о корректном заполнении его полей в конструирующем режиме – для этого проводится анализ текущих экземпляров связи E = (C1, C2). Сначала определяется, какой из двух объектов текущего экземпляра связи может быть выведен из значений полей объекта-партнера. У каждого из этих объектов подсчитывается количество M полей, для которых может быть записана общая схема заполнения, состоящая из констант и значений полей объекта-партнера (схема составляется по принципам, схожим с аналогичными принципами для индукции распознающих скриптов). Ведущим (опорным) становится объект с меньшим M (при этом, если у ведомого k-го объекта Mk < Nk, где Nk – число полей объекта класса Ck, то правило формируется в проверочно-неконструирующей форме). Если таких ведущих объектов у связи E определить не удается, то она признается невыводимой и процесс завершается неудачей. Если на роль ведущего претендуют оба объекта, то используется эвристический прием: ведущим становится объект с большей степенью соответствующей вершины в сети классов. Как только определены ведущий объект и схема заполнения полей его объекта-партнера по связи, в правило достраивания объекта-партнера включаются соответствующие конструктивные условия вида «@поле = выражение», где выражение является константным или ссылается на поля парного объекта и другие константы (для соединения частей выражения может использоваться стандартная XPath-функция concat);
б) контакт некоторого типа определяется в одном классе и может наследоваться в его классах-потомках. Это создает некоторые сложности при определении правил. Пусть в экземплярах связи типа E = (С1, С2) ведущими являются объекты классов g(C1), а ведомыми (конструируемыми) являются объекты классов g(C2), где функция g(X) возвращает множество, включающее класс X и его потомков. Тогда для каждого из классов, входящих в g(С2), необходимо записать отдельный экземпляр правила с данным конкретным классом. В то же время для ведущего объекта, напротив, целесообразно записать класс общего предка (ближайшего по иерархии) всех g(C1);
в) веса правил, создающих какую-либо связь типа E, можно определить пропорционально количеству существующих экземпляров такой связи.
Рассмотрим пример из той же предметной области «Простая обработка векторных данных». Пусть обучающая выборка содержит элементы:
(GС1, S1) = ((IVar = «V»; Op = «min»; OVar = «min»; ID = «minVmin»), «Найдем минимум вектора V и поместим результат в скаляр min.»);
(GС3, S3) = ((IVar = «V»; ID = «outmin»), «Выведем скаляр min на экран»);
(GС4, S4) = ((Size = «10»; ID = «V»), «Введем вектор V из 10 элементов»);
(GС5, S5) = ((ID = «min»), «Введем скаляр min»).
Здесь подразумевается, что если аргументом операции поиска минимума является вектор V, то должен существовать декларирующий его объект, который должен быть связан с операцией поиска минимума. Аналогично, должен существовать объект, декларирующий скаляр min, если данный скаляр выводится на экран.
Можно получить набор правил достраивания, фрагмент которых показан далее:
+{6.75} [/OBJS/clsSimpleScalar[@ID != #/@ID and @ID = #/@IVar]/O[@ID="Handle"]/Link[@Code = ##/@Ref]]=>[/OBJS/clsSimpleBlock[@ID != ""]/I[@ID="Arg"]].
+{6.75} [/OBJS/clsSimpleVector[@ID != #/@ID and @ID = #/@IVar]/O[@ID="Handle"]/Link[@Code = ##/@Ref]]=>[/OBJS/clsSimpleBlock[@ID != ""]/I[@ID="Arg"]].
Два приведенных правила утверждают:
1. Необходимость существования объектов (если они не существуют, то будут созданы) класса clsSimpleScalar (скаляр) или clsSimpleVector (вектор), если существует некая обрабатывающая их операция класса clsSimpleBlock с аргументом-контактом Arg. Создаваемые объекты получат идентификаторы ID, равные значениям полей IVar объектов класса clsSimpleBlock.
2. Необходимость существования связи (если она не существует, то будет создана) между контактом Handle декларирующих объектов классов clsSimpleScalar/clsSimpleVector и контактом Arg обрабатывающего объекта класса clsSimpleBlock в случае, если поле IVar обрабатывающего объекта равняется идентификатору ID декларирующего объекта.
Дополнительно отметим, что в данном случае имело место обстоятельство (б) (см. выше), поскольку в обучающей выборке присутствовали связи классов clsSimpleVector=>clsSimpleMat и clsSimpleScalar=>clsSimpleOut, которые формально относятся к единому типу clsSimpleVar=>clsSimpleBlock. При этом для ведущих объектов классов clsSimpleMat и clsSimpleOut в вышеприведенных правилах был записан их общий класс-предок clsSimpleBlock, а для ведомых были записаны конкретные классы clsSimpleScalar и clsSimpleVector.
Апробация
Изложенный в данной работе подход к приобретению знаний был реализован в системе PGEN++. Был составлен пример порождающих классов для предметной области «Простая обработка векторных данных», написаны несколько текстовых описаний типичных задач, сопоставленных порождающим соответствующие программы моделям. Эти данные использовались для приобретения знаний о трансформации текстовых постановок задач в порождающие модели, способные сгенерировать решающие программы. Такой процесс индукции занял не более 20 секунд, в результате были порождены распознающие скрипты, справочные и транслирующие CSV-таблицы к ним, набор необходимых XPath-функций и правила достраивания.
Результаты здесь полностью не приводятся ввиду большого объема, фрагменты входных данных, полученных скриптов, функций и правил (с необходимыми пояснениями) содержатся в данной работе выше.
Было показано, что полученные скрипты/таблицы/функции/правила могут успешно использоваться для генерации решающих программ по текстовым постановкам задач на русском языке. Проверка проводилась как по постановкам, использовавшимся при обучении системы, так и по модифицированным.
Приведем примеры текстовых постановок исходных задач:
Задача 1. Ввести скаляр max. Введем вектор V из 10 элементов. Зададим вектор V с клавиатуры. Найдем также максимум вектора V и поместим результат в скаляр max. Вывести скаляр max на экран. А среднее арифметическое считать не будем. Тест: "1 2 3 4 5 6 7 8 9 10" дает "V[0] = V[1] = V[2] = V[3] = V[4] = V[5] = V[6] = V[7] = V[8] = V[9] = max = 10.000000".
Задача 2. Составить программу. Ввести скаляр max. Ввести скаляр min. Введем вектор V из 10 элементов. Зададим вектор V с клавиатуры. Найдем минимум вектора V и поместим результат в скаляр min. Найдем также максимум вектора V и поместим результат в скаляр max. Вывести вектор V на экран. Вывести скаляр min на экран. Вывести скаляр max на экран. А среднее арифметическое считать не будем. Тест: "1 2 3 4 5 6 7 8 9 10" дает "V[0] = V[1] = V[2] = V[3] = V[4] = V[5] = V[6] = V[7] = V[8] = V[9] = V = [1.000000 2.000000 3.000000 4.000000 5.000000 6.000000 7.000000 8.000000 9.000000 10.000000 ] min = 1.000000 max = 10.000000".
Были получены абсолютно корректные выходные (решающие) программы, однако следует отметить, что автоматически порожденные правила работали несколько медленнее аналогичных, составленных вручную. Это объясняется двумя факторами:
а) процесс генерации порождающей модели основан на алгоритме, реализующим вариант прямого логического вывода с вероятностно управляемым порядком перебора правил. При этом различные виды правил, приводящие к одному и тому же результату, могут давать существенно отличающиеся по мощности множества вариантов, соответственно более удачный выбор правил может давать меньший объем перебора (и, соответственно, меньшее время вывода) в сравнении с менее удачным набором правил;
б) автоматически составленные правила не содержали более эффективных правил восполнения с отношением строгого следования «=>>» (в настоящее время автоматическое составление таких правил не поддерживается), которые позволяют уменьшить размерность пространства состояний и существенно ускорить процесс генерации программы по описанию.
В целом, среднее время трансформации (при реализованном в настоящее время алгоритме управляемого прямого логического вывода) можно приблизительно оценить как пропорциональное не менее чем произведению количества используемых правил на количество предложений в постановке задачи.
Выводы
Итак, в данной работе получены следующие основные результаты:
1. На основании анализа литературных источников выбран комбинированный подход к приобретению знаний о преобразовании естественно-языковых постановок задач в соответствующие решающие программы.
2. В рамках формализма объектно-событийных моделей впервые предложен механизм генерации скриптов, распознающих первичные объекты моделей, описаны основные моменты их получения.
3. В рамках формализма объектно-событийных моделей впервые предложен механизм генерации правил восполнения/достраивания первичных моделей до полных смысловых моделей, способных генерировать решающие программы.
4. Важным позитивным отличием предложенных решений является полное отсутствие необходимости в ручном составлении какой-либо части правил преобразования постановок в DSL(XML)-модели программ. Вручную составляются только правила генерации решающих программ по DSL(XML)-моделям.
5. Полученные решения успешно апробированы на предметной области «Простая обработка векторных данных», позитивные результаты получены как на обучающей выборке, так и на примерах, не входящих в выборку.
Библиография
1. Зубков В.П., Назаретский С.П. IPGS — интеллектуальная система автоматизированного программирования// Инф. среда вуза: Сб. ст. Иваново: ИГАСА, 2000. С.213-215.
2. Пекунов В.В. Элементы XPath-подобных языков в задачах построения смысловых XML-моделей текстов на естественном языке // Кибернетика и программирование. — 2020.-№ 1.-С.29-41. DOI: 10.25136/2644-5522.2020.1.32143. URL: https://e-notabene.ru/kp/article_32143.html
3. Пекунов В. В. Новые методы параллельного моделирования распространения загрязнений в окрестности промышленных и муниципальных объектов : дис. ... д-ра техн. наук. Иваново, 2009. 274 с.
4. Raza M., Gulwani S., MilicFrayling N. Compositional program synthesis from natural language and examples // Proceedings of IJCAI, 2015. P.792-800.
5. Yin P., Neubig G. A syntactic neural model for general-purpose code generation // Proceedings of ACL. Vancouver: ACL, 2017. P.440–450.
6. Gvero T., Kuncak V. Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). Florence: IEEE, 2015. P.689-692. DOI: 10.1109/ICSE.2015.224.
7. Wong E., Yang J., and Tan L., Autocomment: Mining question and answer sites for automatic comment generation // Proc. ASE. Silicon Valley: IEEE, 2013. P.562–567.
8. Mandal S., Naskar S. Natural Language Programing with Automatic Code Generation towards Solving Addition-Subtraction Word Problems // Proceedings of 14th International Conference on Natural Language Processing (December, 2017). Jadavpur University, 2017. P.146-154.
9. Oda Y., Fudaba H., Neubig G. et al. Learning to Generate Pseudo-code from Source Code using Statistical Machine Translation // 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015. P.574-584.
10. Clark S., Curran J.R. Widecoverage efficient statistical parsing with CCG and log-linear models // Computational Linguistics 33(4), 2007. P.493–552.
11. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar/ (дата обращения: 14.09.2020).
References
1. Zubkov V.P., Nazaretskii S.P. IPGS — intellektual'naya sistema avtomatizirovannogo programmirovaniya// Inf. sreda vuza: Sb. st. Ivanovo: IGASA, 2000. S.213-215.
2. Pekunov V.V. Elementy XPath-podobnykh yazykov v zadachakh postroeniya smyslovykh XML-modelei tekstov na estestvennom yazyke // Kibernetika i programmirovanie. — 2020.-№ 1.-S.29-41. DOI: 10.25136/2644-5522.2020.1.32143. URL: https://e-notabene.ru/kp/article_32143.html
3. Pekunov V. V. Novye metody parallel'nogo modelirovaniya rasprostraneniya zagryaznenii v okrestnosti promyshlennykh i munitsipal'nykh ob''ektov : dis. ... d-ra tekhn. nauk. Ivanovo, 2009. 274 s.
4. Raza M., Gulwani S., MilicFrayling N. Compositional program synthesis from natural language and examples // Proceedings of IJCAI, 2015. P.792-800.
5. Yin P., Neubig G. A syntactic neural model for general-purpose code generation // Proceedings of ACL. Vancouver: ACL, 2017. P.440–450.
6. Gvero T., Kuncak V. Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). Florence: IEEE, 2015. P.689-692. DOI: 10.1109/ICSE.2015.224.
7. Wong E., Yang J., and Tan L., Autocomment: Mining question and answer sites for automatic comment generation // Proc. ASE. Silicon Valley: IEEE, 2013. P.562–567.
8. Mandal S., Naskar S. Natural Language Programing with Automatic Code Generation towards Solving Addition-Subtraction Word Problems // Proceedings of 14th International Conference on Natural Language Processing (December, 2017). Jadavpur University, 2017. P.146-154.
9. Oda Y., Fudaba H., Neubig G. et al. Learning to Generate Pseudo-code from Source Code using Statistical Machine Translation // 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015. P.574-584.
10. Clark S., Curran J.R. Widecoverage efficient statistical parsing with CCG and log-linear models // Computational Linguistics 33(4), 2007. P.493–552.
11. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar/ (data obrashcheniya: 14.09.2020).
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования – разработка правил трансформации естественно-языковых описаний задачи (на русском языке) в решающий программный код.
Методология исследования основана на сочетании теоретического и эмпирического подходов с применением методов моделирования, обобщения, сравнения, анализа, синтеза и алгоритмизации, вычислительного эксперимента.
Актуальность исследования определяется всё более широким применением интеллектуальных информационных систем в различных отраслях экономики и, соответственно, необходимостью изучения и проектирования соответствующего алгоритмического и программного обеспечения, включая правила трансформации естественно-языковой постановки задачи в решающий программный код.
Научная новизна связана с обоснованием автором в рамках формализма объектно-событийных моделей механизма генерации скриптов, распознающих первичные объекты моделей, а также генерации правил восполнения / достраивания первичных моделей до полных смысловых моделей, способных генерировать решающие программы. Отличием предложенных решений является отсутствие необходимости в ручном составлении правил преобразования постановок в DSL(XML)-модели.
Статья написана русским литературным языком. Стиль изложения научный.
Структура рукописи включает следующие разделы: Введение (технологии искусственного интеллекта, разработка естественно-языковых интерфейсов, задача автоматической генерации программного кода, система порождения, идентификации и преобразования программ PGEN++, основные подходы к приобретению знаний, комбинированный подход, системы класса DSL (Domain Specific Language), цель и задачи работы), Общее описание процесса преобразования естественно-языковой постановки задачи в решающий программный код (двухстадийная схема преобразования естественно-языковой постановки задачи в программный код, индукция распознающих скриптов для каждого класса текущей предметной области, индукция правил достраивания и трансформации), Индукция распознающих скриптов (выходные данные, построение распознающих скриптов, применение простых элиминативно-индукционных методов, библиотека грамматического разбора link-grammar, распознающий скрипт для класса «Обработка векторных данных» предметной области «Простая обработка векторных данных»), Индукция правил достраивания и трансформации (выходные данные, набор классов, создание правил достраивания, пример из предметной области «Простая обработка векторных данных», набор правил достраивания), Апробация (система PGEN++, пример порождающих классов для предметной области «Простая обработка векторных данных», текстовые описания типичных задач, приобретение знаний о трансформации текстовых постановок задач в порождающие модели, способные сгенерировать решающие программы, процесс индукции, распознающие скрипты, справочные и транслирующие CSV-таблицы к ним, набор необходимых XPath-функций и правила достраивания), Выводы (заключение), Библиография.
Раздел «Введение» следует озаглавить. Текст включает два рисунка. Содержимое рисунков может быть представлено простым текстом.
Содержание в целом соответствует названию. В разделе Апробация» следует привести примеры зада на естественном языке, для которых проводилась трансформация в порождающие модели, способные сгенерировать решающие программы. Не ясно также, каким образом время выполнения трансформации зависит от типа и сложности задачи.
Библиография включает 11 источников отечественных и зарубежных авторов – научные статьи, материалы научных мероприятий, диссертации. Библиографические описания некоторых источников следует скорректировать в соответствии с ГОСТ и требованиями редакции.
3. Пекунов В. В. Новые методы параллельного моделирования распространения загрязнений в окрестности промышленных и муниципальных объектов : дис. … д-ра техн. наук. Иваново, 2009. 274 с.
4. Raza M., Gulwani S., MilicFrayling N. Compositional program synthesis from natural language and examples // Proceedings of IJCAI, 2015. № ???. P. 792–800.
6. Gvero T., Kuncak V. (2015). Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). Место издания??? : Наименование издательства ???, Год издания ???. P. 689–692.
11. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar.
Апелляция к оппонентам (Зубков В. П., Назаретский С. П., Пекунов В. В., Raza M., Gulwani S., MilicFrayling N., Yin P., Neubig G., Gvero T., Kuncak V., Wong E., Yang J., Tan L., Mandal S., Naskar S., Oda Y., Fudaba H., Clark S., Curran J. R. и др.) имеет место.
В целом рукопись соответствует основным требованиям, предъявляемым к научным статьям. Материал представляет интерес для читательской аудитории и после доработки может быть опубликован в журнале «Программные системы и вычислительные методы».
|
 Рус
Рус











