|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Пономарев А.В.
Применение вероятностных графических моделей для комплексирования данных в системах масштабных человеко-машинных вычислений
// Программные системы и вычислительные методы.
2019. № 1.
С. 59-69.
DOI: 10.7256/2454-0714.2019.1.29446 URL: https://nbpublish.com/library_read_article.php?id=29446
Применение вероятностных графических моделей для комплексирования данных в системах масштабных человеко-машинных вычислений
Пономарев Андрей Васильевич
кандидат технических наук
старший научный сотрудник, СПИИРАН.
199178, Россия, г. Санкт-Петербург, ул. 14 Линия, 39
Ponomarev Andrei
PhD in Technical Science
Senior Researcher, St. Petersburg Institute of Informatics and Automation of the Russian Academy of Sciences.
199178, Russia, g. Saint Petersburg, ul. 14 Liniya, 39

|
ponomarev@iias.spb.su
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2019.1.29446
Дата направления статьи в редакцию:
05-04-2019
Дата публикации:
26-04-2019
Аннотация:
Статья посвящена проблеме обеспечения качества результатов в системах обработки информации, где часть операций выполняется с привлечением людей, взаимодействие с которыми осуществляется посредством сети Интернет. Подобные системы находят широкое применение при решении различных задач, однако привлечение человека к задачам обработки информации связано с набором принципиальных ограничений, присущих человеку: низкая скорость обработки информации, необходимость мотивации, возможность ошибок или целенаправленного искажения информации. Таким образом, разработка методов и средств управления качеством результатов, получаемых с помощью подобных систем, является актуальной задачей. В статье предлагается модель комплексирования данных для повышения качества результатов, получаемых с помощью масштабных человеко-машинных вычислений. Применение модели рассматривается на примере решения задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов). Оценка эффекта комплексирования производится на основе имитационного моделирования. Результаты исследования предложенного подхода показали, что особенно эффективным является комплексирование в условиях некачественной разметки. Однако даже в условиях качественной разметки, применение комплексирования позволяет увеличить полноту поисковых результатов. В целом, можно заключить, что применение комплексирования данных при обработке результатов человеко-машинных вычислений является перспективным подходом, а применение вероятностных графических моделей для комплексирования позволяет плавно увеличивать точность результатов работы системы с увеличением количества доступной информации.
Ключевые слова:
Крауд-вычисления, Краудсорсинг, Разметка изображений, Аннотирование изображений, Обработка данных, Комплексирование данных, Байесовские сети, Вероятностные графические модели, Коллективный интеллект, Информационный поиск
Работа выполнена при финансовой поддержке РФФИ (грант № 16-37-60107).
Abstract: The article is devoted to the problem of ensuring the quality of results in information processing systems, where some operations are performed with the involvement of people, interaction with whom is carried out via the Internet. Such systems are widely used in solving various tasks, but the involvement of a person in information processing tasks is associated with a set of fundamental limitations inherent in a person: low speed of information processing, the need for motivation, the possibility of errors or purposeful distortion of information. Thus, the development of methods and tools for managing the quality of results obtained with the help of such systems is an urgent task. The article proposes a model of data aggregation to improve the quality of results obtained using large-scale human-machine computing. The application of the model is considered by the example of solving the problem of marking and searching for images obtained as part of mass athletics events (runs). The assessment of the effect of aggregation is carried out on the basis of simulation modeling. The results of the study of the proposed approach have shown that integration is especially effective in conditions of poor-quality markup. However, even in conditions of high-quality markup, the use of aggregation allows you to increase the completeness of search results. In general, it can be concluded that the use of data aggregation in the processing of human-machine computing results is a promising approach, and the use of probabilistic graphical models for aggregation allows you to smoothly increase the accuracy of the results of the system with an increase in the amount of available information.
Keywords: Crowd computing, Crowdsourcing, Image markup, Annotating images, Data processing, Data aggregation, Bayesian networks, Probabilistic graphical models, Collective intelligence, Information search
Введение
Под масштабными человеко-машинными вычислениями (крауд-вычислениями) понимается такая организация процесса сбора и обработки информации, при которой часть операций выполняется с помощью людей, взаимодействие с которыми осуществляется посредством сети Интернет. Системы, включающие элементы масштабных человеко-машинных вычислений (МЧМВ), в настоящее время широко используются для решения самых разных задач (см., например, [1,2,3,4]).
В частности, одним из достаточно распространенных применений этой технологии является аннотирование изображений, то есть снабжение изображений метками, связанными с содержанием этого изображения. Это требуется как при подготовке эталонных наборов данных для машинного обучения [5,6], так и непосредственно в информационно-поисковых системах, поскольку позволяет дополнить алгоритмы обработки изображений алгоритмами текстовой обработки или алгоритмами обработки структурированной и частично структурированной информации.
Вместе с тем, привлечение человека к задачам обработки информации связано с набором принципиальных ограничений, присущих человеку: низкая скорость обработки информации, необходимость мотивации, возможность ошибок или даже целенаправленного искажения информации. В целом, именно неопределенность, связанная с качеством получаемого результата, является одним из факторов, сдерживающих применение МЧМВ.
Проведенный ранее автором статьи обзор методов обеспечения качества в системах МЧМВ [7] позволил сделать вывод о том, что большинство описанных в литературе подходов к обеспечению качества учитывают лишь часть потенциально полезной информации, таким образом, с одной стороны, комплексный подход к проблеме обеспечения качества должен базироваться на сочетании различных методов, с другой – необходимо на единой формальной основе обеспечить сопоставление и использование разных видов доступной информации.
Следует также отметить, что данные, получаемые (и обрабатываемые) в рамках МЧМВ, очень часто являются неточными и для их представления и обработки используются вероятностные модели (например, участнику ставится в соответствие средняя точность, интерпретируемая как вероятность ошибки при выполнении задания или даже матрица вероятностей ошибок; на основе данных, полученных от участников, может быть построено распределение вероятности ответа на предлагавшееся им задание). Таким образом, необходимо обеспечить согласование и комплексирование данных с учетом неопределенности (представляемой, как правило, в терминах теории вероятностей).
Комплексирование данных (data fusion) с использованием вероятностных моделей широко применяется при обработке показаний датчиков и «выведении» из них истинного состояния наблюдаемого объекта [8,9,10]. Нетрудно заметить определенное сходство между этими задачами (обработка сенсоров и обработка данных в МЧМВ) – в обоих случаях с помощью привлечения разнообразных данных, описывающих один и тот же объект/процесс, осуществляется попытка повышения точности его описания.
В статье предлагается модель комплексирования данных для повышения качества результатов, получаемых с помощью МЧМВ. Предлагаемая модель рассматривается на примере решения задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов).
Модель системы разметки изображений
Участие в массовых легкоатлетических пробегах является одним из популярных видов досуга как в России, так и за рубежом [11,12,13,14]. Подобные мероприятия, как правило, фиксируются различными фотографами (как любителями, так и профессионалами), публикующими фотографии в открытом доступе (в альбомах социальных сетей или с помощью специальных интернет-сервисов для публикации фотографий). Очень часто участники пробега оказываются заинтересованы в получении собственных фотографий в качестве сувенира, что привело как к появлению ряда специализированных сервисов продажи спортивных фотографий (Марафон Фото [https://marathon-photo.ru]) так и к тому, что предоставление участнику пробега сделанных организаторами фотографий воспринимается как одна из важных составляющих комплексной информационной поддержки легкоатлетического пробега (Russia Running [https://russiarunning.com]).
Однако поиск фотографий конкретного участника является достаточно трудоемкой задачей, поскольку общее количество фотографий с мероприятия среднего размера, как правило, исчисляется тысячами. К счастью, организация большинства пробегов предполагает, что участники прикрепляют нагрудные номера (являющиеся их уникальными идентификаторами в рамках пробега), что теоретически позволяет перенести поиск от самого заинтересованного участника, любому, кто в состоянии распознавать номера на фотографиях. В частности, наиболее распространенным является подход, в рамках которого фотографии просматриваются вручную и снабжаются метками, в соответствии с тем, участники с какими номерами изображены на каждой фотографии. После этого в размеченной таким образом коллекции изображений становится возможен поиск фотографий по номеру участника. В частности, данный подход широко применяется в существующих коммерческих сервисах продажи фотографий, где разметку осуществляют либо фотографы, либо сотрудники сервиса. Если же речь идет о поиске фотографии среди открытых коллекций, сделанных любителями (не связанными с организаторами пробега или коммерческой площадкой), то осуществление подобной разметки самостоятельно фотографом оказывается слишком трудоемким и для поиска своих фотографий участник пробега вынужден самостоятельно просмотреть все фотографии, опубликованные на различных интернет-сервисах, что, как правило, оказывается нецелесообразно.
Существует несколько работ, в которых предлагаются автоматические решения, использующие технологии компьютерного зрения и OCR для решения этой задачи [15,16], однако в силу того, что нагрудные номера являются гибкими (следовательно, могут быть искажены) и на фотографии могут быть частично закрыты (руками участника или другими участниками пробега) полностью автоматические решения зачастую не обеспечивают желаемого качества распознавания.
Ранее автором был предложен сервис совместной разметки изображений легкоатлетических пробегов (далее просто Сервис), применяющий элементы МЧМВ и позволяющий координировать усилия сообщества (состоящего преимущественно из участников пробега) при разметке коллекции изображений [17]. Предварительные исследования позволили выявить перспективность данного подхода – на ряде крупных легкоатлетических пробегов к разметке удавалось привлечь достаточное количество участников, чтобы осуществить разметку более 7000 изображений, обеспечив возможность быстрого поиска по ним, причем качество разметки (и, соответственно, поиска фотографий) оказывалось достаточно высоким. В данной статье предлагается применить методы комплексирования данных для дальнейшего улучшения качества поиска и снижения трудоемкости разметки.
Упрощенно принцип функционирования Сервиса заключается в следующем. После индексирования коллекций изображений, опубликованных на публичных сервисах, создается множество изображений P. Участникам разметки (множество C) демонстрируются случайные изображения из множества P и предлагается перечислить номера участников пробега, видимые на показанном изображений. Для компенсации ошибок при разметке каждое изображение предлагается нескольким участникам.
Модель комплексирования данных для системы разметки изображений
Дополнительным видом информации, учитываемым предлагаемой моделью комплексирования, является местоположение участника пробега в момент фотографирования. На практике оценка местоположения возможна, поскольку: а) многие участники пробега используют спортивные часы или смартфон с GPS-трекером во время мероприятия, б) протокол мероприятия содержит финишное время каждого участника (и, возможно, время прохождения участником нескольких контрольных точек). Конечно, справедливо ожидать, что точность оценки местоположения участника пробега в случаях (а) и (б) будет существенно варьироваться. Информация о времени и месте съемки, как правило, записывается в атрибуты файла изображения большинством современных камер. Данная информация является очень важной для поиска изображений и для оценки качества участников разметки. Так, информация о том, что участник пробега наверняка находился поблизости от точки съемки в момент фотографирования может быть основанием для включения фотографии в поисковую выдачу само по себе. С другой стороны, информация о том, что участник пробега никак не мог находиться поблизости от точки съемки в момент создания фотографии может использоваться для выявления ошибок разметки.
Как указывалось ранее, точное положение участника на дистанции известно только в определенные моменты времени (в наихудшем случае таких моментов два – старт и финиш, в наилучшем – если участник использует GPS-трекер – его точная позиция на дистанции известна с интервалом в минуту или даже в несколько секунд). Пусть 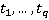 – моменты времени, в которые точно известно положение участника, причем – моменты времени, в которые точно известно положение участника, причем 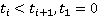 , а , а 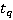 соответствует моменту финиша. Для обозначения положения участника в какой-либо момент времени будем использовать функциональную запись соответствует моменту финиша. Для обозначения положения участника в какой-либо момент времени будем использовать функциональную запись 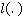 . Введем также обозначение . Введем также обозначение 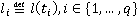 . Допустим, что участник движется только в одном направлении (от старта к финишу), то есть, . Допустим, что участник движется только в одном направлении (от старта к финишу), то есть, 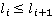 . Для определения положения участника в моменты времени, когда положение неизвестно ( . Для определения положения участника в моменты времени, когда положение неизвестно (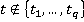 ), будем использовать вероятностную модель, основанную на следующих допущениях: ), будем использовать вероятностную модель, основанную на следующих допущениях:
1) В каждый из моментов времени между 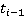 и и 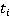 скорость участника является нормально распределенной случайной величиной с математическим ожиданием скорость участника является нормально распределенной случайной величиной с математическим ожиданием 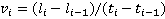 и стандартным отклонением и стандартным отклонением 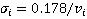 (данное стандартное отклонение получено из работы [18]). (данное стандартное отклонение получено из работы [18]).
2) Скорость движения участника в некоторый момент времени не зависит от скорости движения в другие моменты времени.
Таким образом, с учетом допущения (2), искомая вероятность нахождения участника в момент времени t, 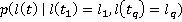 упрощается до упрощается до 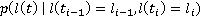 , где , где 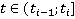 , то есть на искомое распределение оказывают влияние только два известных положения участника. Далее, можно показать, что , то есть на искомое распределение оказывают влияние только два известных положения участника. Далее, можно показать, что 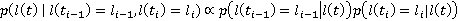 . Вероятности . Вероятности 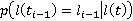 и и 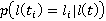 представляют собой вероятности перемещения на расстояние представляют собой вероятности перемещения на расстояние 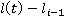 и и 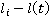 за время за время 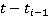 и и 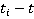 соответственно. При условии, что характер движения удовлетворяет принятым предположениям, данные вероятности распределены в соответствии с нормальным законом соответственно. При условии, что характер движения удовлетворяет принятым предположениям, данные вероятности распределены в соответствии с нормальным законом 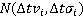 , то есть, их плотность распределения задается следующим выражением: , то есть, их плотность распределения задается следующим выражением:
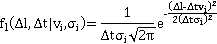
Таким образом, плотность вероятности позиции 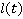 участника на отрезке участника на отрезке 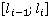 при задается следующим образом: при задается следующим образом:
|
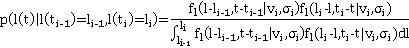
|
(*)
|
Вне отрезка плотность вероятности равна 0.
Полученная плотность вероятности используется для определения вероятности нахождения участника в области видимости камеры в момент совершения снимка. Пусть снимок совершается в момент времени 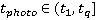 , камера находится в позиции , камера находится в позиции 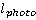 , а расстояние от камеры до объекта, в пределах которого может быть получено качественное изображение – , а расстояние от камеры до объекта, в пределах которого может быть получено качественное изображение – 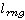 . Для простоты записи положим также, что . Для простоты записи положим также, что 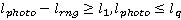 . Тогда вероятность того, что участник пробега будет в области видимости камеры в момент времени . Тогда вероятность того, что участник пробега будет в области видимости камеры в момент времени 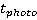 : :
|
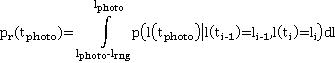
|
(**)
|
Таким образом, общий алгоритм оценки вероятности нахождения участника пробега в точке дистанции в заданный момент времени следующий:
1) Определить сегмент дистанции, на котором участник находится в момент совершения снимка (), то есть, найти такое i, что 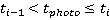 . .
2) Найти функцию плотности вероятности положения участника пробега на данном сегменте (*).
3) Вычислить интеграл (**).
При обработке результатов, получаемых с помощью МЧМВ, широко применяются вероятностные модели участников таких систем, позволяющие численно описать их склонность к совершению разного рода ошибок (см., например, [7]). Например, при совместной разметке изображений возможно совершение ошибок двух видов: 1) неуказание при аннотировании изображения номера участника пробега, в действительности присутствующего на изображении, и 2) указание номера, в действительности не присутствующего на изображении. Как показал опыт эксплуатации сервиса совместной разметки (см. [17, 19]), ошибка вида (1) встречается существенно чаще. Это связано с тем, что во многих случаях участники процесса разметки стараются экономить усилия, указывая в аннотации лишь наиболее очевидные номера. Ошибки вида (2) встречаются реже и связаны, как правило, с неправильным прочтением (часто искаженного) номера или неправильным его вводом.
Таким образом, предлагается описывать участника u процесса разметки двумя параметрами: 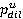 (своего рода «внимательность» или «усердность» – вероятность того, что присутствующий на изображении номер будет найден и включен в аннотацию) и (своего рода «внимательность» или «усердность» – вероятность того, что присутствующий на изображении номер будет найден и включен в аннотацию) и 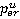 (вероятность того, что номер включен в аннотацию ошибочно). (вероятность того, что номер включен в аннотацию ошибочно).
Унифицированное представление разных видов неопределенности (связанной с действиями человека, осуществляющего разметку изображений, и с положением участников пробега на трассе) с помощью теории вероятности позволяет применить аппарат вероятностного вывода для комплексирования этой информации. Предлагаемую модель комплексирования можно наглядно представить в виде байесовской сети, изображенной на рис. 1.
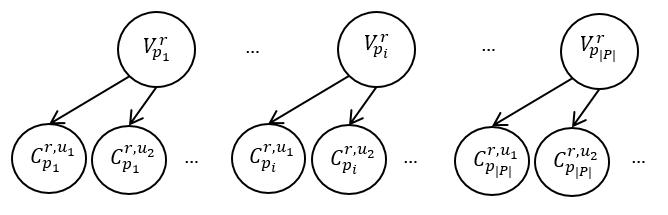
Рисунок 1. Схема байесовской сети для комплексирования информации
Подобная сеть (в данном случае, лес) формируется для поиска изображений каждого участника пробега r. Бинарные переменные 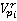 , , 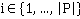 являются ненаблюдаемыми переменными, каждая из которых соответствует факту присутствия участника пробега r на изображении pi. Априорная вероятность являются ненаблюдаемыми переменными, каждая из которых соответствует факту присутствия участника пробега r на изображении pi. Априорная вероятность 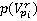 определяется вероятностью присутствия участника в области видимости камеры, вычисляемой по формуле (**). Переменные определяется вероятностью присутствия участника в области видимости камеры, вычисляемой по формуле (**). Переменные 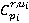 являются наблюдаемыми и соответствуют результатам разметки – по мнению участника разметки u участник пробега c номером r присутствует на изображении pi. Таблица условных распределений для переменных формируется следующим образом. В случае, если r действительно присутствует на снимке, вероятность того, что он будет указан участником разметки u, по определению, равняется . Если же r на изображении нет, но он был указан участником разметки u, значит, при прочтении или вводе одного из номеров u совершил ошибку, заменив правильный номер на r. Вероятность совершения ошибки по определению , вероятность именно такой ошибки: являются наблюдаемыми и соответствуют результатам разметки – по мнению участника разметки u участник пробега c номером r присутствует на изображении pi. Таблица условных распределений для переменных формируется следующим образом. В случае, если r действительно присутствует на снимке, вероятность того, что он будет указан участником разметки u, по определению, равняется . Если же r на изображении нет, но он был указан участником разметки u, значит, при прочтении или вводе одного из номеров u совершил ошибку, заменив правильный номер на r. Вероятность совершения ошибки по определению , вероятность именно такой ошибки: 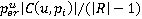 , где , где 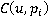 – множество номеров, указанных u для изображения pi, а R – множество допустимых номеров. – множество номеров, указанных u для изображения pi, а R – множество допустимых номеров.
Процесс поиска заключается в нахождении апостериорных вероятностей 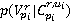 при известных данных разметки, и формировании множества изображений, для которых эта апостериорная вероятность превышает заданное пороговое значение. при известных данных разметки, и формировании множества изображений, для которых эта апостериорная вероятность превышает заданное пороговое значение.
Достоинством применения вероятностных графических моделей для комплексирования данных является модульность схемы комплексирования. Действительно, в будущем предлагаемая схема может быть расширена и дополнена другой моделью ошибок пользователя (скажем, учитывающей то, что некоторые виды ошибок встречаются чаще других).
Экспериментальная оценка
Влияние предлагаемой схемы комплексирования информации на качество поиска изображений было исследовано в ходе серии экспериментов с имитационными моделями. Был сгенерирован набор данных, содержащий траектории передвижения 100 участников пробега по дистанции 10 км. Траектории были построены с учетом того, что типовое время преодоления такой дистанции в ходе любительского легкоатлетического пробега – 30-70 минут, а колебание скорости в ходе движения описывается нормальным законом с среднеквадратичным отклонением около 18% от средней скорости [18]. На основе известного положения участников, был сгенерирован эталонный набор из 1250 фотографий, каждый снимок описывался временем и позицией съемки, а также списком участников «попавших» на снимок. Для определения факта попадания делалась случайная выборка из множества участников, находящихся поблизости от точки съемки.
Оценка качества поиска на основе только априорной вероятности
В первую очередь, было оценено качество поиска на основе только априорной информации (то есть, предлагаемой вероятностной модели перемещения участника по дистанции). Важным параметром здесь является количество точек, в которых известно точное положение участника пробега. В частности, эффективность поиска оценивалась в различных сценариях: когда точное положение участника пробега известно каждые 500 м, 1 км, 5 км и 10 км. Здесь первый вариант приблизительно соответствует поиску по данным GPS-трека, а последний – по данным итогового протокола (в который включается только финишное время).
Для оценки качества использовались традиционные меры, используемые в области информационного поиска: точность (precision), полнота (recall) и сочетающая их F-мера. Данные метрики рассчитывались применительно к двум множествам: множеству пар «участник-снимок», возвращаемому процедурой поиска на основе априорной информацией (пара включалась в множество в том случае, если вероятность нахождения участника в области совершения снимка превышала 30%) и множеству пар «участник-снимок» эталонного набора данных (фактическое присутствие участника на снимке).
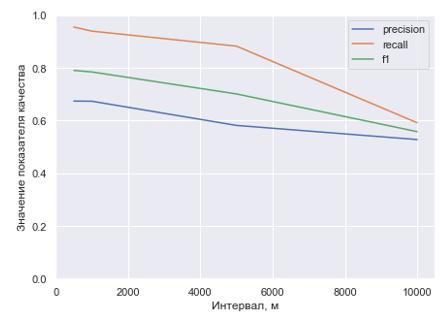
Рисунок 2. Значения показателей качества при поиске на основе априорной вероятности (оценки положения участника)
По приведенному на рис. 2 графику видно, что качество поиска на детализированном треке (500 м) оказывается достаточно хорошим. Объяснимо высокая полнота (0,954) свидетельствует о том, что почти все снимки, на которых участники присутствуют, действительно были включены в результирующую выборку. Низкая (даже при 500 м) точность обусловлена, в первую очередь, тем, что на снимки попадают не все участники, находящиеся поблизости с точкой съемки. При увеличении шага неопределенность, касающаяся местоположения участника, растет соответственно качественные параметры процедуры поиска предсказуемо снижаются.
Оценка качества поиска на основе разметки
Оценка качества поиска на основе данных разметки проводилась с применением двух экземпляров модели участника разметки, соответствующих низкокачественной и высококачественной разметке соответственно. Значения параметров модели 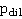 и и 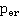 для низкокачественной разметки были приняты 0,7 и 0,1, а для высококачественной – 0,9 и 0,05 соответственно. Данные значения были выбраны на основе анализа истории использования разработанного Сервиса. Информация о снимках была обработана с помощью данных моделей разметки и получено два множества пар «участник-снимок». Результаты оценки качества приведены в табл. 1. Сопоставление данных рис. 2 и табл. 1 позволяет сделать вывод, что поиск на основе только априорной вероятности при детальной информации о перемещении участника пробега позволяет получить результат лучше по обобщенному показателю (F-мера), чем поиск на основе низкокачественной разметки. В остальных случаях поиск по размеченным данным значительно превосходит по F-мере поиск, основанный только на априорной вероятности (и это закономерно, поскольку при разметке проводится анализ самих изображений). для низкокачественной разметки были приняты 0,7 и 0,1, а для высококачественной – 0,9 и 0,05 соответственно. Данные значения были выбраны на основе анализа истории использования разработанного Сервиса. Информация о снимках была обработана с помощью данных моделей разметки и получено два множества пар «участник-снимок». Результаты оценки качества приведены в табл. 1. Сопоставление данных рис. 2 и табл. 1 позволяет сделать вывод, что поиск на основе только априорной вероятности при детальной информации о перемещении участника пробега позволяет получить результат лучше по обобщенному показателю (F-мера), чем поиск на основе низкокачественной разметки. В остальных случаях поиск по размеченным данным значительно превосходит по F-мере поиск, основанный только на априорной вероятности (и это закономерно, поскольку при разметке проводится анализ самих изображений).
Таблица 1 – Типовые показатели качества разметки
|
|
Полнота
|
Точность
|
F-мера
|
|
Низкокачественная
(0,7; 0,1)
|
0,627
|
0,904
|
0,74
|
|
Высококачественная
(0,9; 0,05)
|
0,864
|
0,958
|
0,907
|
Оценка качества поиска на основе предлагаемой модели комплексирования
Исследование качества поиска на основе предлагаемой модели комплексирования также было проведено с разными значениями интервала между известными положениями участника пробега на дистанции и с разным качеством разметки. Графики оцениваемых показателей качества приведены на рис. 3.
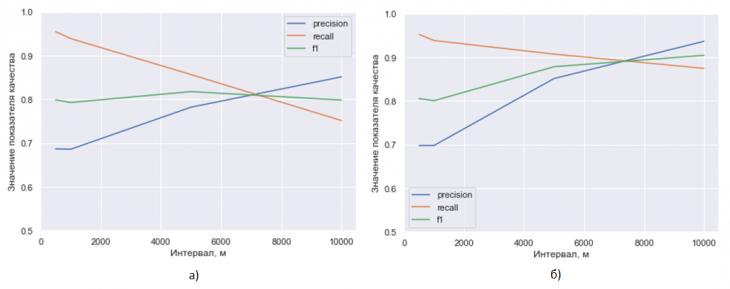
Рисунок 3 – Значения показателей качества поиска при применении комплексирования данных: а) используется ручная разметка низкого качества, б) используется ручная разметка высокого качества
Видно (рис. 3а), что при разных интервалах между известными положениями участника пробега обобщенная мера качества поиска имеет приблизительно одинаковое значение, однако роль разных видов информации плавно меняется. Так, при небольших интервалах (500 м, 1 км) поиск характеризуется высокой полнотой и относительно низкой точностью (значительную роль здесь играет априорная оценка вероятности нахождения участника пробега в заданном интервале). При больших интервалах точность становится выше – характерный признак результатов разметки человеком. В любом случае, за счет схемы комплексирования интегральное качество результатов (F-мера) увеличилось приблизительно на 0,05 по сравнению с ручной разметкой низкого качества, а полнота увеличилась на 0,1.
При комплексировании информации о положении участника с разметкой высокого качества (рис. 3б) подробная информация о местоположении оказывает негативное влияние на значение обобщенной меры качества. Это связано, в первую очередь, с низким значением точности, обусловленным тем, что на снимок попадают не все участники, оказавшиеся поблизости от фотографа в момент съемки (за счет кадрирования и пр.). Однако полнота все равно оказывается существенно выше, чем при ручной разметке.
Заключение
В статье предложен подход к комплексированию данных, получаемых в ходе человеко-машинных вычислений на основе вероятностных графических моделей (байесовских сетей). Предложенный подход применен для повышения качества совместной разметки и поиска изображений в сервисе информационной поддержки проведения любительских легкоатлетических пробегов.
Результаты исследования предложенного подхода с применением имитационного моделирования показали, что особенно эффективным является комплексирование в условиях некачественной разметки. Однако даже в условиях качественной разметки, применение комплексирования позволяет увеличить полноту поисковых результатов при наличии детальной информации о местонахождении.
В целом, можно заключить, что применение комплексирования данных при обработке результатов человеко-машинных вычислений является перспективной техникой, а применение вероятностных графических моделей для комплексирования позволяет плавно увеличивать точность результатов работы системы с увеличением количества доступной информации.
В дальнейшем планируется расширить модель комплексирования за счет применения более детализированных моделей ошибок участника разметки.
Библиография
1. Wechsler D. Crowdsourcing as a method of transdisciplinary research-Tapping the full potential of participants // Futures. Elsevier Ltd, 2014, vol. 60, pp. 14–22.
2. Baev V., Sablok G., Minkov I. Next generation sequencing crowd sourcing at BIOCOMP: What promises it holds for us in future? // Journal of Computational Science. 2014, vol. 5, № 3, pp. 325–326.
3. Fraternali P., Castelletti A., Soncini-Sessa R et al. Putting humans in the loop: Social computing for Water Resources Management // Environmental Modelling and Software. Elsevier Ltd, 2012, vol. 37, pp. 68–77.
4. Nunes A., Galvão T., Cunha J. Urban Public Transport Service Co-creation: Leveraging Passenger’s Knowledge to Enhance Travel Experience // Procedia-Social and Behavioral Sciences. Elsevier B.V., 2014, vol. 111, pp. 577–585.
5. Wu H., Sun H., Fang Y. et al. Combining machine learning and crowdsourcing for better understanding commodity reviews // Proceedings of the 29th AAAI Conference on Artificial Intelligence, 2015, pp. 4220–4221.
6. Chang J., Amershi S., Kamar E. Revolt: Collaborative Crowdsourcing for Labeling Machine Learning Datasets // Proceedings of the Conference on Human Factors in Computing Systems (CHI 2017), pp. 2334–2346.
7. Пономарев А. Методы обеспечения качества в системах крауд-вычислений: аналитический обзор // Труды СПИИРАН, СПб: СПИИРАН. 2017, Том 54, № 5, с. 152–184.
8. Durrant-Whyte H., et al. Multisensor Data Fusion // in Springer Handbook of Robotics (2nd edition), Springer, 2016, pp. 867–896.
9. Castanedo F. A Review of Data Fusion Techniques // The Scientific World Journal, 2013, Article ID 704504
10. Khalegi D. et al. Multisensor Data Fusion: A Review of the State-of-the-Art // Information Fusion, 2013, pp. 28–44
11. Wikipedia Московский марафон. URL: https://ru.wikipedia.org/wiki/Московский_марафон
12. Wikipedia Марафон Белые ночи. URL: https://ru.wikipedia.org/wiki/Белые_ночи_(марафон)
13. RunRepeat.com Marathon Performance Across Nations. URL: http://runrepeat.com/research-marathon-performance-across-nations
14. Scheerder J., Breedveld K. (eds.) Running Across Europe: The Rise and Size of One of the Largest Sport Markets. Palgrave Macmillan, 2015.
15. Roy S. et al. A New Multi-modal Technique for Bib Number/Text Detection in Natural Images // Advances in Multimedia Information Processing – PCM 2015, 2015, LNCS 9314, pp. 483-494.
16. Ben-Ami I., Basha T., Avidan S. Racing Bib Numbers Recognition // British Machine Vision Conference (BMVC), 2012. URL: http://people.csail.mit.edu/talidekel/papers/RBNR.pdf
17. Пономарев А. Разметка изображений массового мероприятия его участниками на основе немонетарного стимулирования // Информационно-управляющие системы, СПб: ГУАП, 2017, № 3. С. 105–114.
18. Haney, Thomas A. Jr. Variability of pacing in marathon distance running. UNLV Theses, Dissertations, Professional Papers, and Capstones. 2010. URL: https://digitalscholarship.unlv.edu/thesesdissertations/779
19. Ponomarev A. Community Photo Tagging: Engagement and Quality Study // Proceedings of the 2017 ACM Web Science Conference (WebSci'17), 2017. pp. 409–410
References
1. Wechsler D. Crowdsourcing as a method of transdisciplinary research-Tapping the full potential of participants // Futures. Elsevier Ltd, 2014, vol. 60, pp. 14–22.
2. Baev V., Sablok G., Minkov I. Next generation sequencing crowd sourcing at BIOCOMP: What promises it holds for us in future? // Journal of Computational Science. 2014, vol. 5, № 3, pp. 325–326.
3. Fraternali P., Castelletti A., Soncini-Sessa R et al. Putting humans in the loop: Social computing for Water Resources Management // Environmental Modelling and Software. Elsevier Ltd, 2012, vol. 37, pp. 68–77.
4. Nunes A., Galvão T., Cunha J. Urban Public Transport Service Co-creation: Leveraging Passenger’s Knowledge to Enhance Travel Experience // Procedia-Social and Behavioral Sciences. Elsevier B.V., 2014, vol. 111, pp. 577–585.
5. Wu H., Sun H., Fang Y. et al. Combining machine learning and crowdsourcing for better understanding commodity reviews // Proceedings of the 29th AAAI Conference on Artificial Intelligence, 2015, pp. 4220–4221.
6. Chang J., Amershi S., Kamar E. Revolt: Collaborative Crowdsourcing for Labeling Machine Learning Datasets // Proceedings of the Conference on Human Factors in Computing Systems (CHI 2017), pp. 2334–2346.
7. Ponomarev A. Metody obespecheniya kachestva v sistemakh kraud-vychislenii: analiticheskii obzor // Trudy SPIIRAN, SPb: SPIIRAN. 2017, Tom 54, № 5, s. 152–184.
8. Durrant-Whyte H., et al. Multisensor Data Fusion // in Springer Handbook of Robotics (2nd edition), Springer, 2016, pp. 867–896.
9. Castanedo F. A Review of Data Fusion Techniques // The Scientific World Journal, 2013, Article ID 704504
10. Khalegi D. et al. Multisensor Data Fusion: A Review of the State-of-the-Art // Information Fusion, 2013, pp. 28–44
11. Wikipedia Moskovskii marafon. URL: https://ru.wikipedia.org/wiki/Moskovskii_marafon
12. Wikipedia Marafon Belye nochi. URL: https://ru.wikipedia.org/wiki/Belye_nochi_(marafon)
13. RunRepeat.com Marathon Performance Across Nations. URL: http://runrepeat.com/research-marathon-performance-across-nations
14. Scheerder J., Breedveld K. (eds.) Running Across Europe: The Rise and Size of One of the Largest Sport Markets. Palgrave Macmillan, 2015.
15. Roy S. et al. A New Multi-modal Technique for Bib Number/Text Detection in Natural Images // Advances in Multimedia Information Processing – PCM 2015, 2015, LNCS 9314, pp. 483-494.
16. Ben-Ami I., Basha T., Avidan S. Racing Bib Numbers Recognition // British Machine Vision Conference (BMVC), 2012. URL: http://people.csail.mit.edu/talidekel/papers/RBNR.pdf
17. Ponomarev A. Razmetka izobrazhenii massovogo meropriyatiya ego uchastnikami na osnove nemonetarnogo stimulirovaniya // Informatsionno-upravlyayushchie sistemy, SPb: GUAP, 2017, № 3. S. 105–114.
18. Haney, Thomas A. Jr. Variability of pacing in marathon distance running. UNLV Theses, Dissertations, Professional Papers, and Capstones. 2010. URL: https://digitalscholarship.unlv.edu/thesesdissertations/779
19. Ponomarev A. Community Photo Tagging: Engagement and Quality Study // Proceedings of the 2017 ACM Web Science Conference (WebSci'17), 2017. pp. 409–410
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования – модель комплексирования данных для повышения качества результатов, получаемых с помощью крауд-вычислений при решении задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов).
Методология исследования основана на сочетании теоретического и модельного подходов с применением методов анализа, алгоритмизации, моделирования, программирования, сравнения, обобщения, синтеза.
Актуальность исследования обусловлена широким применением компьютерных технологий (в том числе крауд-вычислений) в проведении современных исследований и, соответственно, необходимостью изучения и реализации моделей комплексирования данных для повышения качества результатов, получаемых с помощью МЧМВ, включая решение задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов).
Научная новизна связана с обоснованием подхода к комплексированию данных на основе вероятностных графических моделей (байесовских сетей). Показано, что особенно эффективным является комплексирование в условиях некачественной разметки. Однако даже в условиях качественной разметки, применение комплексирования позволяет увеличить полноту поисковых результатов при наличии детальной информации о местонахождении.
Стиль изложения научный. Статья написана русским литературным языком.
Структура рукописи включает следующие разделы: Введение (масштабные человеко-машинные вычисления (МЧВМ, крауд-вычисления), аннотирование изображений, комплексирование данных с использованием вероятностных моделей, обработка показаний датчиков и «выведение» из них истинного состояния наблюдаемого объекта, модель комплексирования данных для повышения качества результатов, получаемых с помощью МЧМВ, решение задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов)), Модель системы разметки изображений (участие в массовых легкоатлетических пробегах, фотографии в открытом доступе, поиск фотографий конкретного участника, технологии компьютерного зрения и OCR, сервис совместной разметки изображений легкоатлетических пробегов, принцип функционирования сервиса), Модель комплексирования данных для системы разметки изображений (местоположение участника пробега в момент фотографирования, GPS-трекер, вероятностная модель, плотность вероятности нахождения участника в области видимости камеры в момент совершения снимка, алгоритм оценки вероятности нахождения участника пробега в точке дистанции в заданный момент времени, склонность к совершению разного рода ошибок, унифицированное представление разных видов неопределённости, схема байесовской сети для комплексирования информации), Экспериментальная оценка (серия экспериментов с имитационными моделями, оценка качества поиска на основе только априорной вероятности, точность (precision), полнота (recall) и сочетающая их F-мера, оценка качества поиска на основе разметки, оценка качества поиска на основе предлагаемой модели комплексирования), Заключение (выводы), Библиография.
Текст включает одну таблицу, три рисунка. Оформление таблицы и рисунков соответствует установленным требованиям.
Содержание в целом соответствует названию. В то же время в формулировке заголовка желательно отразить, что речь идёт о крауд-вычислениях на основе байесовских сетей, а также конкретизировать предмет исследования – решение задачи разметки и поиска изображений, полученных в рамках массовых легкоатлетических мероприятий (пробегов). Следует пояснить порядок определения метрик точности (precision), полноты (recall) и сочетающей их F-меры. Нужно охарактеризовать программные средства, при помощи которых проводились разработка и экспериментальное исследование имитационных моделей.
Библиография включает 19 источников отечественных и зарубежных авторов – научные статьи, материалы научных мероприятий, Интернет-ресурсы. Библиографические описания некоторых источников нуждаются в корректировке в соответствии с ГОСТ и требованиями редакции, например:
1. Wechsler D. Crowdsourcing as a method of transdisciplinary research-Tapping the full potential of participants // Futures. 2014. Vol. 60. P. 14–22.
2. Baev V., Sablok G., Minkov I. Next generation sequencing crowd sourcing at BIOCOMP: What promises it holds for us in future? // Journal of Computational Science. 2014. Vol. 5. № 3. P. 325–326.
5. Combining machine learning and crowdsourcing for better understanding commodity reviews / H. Wu, H. Sun, Y. Fang et al. // Proceedings of the 29th AAAI Conference on Artificial Intelligence. Место издания ??? : Наименование издательства. 2015. P. 4220–4221.
7. Пономарев А. Методы обеспечения качества в системах крауд-вычислений: аналитический обзор // Труды СПИИРАН. 2017. Т. 54. № 5. С. 152–184.
8. Durrant-Whyte H. et al. Multisensor Data Fusion // Springer Handbook of Robotics. Место издания ??? : Springer, 2016. P. 867–896.
11. Московский марафон. URL: https://ru.wikipedia.org/wiki/Московский_марафон.
14. Running Across Europe: The Rise and Size of One of the Largest Sport Markets / eds. J. Scheerder, K. Место издания ??? : Breedveld Palgrave Macmillan, 2015. Р. ???–???.
17. Пономарев А. Разметка изображений массового мероприятия его участниками на основе немонетарного стимулирования // Информационно-управляющие системы. 2017. № 3. С. 105–114.
Библиографические описания завершаются точкой. Интернет-ресурсы Марафон Фото. https://marathon-photo.ru. Russia Running. https://russiarunning.com нужно внести в библиографический список.
Апелляция к оппонентам (Wechsler D., Baev V., Sablok G., Minkov I., Fraternali P., Castelletti A., Soncini-Sessa R., Nunes A., Galvão T., Cunha J., Wu H., Sun H., Fang Y., Chang J., Amershi S., Kamar E., Durrant-Whyte H., Castanedo F., Khalegi D., Roy S., Ben-Ami I., Basha T., Avidan S., Haney T. A. и др.) имеет место.
Замечен ряд опечаток, например: [1,2,3,4] – [1–4]; [8,9,10] – [8–10]; [11,12,13,14] – [11–14]; более 7000 изображений – более 7 тыс. изображений; Так, информация о том, что участник пробега наверняка находился поблизости от точки съемки в момент фотографирования может быть основанием для включения фотографии в поисковую выдачу само по себе – Так, информация о том, что участник пробега наверняка находился поблизости от точки съемки в момент фотографирования, может быть основанием для включения фотографии в поисковую выдачу сама по себе; (см. [17, 19]) – [17, 19].
Английский эквивалент русскоязычных терминов комплексирование данных (data fusion), точность (precision), полнота (recall) представляются излишними. Аббревиатуру и OCR желательно расшифровать.
В целом рукопись соответствует основным требования, предъявляемым к научным статьям. Материал представляет интерес для читательской аудитории и после доработки может быть опубликовании в журнале «Программные системы и вычислительные методы» (рубрики «Компьютерная графика, обработка изображений и распознавание образов», «Математическое моделирование и вычислительный эксперимент»).
|
 Рус
Рус












