|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Глазкова А.В.
Статистическая оценка информативности признаков для задачи поиска семантически близких предложений
// Программные системы и вычислительные методы.
2020. № 1.
С. 8-17.
DOI: 10.7256/2454-0714.2020.1.31728 URL: https://nbpublish.com/library_read_article.php?id=31728
Статистическая оценка информативности признаков для задачи поиска семантически близких предложений
Глазкова Анна Валерьевна
кандидат технических наук
старший преподаватель, кафедра программного обеспечения, Тюменский государственный университет
625007, Россия, Тюменская область, г. Тюмень, ул. Проезд 9 Мая, 7, оф. 94
Glazkova Anna Valer'evna
PhD in Technical Science
Senior Lecturer, Department of Software, Tyumen State University
625007, Russia, Tyumenskaya oblast', g. Tyumen', ul. Proezd 9 Maya, 7, of. 94

|
anna_glazkova@yahoo.com
|
|
 |
|
DOI: 10.7256/2454-0714.2020.1.31728
Дата направления статьи в редакцию:
15-12-2019
Дата публикации:
05-03-2020
Аннотация:
В работе представлены результаты оценки информативности количественных и бинарных признаков для решения задачи поиска семантически близких предложений (парафразов). Рассмотрены три типа признаков: построенные на векторных представлениях слов (по модели Word2Vec), основанные на извлечении чисел и структурированной информации и отражающие количественные характеристики текста. В качестве показателей информативности используются доля парафразов среди примеров, обладающих признаком, и доля парафразов, обладающих признаком (для бинарных характеристик), а также оценки с помощью метода накопленных частот (для количественных признаков). Оценка проведена на русском корпусе парафразов. Набор рассмотренных в работе признаков апробирован в качестве входных данных для двух моделей машинного обучения для определения семантически близких предложений: машины опорных векторов (SVM) и рекуррентной нейросетевой модели. Первая модель принимает в качестве входных параметров только рассмотренный набор признаков, вторая – текст в виде последовательностей (sequences) и набор признаков в качестве дополнительного входа. Качество моделей составило соответственно 67,06% (по F-мере) и 69,49% (по точности) и 79,85% (по F-мере) и 74,16% (по точности). Полученный в работе результат сравним с лучшими результатами систем, представленных в 2017 на соревновании по определению парафраза для русского языка (второй результат по F-мере, третий результат по точности). Результаты, предложенные в работе, могут быть использованы как при реализации моделей поиска семантически близких фрагментов текстов на естественном языке, так и для анализа русскоязычных парафразов с точки зрения компьютерной лингвистики.
Ключевые слова:
семантическая близость, классификация текстов, поиск парафразов, нейронная сеть, машина опорных векторов, информативность признаков, накопленные частоты, статистическая оценка, отбор признаков, машинное обучение
Работа выполнена при финансовой поддержке РФФИ (проект №18-37-00272).
Abstract: The paper presents the results of evaluating the informative value of quantitative and binary signs to solve the problem of finding semantically close sentences (paraphrases). Three types of signs are considered in the article: those built on vector representations of words (according to the Word2Vec model), based on the extraction of numbers and structured information and reflecting the quantitative characteristics of the text. As indicators of information content, the percentage of paraphrases among examples with a characteristic, and the percentage of paraphrases with a attribute (for binary characteristics), as well as estimates using the accumulated frequency method (for quantitative indicators) are used. The assessment was conducted on the Russian paraphrase corps. The set of features considered in the work was tested as input for two machine learning models for defining semantically close sentences: reference vector machines (SVMs) and a recurrent neural network model. The first model accepts only the considered set of signs as input parameters, the second - the text in the form of sequences and the set of signs as an additional input. The quality of the models was 67.06% (F-measure) and 69.49% (accuracy) and 79.85% (F-measure) and 74.16% (accuracy), respectively. The result obtained in the work is comparable with the best results of the systems presented in 2017 at the competition for the definition of paraphrase for the Russian language (the second result for the F-measure, the third result for accuracy). The results proposed in the work can be used both in the implementation of search models for semantically close fragments of texts in natural language, and for the analysis of Russian-language paraphrases from the point of view of computer linguistics.
Keywords: semantic similarity, text classification, paraphrase detection, neural network, support vector machine, feature informativeness, accumulated frequencies, statistical evaluation, feature selection, machine learning
Введение
Анализ семантической близости текстов является актуальной задачей искусственного интеллекта и компьютерной лингвистики. Данная работа посвящена проблеме бинарной классификации предложений с точки зрения их семантического сходства, то есть определения парафразов – фраз, имеющих близкое семантическое значение, но отличающихся в лексическом плане. Механизмы анализа семантической схожести находят применение в ряде актуальных практических приложений: от систем поиска заимствований до инструментов оценки уникальности контента интернет-сайтов.
Существует достаточно много работ, посвященных определению парафраза в англоязычных текстах (например, [1-7]). Большинство современных подходов используют методы машинного обучения, в частности, метод опорных векторов и нейронные сети (преимущественно сверточные [3] и сети долгой краткосрочной памяти [4-6], а также комбинации этих подходов [7]). Данные методы требуют построения репрезентативной обучающей выборки и ее качественной предобработки для получения информативного набора классификационных признаков.
Семантическая близость текстов может проявляться на разных уровнях языка, поэтому подходы к определению парафраза должны учитывать влияние широкого спектра морфологических, лексических и синтаксических характеристик на степень сходства предложений. Для этого в работах [8-10] были предложены наборы признаков, основанных на оценке количества одинаковых слов в предложении, выявлении совпадающих именованных сущностей, оценке семантической близости слов. Оценка семантической близости может быть проведена как с помощью словарей, так и с использованием векторных представлений слов [11-13] – подходов к моделированию естественного языка, заключающихся в сопоставлении словам или фразам вещественных векторов фиксированной размерности. Идея построения векторных представлений слов основана на дистрибутивной семантике, согласно которой семантически близкие слова часто встречаются в сходном контексте [14]. В настоящее время векторные представления слов (Word2Vec, GloVE, FastText и др.) являются основой обучения систем обработки естественного языка.
Цель исследования
Целью данной статьи является оценка информативности бинарных и количественных признаков для модели поиска семантически близких предложений в тексте на русском языке.
На основании анализа существующих научных работ, в статье рассмотрены три типа признаков, основанных на:
- векторных представлениях слов (расстояние между векторами, являющимися суммами векторных представлений всех слов в предложении; расстояние между суммами векторных представлений отдельных частей речи: глаголов, существительных);
- извлечении чисел и структурированных сущностей: именованных сущностей, аббревиатур, дат (присутствие в предложениях одинаковых чисел и структурированных сущностей, наличие различающихся чисел и структурированных сущностей, присутствие чисел и сущностей в одном предложении из пары);
- количественных характеристиках текста (доля совпадающих слов, доля совпадающих лемматизированных слов, разница между длинами предложений по количеству слов).
Данные
Оценка информативности проведена на материалах русскоязычного корпуса парафразов [15]. В 2017 году на данных корпуса было проведено соревнование [16] по определению парафразов в парах русских предложений. На соревновании были продемонстрированы подходы с использованием правил [17], машины опорных векторов [18-19], градиентного бустинга [20] и сверточных нейронных сетей [21].
Русский корпус парафразов состоит из заголовков новостных статей. Один пример представляет собой пару предложений, являющихся или не являющихся парафразами друг относительно друга. Разметка пар предложений по степени семантической близости была проведена с помощью экспертной оценки. Количество примеров в части корпуса, предназначенной для обучения классификатора, – 9809 пар семантически несхожих заголовков и 4645 примеров парафраз. Тестовая выборка состоит из 6000 примеров.
Методы оценки
В работе рассматриваются классификационные признаки, значения которых представлены в бинарной и количественной шкалах. В качестве меры информативности бинарных признаков были оценены два показателя:
с1=Pp/(Pp+Np) – доля парафразов среди всех примеров, обладающих признаком, где Pp и Np – количество семантически схожих и несхожих пар соответственно среди примеров, имеющих значение признака, равное 1;
c2=Pp/(Pp+Pn) – доля парафразов, обладающих признаком, где Pp и Pn – количество парафразов, имеющих соответственно значение признака, равное 1 и 0.
Первый показатель характеризует непосредственно значимость данного признака при решении задачи определения класса объекта, второй демонстрирует распространенность данного признака в рамках класса парафразов и позволяет сделать вывод о репрезентативности выборки примеров, обладающих признаком.
Оценка количественных признаков проводилась при помощи метода накопленных частот [22-24]. Суть метода накопленных частот состоит в следующем.
1. Формируются две равные по количеству примеров выборки значений признака f, принадлежащие классам P и N соответственно.
2. Весь интервал распределения признака делится на m отрезков и для каждого класса высчитывается, сколько раз признак принимает значение из каждого интервала.
3. На основе эмпирических распределений признака f подсчитываются накопленные частоты (то есть сумма частот от начального до текущего интервала распределения).
4. Оценка информативности признака f вычисляется как модуль максимальной разности накопленных частот в выборках из примеров из классов P и N.
Пример. Пусть имеются выборки объектов двух классов P и N, состоящие из 100 примеров. Признак f распределен в 5 числовых отрезках следующим образом:
fP=(10,50,40,0,0),
fN=(0,0,0,40,60).
Накопленные частоты на основе эмпирических распределений признака f:
f'P=(10,60,100,100,100),
f'N=(0,0,0,40,100).
Максимальная по модулю разность накопленных частот равна 100 (на интервале 3). В целях масштабирования итоговая оценка может быть разделена на размер выборки: If=100/100=1. Исходя из полученной оценки, можно сделать вывод о том, что при условии репрезентативности рассмотренных выборок признак fявляется информативным на 100% (If=1). Очевидно, что в приведенном примере значения признака fдостаточно для проведения классификации по классам P и N: если значение признака для некоторого объекта попадает в 3 первых интервала, то объект относится к классу P, в противном случае – к классу N.
Эксперимент и результаты
Извлечение и оценка информативности признаков проводились с помощью средств языка программирования Python 3.6 и свободно распространяемых библиотек:
- Natasha – для извлечения именованных сущностей, дат и денежных сумм;
- Pandas и NumPy – для предобработки данных;
- Gensim – для работы с векторными представлениями слов.
Оценка информативности проводилась на 9290 примерах (4645 пар семантически схожих предложений + 4645 случайных пар семантически несхожих предложений). Таким образом, в экспериментах использовалось равное количество примеров обоих классов.
В таблице 1 представлены результаты оценки бинарных признаков. Признаки в таблице упорядочены по частоте их выраженности в классе парафразов (по столбцу 3). В таблице приведены признаки, для которых доля парафразов, обладающих признаком, превышает 0.01. Степени выраженности бинарных признаков обусловлены спецификой корпуса, взятого для анализа. Поскольку русскоязычный корпус парафразов состоит из новостных заголовков, для него типично использование именованных сущностей. Так, 49,97% парафразов в корпусе содержат одинаковые географические названия.
Таблица 1. Оценка выраженности бинарных признаков
|
Признак
|
Доля парафразов среди примеров, обладающих признаком
|
Доля парафразов, обладающих признаком
|
|
Одинаковые географические названия
|
0.8245
|
0.4997
|
|
Разные географические названия
|
0.203
|
0.1821
|
|
Географические названия в одном предложении из пары
|
0.2434
|
0.1404
|
|
Одинаковые аббревиатуры
|
0.8666
|
0.1356
|
|
Одинаковые личные имена
|
0.788
|
0.116
|
|
Аббревиатуры в одном предложении из пары
|
0.2934
|
0.1128
|
|
Числа в одном предложении из пары
|
0.268
|
0.0928
|
|
Одинаковые числа
|
0.9245
|
0.0844
|
|
Личные имена в одном предложении из пары
|
0.2323
|
0.0762
|
|
Разные числа
|
0.5277
|
0.039
|
|
Денежные суммы в одном предложении из пары
|
0.3041
|
0.0239
|
|
Даты в одном предложении из пары
|
0.2539
|
0.0177
|
Результаты оценки количественных признаков с помощью метода накопленных частот приведены в таблице 2. В ходе экспериментов в данной работе использовалось количество интервалов m=10, итоговая оценка по методу накопленных частот была разделена на размер выборки в целях приведения значения к диапазону [0;1] для большей наглядности полученных результатов. Наибольшую информативность продемонстрировали признаки, характеризующие расстояние между суммами векторных представлений слов и долю совпадающих словоформ в предложениях.
Для вычисления значений признаков, основанных на векторных представлениях слов, была использована модель Word2Veс [25], обученная с помощью алгоритма Skipgram на текстах русскоязычной Википедии за 2018 год.
Таблица 2. Оценка количественных признаков с помощью накопленных частот
|
Признак
|
Значение
|
|
Расстояние между суммами векторов, характеризующих предложения
|
0.7662
|
|
Доля совпадающих словоформ
|
0.7386
|
|
Доля совпадающих лемматизированных слов
|
0.6903
|
|
Расстояние между суммами векторных представлений существительных
|
0.6678
|
|
Расстояние между суммами векторных представлений глаголов
|
0.5247
|
|
Разница в длине предложений
|
0.2118
|
Полученный набор признаков был протестирован на задаче поиска парафразов. В таблице 3 приводится сравнение трех моделей:
1) машина опорных векторов, обученная на наборе количественных и бинарных признаков, представленных в таблицах 1-2;
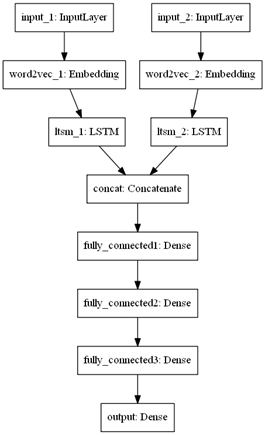
2) рекуррентная нейронная сеть с LSTM-слоями (долгой краткосрочной памяти, long short-term memory), основанная на "сиамской" архитектуре [5], структура сети представлена на рисунке 1;
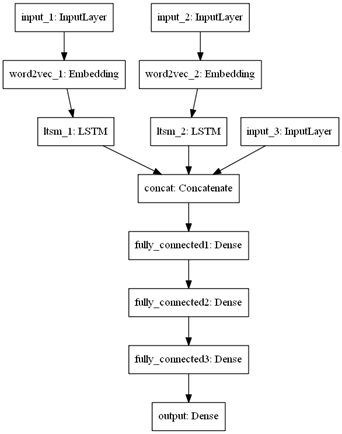
3) нейронная сеть, комбинирующая рекуррентную сеть с сетью прямого распространения (рисунок 1). Вход сети, обозначенный "input_3", предназначен для дополнительных признаков.
Таблица 3. Результаты классификации
|
Признаки
|
Модель
|
F-мера (%)
|
Точность (accuracy, %)
|
|
Количественные и бинарные признаки
|
Машина опорных векторов
|
67,02
|
69,49
|
|
Векторные представления слов
|
Рекуррентная нейронная сеть (LSTM)
|
72,53
|
70,87
|
|
Векторные представления слов + количественные признаки
|
Рекуррентная нейронная сеть (LSTM)
|
79,85
|
74,16
|
Для реализации моделей машинного обучения использовались библиотеки Scikit-learn (машина опорных векторов) и Keras (нейронные сети). Количество нейронов в рекуррентных слоях и в слоях прямого распространения выбрано экспериментально и равно 128. Функция активации нейронов на внутренних слоях – гиперболический тангенс, на выходном слое – softmax. В качестве оптимизационного алгоритма использован adaptive moment estimation (Adam Optimizer).
Показатели третьей модели сравнимы по качеству с результатами, продемонстрированными системами – участниками соревнования [16] (второй результат по F-мере и третий по точности). Использование рассмотренного в работе набора бинарных и количественных признаков в качестве дополнительных входных данных нейронной сети позволило улучшить качество рекуррентной сети более чем на 7% по F-мере и более чем на 3% по точности. Таким образом, набор дополнительных классификационных признаков поспособствовал увеличению эффективности рекуррентной нейросетевой модели.
Рисунок 1. Архитектура нейросетевых моделей: слева – модель 2, справа – модель 3.
Заключение
В рамках данной работы проведена оценка информативности признаков для определения семантически близких предложений на примере русского языка. Оценки получены для русского корпуса парафразов, содержащего тексты новостных заголовков. Результаты позволяют выявить наиболее значимые признаки для построения классификатора коротких текстов по степени их семантической близости, однако значение информативности ряда признаков (особенно бинарных характеристик, связанных с извлечением структурированной информации) обусловлено спецификой текстов корпуса.
Рассмотренные признаки протестированы в качестве дополнительных входных данных нейросетевой модели для определения парафразов. Полученная модель демонстрирует достаточно высокое качество классификации в сравнении с существующими системами определения парафразов в текстах на русском языке.
Библиография
1. El Desouki M. I., Gomaa W. H. Exploring the Recent Trends of Paraphrase Detection //International Journal of Computer Applications. – 2019. – Т. 975. – С. 8887. DOI: https://doi.org/10.5120/ijca2019918317.
2. Smerdov A. N., Bakhteev O. Y., Strijov V. V. Optimal recurrent neural network model in paraphrase detection⇤ //Informatika i Ee Primeneniya [Informatics and its Applications]. – 2018. – Т. 12. – №. 4. – С. 63-69. DOI: https://doi.org/10.14357/19922264180409.
3. Yin W., Schütze H. Convolutional neural network for paraphrase identification //Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. – 2015. – С. 901-911. DOI: https://doi.org/10.3115/v1/n15-1091.
4. Neculoiu P., Versteegh M., Rotaru M. Learning text similarity with siamese recurrent networks //Proceedings of the 1st Workshop on Representation Learning for NLP. – 2016. – С. 148-157. DOI: https://doi.org/10.18653/v1/w16-1617.
5. Dien D. et al. Vietnamese-English Cross-Lingual Paraphrase Identification Using Siamese Recurrent Architectures //2019 19th International Symposium on Communications and Information Technologies (ISCIT). – IEEE, 2019. – С. 70-75. DOI: https://doi.org/10.1109/iscit.2019.8905116.
6. Reddy D. A., Kumar M. A., Soman K. P. LSTM based paraphrase identification using combined word embedding features //Soft Computing and Signal Processing. – Springer, Singapore, 2019. – С. 385-394. DOI: https://doi.org/10.1007/978-981-13-3393-4_40.
7. Agarwal B. et al. A deep network model for paraphrase detection in short text messages //Information Processing & Management. – 2018. – Т. 54. – №. 6. – С. 922-937. DOI: https://doi.org/10.1016/j.ipm.2018.06.005.
8. Das D., Smith N. A. Paraphrase identification as probabilistic quasi-synchronous recognition //Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. – Association for Computational Linguistics, 2009. – С. 468-476. DOI: https://doi.org/10.3115/1687878.1687944.
9. Vo N. P. A., Magnolini S., Popescu O. Paraphrase identification and semantic similarity in twitter with simple features //Proceedings of the third International Workshop on Natural Language Processing for Social Media. – 2015. – С. 10-19. DOI: https://doi.org/10.3115/v1/w15-1702.
10. Nagatsuka K., Atsumi M. Paraphrase Identification for Twitter by Co-Training Based on Words and Characters //2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19th International Symposium on Advanced Intelligent Systems (ISIS). – IEEE, 2018. – С. 1448-1452. DOI: https://doi.org/10.1109/scis-isis.2018.00227.
11. Yan F., Fan Q., Lu M. Improving semantic similarity retrieval with word embeddings //Concurrency and Computation: Practice and Experience. – 2018. – Т. 30. – №. 23. – С. e4489. DOI: https://doi.org/10.1002/cpe.4489.
12. Jurdzinski G. et al. Word embeddings for morphologically complex languages //Schedae Informaticae. – 2017. – Т. 2016. – №. Volume 25. – С. 127-138. DOI: https://doi.org/10.4467/20838476si.16.010.6191.
13. Li Y., Yang T. Word embedding for understanding natural language: a survey //Guide to Big Data Applications. – Springer, Cham, 2018. – С. 83-104. DOI: https://doi.org/10.1007/978-3-319-53817-4_4.
14. Camacho-Collados J., Pilehvar M. T. From word to sense embeddings: A survey on vector representations of meaning //Journal of Artificial Intelligence Research. – 2018. – Т. 63. – С. 743-788. DOI: https://doi.org/10.1613/jair.1.11259.
15. Pronoza E., Yagunova E., Pronoza A. 2015. Construction of a Russian paraphrase corpus: unsupervised paraphrase extraction. Russian Summer School in Information Retrieval. St. Petersburg. 146-157. DOI: https://doi.org/10.1007/978-3-319-41718-9_8.
16. Pivovarova L. et al. 2017. ParaPhraser: Russian paraphrase corpus and shared task// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 211-225. DOI: https://doi.org/10.1007/978-3-319-71746-3_18.
17. Boyarsky K., Kanevsky E. 2017. Effect of semantic parsing depth on the identification of paraphrases in Russian texts// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 226-241. DOI: https://doi.org/10.1007/978-3-319-71746-3_19.
18. Loukachevitch N. et al. 2017. RuThes thesaurus in detecting Russian paraphrases// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 242-256. DOI: https://doi.org/10.1007/978-3-319-71746-3_20.
19. Eyecioglu A., Keller B. 2017. Knowledge-lean paraphrase identification using character-based features// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 257-276. DOI: https://doi.org/10.1007/978-3-319-71746-3_21.
20. Kravchenko D. 2017. Paraphrase detection using machine translation and textual similarity algorithms// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 277-292. DOI: https://doi.org/10.1007/978-3-319-71746-3_22.
21. Maraev V. et al.. 2017. Character-level convolutional neural network for paraphrase detection and other experiments// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 293-304. DOI: https://doi.org/10.1007/978-3-319-71746-3_23.
22. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. Новосибирск: Изд-во ИМ СО РАН, 1999. 270 с.
23. Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Классификация и снижение размерности: справочник. М.: Финансы и статистика, 1989. 250 с.
24. Быкова В.В., Катаева А.В. Методы и средства анализа информативности признаков при обработке медицинских данных // Программные продукты и системы. 2016. №2 (114). С. 172-178. DOI: 10.15827/0236-235X.114.172-178.
25. Mikolov T. et al. Distributed representations of words and phrases and their compositionality //Advances in neural information processing systems. – 2013. – С. 3111-3119.
References
1. El Desouki M. I., Gomaa W. H. Exploring the Recent Trends of Paraphrase Detection //International Journal of Computer Applications. – 2019. – T. 975. – S. 8887. DOI: https://doi.org/10.5120/ijca2019918317.
2. Smerdov A. N., Bakhteev O. Y., Strijov V. V. Optimal recurrent neural network model in paraphrase detection⇤ //Informatika i Ee Primeneniya [Informatics and its Applications]. – 2018. – T. 12. – №. 4. – S. 63-69. DOI: https://doi.org/10.14357/19922264180409.
3. Yin W., Schütze H. Convolutional neural network for paraphrase identification //Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. – 2015. – S. 901-911. DOI: https://doi.org/10.3115/v1/n15-1091.
4. Neculoiu P., Versteegh M., Rotaru M. Learning text similarity with siamese recurrent networks //Proceedings of the 1st Workshop on Representation Learning for NLP. – 2016. – S. 148-157. DOI: https://doi.org/10.18653/v1/w16-1617.
5. Dien D. et al. Vietnamese-English Cross-Lingual Paraphrase Identification Using Siamese Recurrent Architectures //2019 19th International Symposium on Communications and Information Technologies (ISCIT). – IEEE, 2019. – S. 70-75. DOI: https://doi.org/10.1109/iscit.2019.8905116.
6. Reddy D. A., Kumar M. A., Soman K. P. LSTM based paraphrase identification using combined word embedding features //Soft Computing and Signal Processing. – Springer, Singapore, 2019. – S. 385-394. DOI: https://doi.org/10.1007/978-981-13-3393-4_40.
7. Agarwal B. et al. A deep network model for paraphrase detection in short text messages //Information Processing & Management. – 2018. – T. 54. – №. 6. – S. 922-937. DOI: https://doi.org/10.1016/j.ipm.2018.06.005.
8. Das D., Smith N. A. Paraphrase identification as probabilistic quasi-synchronous recognition //Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. – Association for Computational Linguistics, 2009. – S. 468-476. DOI: https://doi.org/10.3115/1687878.1687944.
9. Vo N. P. A., Magnolini S., Popescu O. Paraphrase identification and semantic similarity in twitter with simple features //Proceedings of the third International Workshop on Natural Language Processing for Social Media. – 2015. – S. 10-19. DOI: https://doi.org/10.3115/v1/w15-1702.
10. Nagatsuka K., Atsumi M. Paraphrase Identification for Twitter by Co-Training Based on Words and Characters //2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19th International Symposium on Advanced Intelligent Systems (ISIS). – IEEE, 2018. – S. 1448-1452. DOI: https://doi.org/10.1109/scis-isis.2018.00227.
11. Yan F., Fan Q., Lu M. Improving semantic similarity retrieval with word embeddings //Concurrency and Computation: Practice and Experience. – 2018. – T. 30. – №. 23. – S. e4489. DOI: https://doi.org/10.1002/cpe.4489.
12. Jurdzinski G. et al. Word embeddings for morphologically complex languages //Schedae Informaticae. – 2017. – T. 2016. – №. Volume 25. – S. 127-138. DOI: https://doi.org/10.4467/20838476si.16.010.6191.
13. Li Y., Yang T. Word embedding for understanding natural language: a survey //Guide to Big Data Applications. – Springer, Cham, 2018. – S. 83-104. DOI: https://doi.org/10.1007/978-3-319-53817-4_4.
14. Camacho-Collados J., Pilehvar M. T. From word to sense embeddings: A survey on vector representations of meaning //Journal of Artificial Intelligence Research. – 2018. – T. 63. – S. 743-788. DOI: https://doi.org/10.1613/jair.1.11259.
15. Pronoza E., Yagunova E., Pronoza A. 2015. Construction of a Russian paraphrase corpus: unsupervised paraphrase extraction. Russian Summer School in Information Retrieval. St. Petersburg. 146-157. DOI: https://doi.org/10.1007/978-3-319-41718-9_8.
16. Pivovarova L. et al. 2017. ParaPhraser: Russian paraphrase corpus and shared task// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 211-225. DOI: https://doi.org/10.1007/978-3-319-71746-3_18.
17. Boyarsky K., Kanevsky E. 2017. Effect of semantic parsing depth on the identification of paraphrases in Russian texts// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 226-241. DOI: https://doi.org/10.1007/978-3-319-71746-3_19.
18. Loukachevitch N. et al. 2017. RuThes thesaurus in detecting Russian paraphrases// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 242-256. DOI: https://doi.org/10.1007/978-3-319-71746-3_20.
19. Eyecioglu A., Keller B. 2017. Knowledge-lean paraphrase identification using character-based features// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 257-276. DOI: https://doi.org/10.1007/978-3-319-71746-3_21.
20. Kravchenko D. 2017. Paraphrase detection using machine translation and textual similarity algorithms// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 277-292. DOI: https://doi.org/10.1007/978-3-319-71746-3_22.
21. Maraev V. et al.. 2017. Character-level convolutional neural network for paraphrase detection and other experiments// Conference on Artificial Intelligence and Natural Language. – Springer, Cham, 2017. C. 293-304. DOI: https://doi.org/10.1007/978-3-319-71746-3_23.
22. Zagoruiko N.G. Prikladnye metody analiza dannykh i znanii. Novosibirsk: Izd-vo IM SO RAN, 1999. 270 s.
23. Aivazyan S.A., Bukhshtaber V.M., Enyukov I.S., Meshalkin L.D. Prikladnaya statistika: Klassifikatsiya i snizhenie razmernosti: spravochnik. M.: Finansy i statistika, 1989. 250 s.
24. Bykova V.V., Kataeva A.V. Metody i sredstva analiza informativnosti priznakov pri obrabotke meditsinskikh dannykh // Programmnye produkty i sistemy. 2016. №2 (114). S. 172-178. DOI: 10.15827/0236-235X.114.172-178.
25. Mikolov T. et al. Distributed representations of words and phrases and their compositionality //Advances in neural information processing systems. – 2013. – S. 3111-3119.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Статья посвящена поиску и исследованию признаков, используемых для оценки семантической схожести коротких текстов. Достаточно подробно проанализирован предмет исследования, рассмотрены понятия парафраза, семантическая близость текстов, приложения алгоритмов анализа семантической схожести.
Целью работы является оценка информативности различных признаков для модели поиска семантически близких предложений в тексте на русском языке. В качестве признаков рассматриваются: различия в векторных представлениях текстов; присутствие в предложениях одинаковых чисел и структурированных сущностей, наличие различающихся чисел и структурированных сущностей, присутствие чисел и сущностей в одном предложении из пары; доля совпадающих слов, доля совпадающих лемматизированных слов, разница между длинами предложений по количеству слов.
В качестве источника данных рассматривается русскоязычный датасет заголовков новостных статей, включающий пары семантически несхожих заголовков и примеры парафраз. В качестве меры информативности бинарных признаков рассматривались доля парафразов среди всех примеров, обладающих признаком, и доля парафразов, обладающих признаком, оценка количественных признаков проводилась при помощи метода накопленных частот.
В целом работа актуальна, оценка семантической близости парафраз позволяет решать многие важные задачи, такие как группировка схожих новостей в новостных агрегаторах, обнаружение плагиата в текстах на основе простого перефразирования текста.
Научная новизна работы заключается в выявлении и комплексном использовании значимых признаков для решения задачи поиска парафраз.
Статья хорошо структурирована, логически последовательна, выводы и заключение обоснованы. Применяется научный стиль изложения.
Библиографический список состоит из 25 источников, в основном содержит зарубежные источники.
В качестве замечания следует отметить отсутствие обзора признаков, которые использовали участники соревнований и численного сравнения с метриками победителей. Для получения более полных результатов классификации, следует провести сравнение результатов классификации методом опорных векторов с использованием векторных представлений слов и векторных представления слов в сочетании с количественными признаками, т.к. на небольших датасетах классические методы машинного обучения часто показывают лучшие результаты, чем глубокие нейронные сети.
|
 Рус
Рус