|
DOI: 10.7256/2454-0714.2019.1.28768
Дата направления статьи в редакцию:
24-01-2019
Дата публикации:
06-06-2019
Аннотация:
Объектом исследования являются способы хранения мастер-данных в корпоративных информационных системах. Построение систем интеграции разнородных данных является одним из способов решения проблемы управления мастер-данными (Master Data Management). В данной работе рассматривается система хранения структурированных данных в различных базах данных. Такие системы называют гетерогенными системами. Гетерогенные системы обычно возникают в тех случаях, когда узлы, уже эксплуатирующие свои собственные системы с базами данных, со временем интегрируются в распределенную систему. Целью работы является создание системы хранения разнородных данных в базах данных различного типа. Для построения системы используется методология «расходящаяся разработка». Предложен подход к повышению эффективности управления разнородными данными в корпоративных информационных системах, основанный на парадигме программирования «расходящаяся разработка». В рамках данной парадигмы разработан предметно-ориентированный язык запросов к гетерогенной базе данных. Об эффективности созданной системы интегрирования данных можно судить по приведенным в работе результатам тестирования.
Ключевые слова:
базы данных, разнородные данные, NoSQL базы данных, MongoDB, БД ORACLE, MDM, SQL, DSL, синтаксическое дерево, семантическая модель
Abstract: The object of the research is ways to store master data in corporate information systems. Building systems for integrating heterogeneous data is one way to solve the problem of master data management. The paper discusses the storage system for structured data in various databases. Such systems are called heterogeneous systems. Heterogeneous systems usually arise in cases where nodes that already operate their own database systems will eventually integrate into a distributed system. The aim of the work is to create a storage system for heterogeneous data in databases of various types. To build the system, the methodology “divergent development” is used. An approach to improving the efficiency of managing heterogeneous data in corporate information systems based on the “divergent development” programming paradigm is proposed. Within this paradigm, a domain-specific query language for a heterogeneous database has been developed. The effectiveness of the data integration system created can be judged by the test results given in the article.
Keywords: databases, heterogeneous data, NoSQL databases, MongoDB, DB ORACLE, MDM, SQL, DSL, syntax tree, semantic model
Интеграция разнородных данных в корпоративных информационных системах
Единое информационное пространство является ключевым фактором успешности современного бизнеса. Одной из важнейших целей сообщества разработчиков баз данных является переход от управления традиционными БД к задаче управления наборами структурированных, полу структурированных и неструктурированных данных, распределенных по многим репозиториям корпоративных систем. Поэтому возникает задача интеграции гетерогенных данных.
В данной работе рассматривается система хранения структурированных данных в различных базах данных. Такие системы называют гетерогенными системами. Гетерогенные системы обычно возникают в тех случаях, когда узлы, уже эксплуатирующие свои собственные системы с базами данных, со временем интегрируются в распределенную систему.
Задача построения гетерогенных систем возникла из области распространения мастер-данных (distribution of master data) или Master Data Management (MDM) [1]. Все департаменты организации нуждаются в наиболее полной информации, которую необходимо собрать, используя все критичные для бизнеса мастер-данные (клиенты, продукты, поставщики, НСИ и т.д.). Потребителя таких данных интересуют не столько сами данные, сколько их объединения или агрегаты (например, клиента вместе со счетами и инструментами, которыми он торгует).
Данные распространяются согласно трем основным сценариям: выгрузка массива данных по расписанию (bulk load), подписка на обновления (publish-subscribe), поисковые запросы (request-response).
При использовании этих сценариев требования, как по атрибутному набору данных, так и по нефункциональным свойствам (объему и скорости доставки) сильно меняются от потребителя - к потребителю. Поэтому заранее спроектировать реляционную схему, которая справлялась с часто меняющимися структурам данных практически невозможно.
Создание общего для всех пользователей интерфейса, который будет гибким и расширяемым, может решить данную проблему. В качестве такого интерфейса можно рассмотреть язык запросов для сценариев bulk load и request-response. Чтобы обеспечить достаточную скорость выполнения, требуется за этим интерфейсом иметь промежуточный буфер с быстрым доступом и иметь способ маршрутизации запросов к этому буферу. Таким образом, можно достигнуть баланса между переиспользованием ресурсов (если 2 клиента делают одни и те же запросы) и производительностью этих запросов.
Для хранения данных в таких системах можно использовать БД различного типа. Опыт показывает, что Oracle лучше справляется с более непредсказуемыми и сложными запросами [2], а NoSQL база данных - с простыми типовыми запросами.
Рассмотрим далее MongoDB, которая является наиболее распространенной NoSQL БД. Она представляет собой документо-ориентированное нереляционное хранилище данных, использующее для хранения данных формат BSON – расширение формата JSON (JSON – JavaScript Object Notation, BSON – Binary JSON) [3].
NoSQL базы данных обладают достаточно интересными свойствами, которых нет у реляционных баз данных. Однако у NoSQL решений есть существенные недостатки, которые не позволяют полностью отказаться от использования реляционной БД: ненадежность, отсутствие запросов типа join, отсутствие транзакций (кроме Neo4J), у каждой NoSQL БД свой (более узкий, чем у реляционных БД) спектр задач.
Объединение в гетерогенной БД реляционной БД Oracle и базы данных MongoDB обусловлено необходимостью эффективного выполнения запросов поиска данных. Разные модели данных позволяют выполнять один и тот же запрос за разное время на разных серверах, что при оптимальном выборе сервера может дать существенный выигрыш в производительности системы.
Для реализации взаимодействия разных подсистем требуется большие усилия. В данном случае, БД имеют разные модели хранения информации и, соответственно, разный язык запросов. Затраты на реализацию возможностей информационного обмена между подсистемами в этом случае велики и быстро начнут преобладать над затратами по реализации функциональности самих подсистем.
Вопрос интеграции данных достаточно актуален. Компания Oracle создала архитектуру системы интеграции больших данных на основе ETL (ETL (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») [4]. Процесс ETL поддерживают компании Microsoft SQL Server/SSIS, Hadoop/Apache Hive & Spark, IBM Однако, ETL-технологии как правило построены на использовании вспомогательного ПО и предназначенные для реляционных БД. В некоторых случаях проблему можно решить с помощью предметного языка запросов к хранилищу разнородных данных как показано в [5].
В данной работе проблема разнородной структуры запросов к базам данных решалась с помощью расходящейся разработки, опирающейся на предметно-специфичный язык (англ. DSL-Based Development). DSL (domain-specific language) добавляет разработчику еще один уровень абстракции – уровень представления данных[6]. Это увеличивает гибкость создания системы[7].
Созданная гетерогенная система состоит из четырех подсистем (рисунок 1): подсистемы синтаксического анализа и построения семантической модели, подсистемы принятия решений, базы данных и интерфейса пользователя.
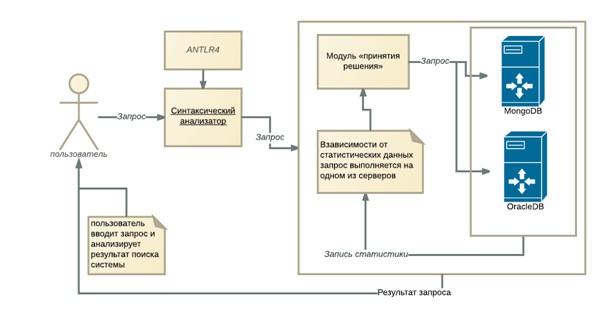
Рисунок 1. Архитектура системы
Синтаксический анализатор обрабатывает информацию, поступающую от пользователя. Подсистема построения семантической модели строит модель и формирует объект-документ MongoDB и запрос на вставку(Insert) для БД ORACLE.
В нашей системе за принятие решения, в какой БД будет выполняться запрос, отвечает модуль «принятия решения». Этот модуль на основании статистики времени выполнения подобных запросов отправляет текущий запрос на соответствующую базу данных. Для поддержания запросов, требующих рассмотрения нескольких документов, скорее всего, будет использоваться SQL база данных, а для запросов требующих рассмотрения одного документа, – MongoDB. Интерфейс пользователя позволяет искать нужную информацию в гетерогенной системе.
Проблема потери данных в разрабатываемой системе не актуальна, т.к. данные часто обновляются, не являются ценными и не являются частными данными пользователя. Синхронизация данных достигается во время обновления. Приоритетным в нашей системе является время выполнения запроса.
Рассмотрим подробнее все модули системы. Для оценки скорости обработки запросов созданной системы гетерогенная база была заполнена информацией о фильмах, хранящихся в online порталах сети Internet.
Подсистема синтаксического анализа и построения семантической модели.
Поисковые запросы пользователя выполняются по схеме, представленной на рисунке 2.
Синтаксический анализатор (парсер) — это программа или часть программы, выполняющая синтаксический анализ. В ходе синтаксического анализа исходный текст преобразуется в дерево разбора (синтаксическое дерево), которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки. Синтаксическое дерево является гораздо более полезным представлением сценария, чем слова, поскольку с ним можно работать различными способами, по-разному обходя дерево. Синтаксическое дерево чаще всего формируется в стеке вызовов и обрабатывается при его обходе [7].
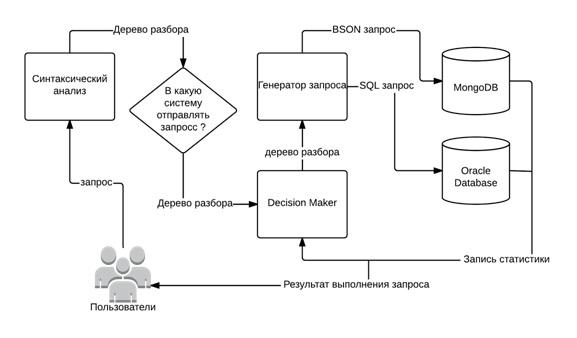
Рисунок 2 Сценарий обработки поисковых запросов
Для создания синтаксических анализаторов использовался генератор парсеров ANTLR[8] (от англ.ANother Tool for Language Recognition — «ещё одно средство распознавания языков»). ANTLR позволяет автоматически генерировать программу‑парсер по LL(*) грамматикам. В системе создан ANTLR скрипт, описывающий грамматику для синтаксического анализатора и интерфейс, служащий для реализаций правил этой грамматики. Запросы к базе формируются с помощью querydsl [9].
На рисунке 3. приведен ANTLR скрипт, описывающий грамматику для синтаксического анализатора.

Рисунок 3. ANTLR скрипт, описывающий грамматику для синтаксического анализатора.
Запросы, созданные на разработанном языке запросов, с помощью генератора запросов преобразуются либо в BSON-запрос к MongoDB либо в SQL запрос. Ниже приведены примеры запросов с использованием созданной грамматики (схема данных БД ORACLE приведена на рисунке 7, иерархия классов MongoDB на рисунке 6).
Пример 1. Найти информацию о фильме по названию
find film name=’name’.
BSON-запрос к MongoDB.
> db.film.find({name : "name"});
SQL запрос.
Select * from FILM_SEACHERS_FILMS
where FILM_NAME = ‘name’
Пример 2. Найти название фильма, в котором роли исполняли Харди и Уильямс.
find film persons(‘role’ is{‘Харди’,’Уильямс’}}
BSON-запрос к MongoDB.
> db.film.find( { {role: ‘role’},persons:[ “Харди”,”Уильямс”]
SQL запрос.
Select f.FILM_NAME
from FILM_SEACHERS_PERSON_TO_FILM ptf
join FILM_SEACHERS_FILMS f on f.ID = ptf.FILM_ID
join FILM_SEACHERS_PERSONS p on p.ID = ptf.PERSON_ID
join FILM_SEACHERS_PROFS pr on pr.ID = ptf.PROF_ID
where p.NAME in (‘Харди’,’Уильямс’)
and pr.PROF_NAME =’role’;
В созданной системе существует два сценария обработки входной информации. Первый сценарий, рассмотренный выше, предназначен для поиска информации в гетерогенной системе. Второй сценарий предназначен для заполнения баз данных по интернет контенту. База была заполнена информацией о фильмах, хранящихся в online порталах сети Internet.
На рисунке 4 приведен ANTLR скрипт для распознавания html страницы сайта Megogo.com. Скрипт предназначен для распознавания персон.

Рисунок 4. ANTLR скрипт для распознавания html страницы сайта Megogo.com.
На вход созданному ANTLR анализатору (парсеру) приходит html страница и этот парсер, согласно написанной грамматике, строит синтаксическое дерево. Пример такого дерева для формирования списка персон, относящихся к фильму, показан на рисунке 5.
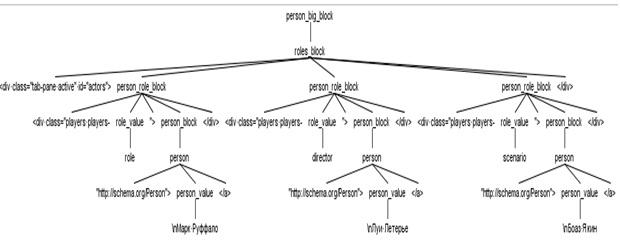
Рисунок 5 . Дерево для формирования списка персон
ANTLR строит так же интерфейс по грамматике для реализации паттерна слушатель. Средствами ANTLR обходится созданное синтаксическое дерево и во время обхода вызывается под каждое правило грамматики соответствующая функция из созданного интерфейса.
В разработанной системе создана реализация такого интерфейса. Она позволяет заполнить семантическую модель во время обхода дерева. Семантическая модель представляет собой иерархию классов, показанную на рисунке 6. Эта иерархия в случае MongoDB совпадает с набором классов, описывающих документы MongoDB.
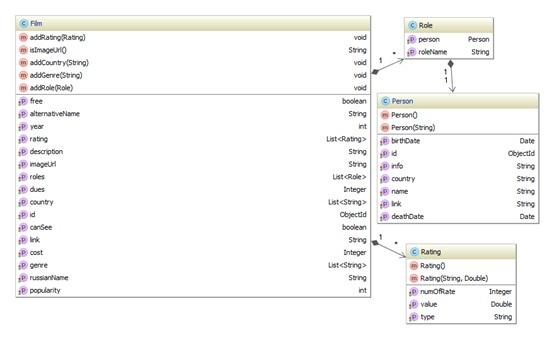
Рисунок 6. Иерархия классов MongoDB
Подсистемы принятия решений.
DecisionMaker - сервис возвращающий базу данных, в которой запрос выполнять выгоднее. В данной работе реализован следующий подход.
Имеется таблица созданная в Oracle Database, в которой записывается время выполнения запроса в каждой БД. В данном случае запрос представляется шаблоном, в котором все конкретные значения полей заменяются на «?». DecisionMaker создает шаблон запроса и ищет этот шаблон в таблице. Из двух БД выбирается та, в которой этот запрос выполняется за наименьшее время.
Перед запуском системы необходимо ее обучить. Т.е. запустить достаточно большое множество запросов и на той, и на другой БД и зафиксировать время выполнения запросов.
Если DecisionMaker не принял никакого решения, то запрос выполняется в обеих БД параллельно. Данные о выполнении этого запроса записываются в таблицу.
Созданная архитектура системы может быть применена для любой предметной области. При реализации системы возникает проблема заполнения информацией баз данных. Данные может вводить пользователь, данные можно брать из сторонних систем. Одним из источников информации являются интернет ресурсы. Для использования такого ресурса необходимо написать собственную грамматику для разбора web страниц.
Базы данных и интерфейс пользователя.
Созданная система реализована для поиска фильмов в online порталах сети Internet.
Схема данных для хранения информации о фильмах и персонах, связанных с киноиндустрией, для ORACLE database показана на рисунке 7.
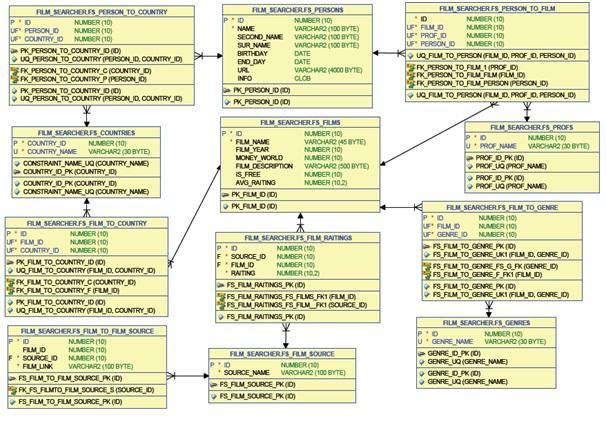
Рисунок 7. Схема базы данных ORACLE
Модель в MongoDB представляет собой набор следующих сущностей, показанных на рис.6. Для работы с MongoDb используется ORM(Object-relational mapping) Google.morphia. ORM - технология программирования, которая связывает базы данных с концепциями объектно-ориентированных языков программирования, создавая «виртуальную объектную базу данных». В случае использование Google.morphia достаточно создать ряд объектов, описав их с помощью соответствующих классов.
Интерфейс системы был создан с помощью следующих технологий:JSP, css, JavaScript, Spring.
Для оценки скорости обработки запросов созданной системы гетерогенная база была заполнена информацией о фильмах, хранящихся в online порталах сети Internet.
Для разработки системы используется язык Java и потребовались следующие библиотеки, средства и базы данных: Spring , Google.morphia , QUERYDSL, MongoDB, ORACLE database.
Все эксперименты проводились на ноутбуке под управлением операционной системы Ubuntu 17.04 (64-bit) с процессором Intel(R) Core(TM) i7-2630QM CPU. Описание тестирования приведено в [10].
Результаты тестирования созданной базы приведены ниже (Таблица1).
Таблица 1. Статистика системы
|
Шаблоны запросов
|
ORACLEDB (мсек)
|
MongoDB(мсек)
|
|
find film
|
205591
|
3102
|
|
findfilmpersons { ?is {?, ?}} genreis?
|
206
|
1010
|
|
findfilmpersons { ?is {?, ?}} countryis?
|
142
|
523
|
|
findfilmpersons { ? is{?, ?}}
|
9
|
481
|
|
find film persons { ? is {?, ?}} genre is ?year>?year<= ?
|
16
|
68
|
|
find film country is ?
|
27460
|
4661
|
|
find film name=?
|
583
|
33
|
|
find film year >?year<?
|
97632
|
7576
|
|
find film year >?
|
52
|
12
|
|
find film year <?
|
136092
|
6016
|
|
find film year <?persons { ? is ?}
|
52
|
69
|
|
findfilmyear<?countryis?
|
26169
|
3054
|
|
find film year < ? country is ? genre is ?
|
5002
|
27
|
|
find film persons { ? is ?}
|
350
|
506
|
|
find film persons { ? is ?} genre is ? year>?
|
350
|
197
|
|
find film persons { ? is ?} genre is ?year>?country is ?
|
69
|
167
|
|
find film persons { ? is ?}
|
297
|
648
|
|
find film genre is ?
|
13446
|
3646
|
Анализ приведенной таблицы показал, что запросы, требующие соединения двух или более документов в MongoDB выполняются в разы медленнее, чем в Oracle Database. Однако, простейшие запросы (по критериям одной сущности, например фильма), в MongoDB выполняются на порядок быстрее. Например, запрос “find film” MongoDB выполняет в 66 раз быстрее, чем Oracle Database.
Заключение
В статье представлен метод интеграции гетерогенных данных, обеспечивающий сокращение времени передачи информации и повышение ее достоверности. Описано несколько языков, для распознавания информации от каждого источника и одна семантическая модель. Представлен также единый способ хранения информации из разных источников. Разработана семантическая модель, позволяющая отражать данные из сети интернет в базы данных. Разработан язык для поиска информации. Создана LL грамматика для анализа web страниц.
Библиография
1. Knut Jürgensen Master Data Management (MDM): Help or Hindrance? [ Electronic resource ] URL: https://www.red-gate.com/simple-talk/sql/database-delivery/master-data-management-mdm-help-or-hindrance/(дата обращения: 23.01.2019).
2. Oracle Database Gateways [Electronic resource] http://www.oracle.com/technetwork/database/gateways/index-100140.html (дата обращения: 23.01.2019).
3. Кристина Чодороу, Майкл Дирольф MongoDB: The Definitive Guide. O’Reilly Media, 2010. 216с.
4. The Five Most Common Big Data Integration Mistakes to Avoid. [Elecronic resource] URL: http://www.oracle.com/us/products/middleware/data-integration/big-data-integration-mistakes-wp-2492054.pdf (дата обращения: 23.01.2019).
5. М. В. Щербаков, Чан Ван Фу, Сай Ван Квонг Грамматика запросов для хранилища разнородных данных в проактивных системах // Программные продукты и системы. 2018. № 4. с. 659-667. DOI:10.15827/0236-235X.124.659-666
6. В. Л. Волушкова Гетерогенные базы данных в корпоративных информационных системах // Информационные технологии в науке, образовании и управлении материалы XLIV международной конференции и XIV международной конференции молодых учёных IT + S&E`16. под редакцией Е.Л. Глориозова. 2016. С. 69-72.
7. Martin Fowler. Domain Specific Languages. Addison-Wesley Professional, 2010. 640с.
8. Terence Parr The Definitive ANTLR 4. Reference. Pragmatic Bookshelf, 2013.326с
9. Querydsl [Electronic resource] URL: http://www.querydsl.com (дата обращения: 23.01.2019).
10. В. Л. Волушкова, А.Ю. Волушкова Поиск структурированной информации в гетерогенных базах данных // Информационные технологии в науке, образовании и управлении под редакцией проф. Е.Л. Глориозова. Москва, 2015. С. 132-136.
References
1. Knut Jürgensen Master Data Management (MDM): Help or Hindrance? [ Electronic resource ] URL: https://www.red-gate.com/simple-talk/sql/database-delivery/master-data-management-mdm-help-or-hindrance/(data obrashcheniya: 23.01.2019).
2. Oracle Database Gateways [Electronic resource] http://www.oracle.com/technetwork/database/gateways/index-100140.html (data obrashcheniya: 23.01.2019).
3. Kristina Chodorou, Maikl Dirol'f MongoDB: The Definitive Guide. O’Reilly Media, 2010. 216s.
4. The Five Most Common Big Data Integration Mistakes to Avoid. [Elecronic resource] URL: http://www.oracle.com/us/products/middleware/data-integration/big-data-integration-mistakes-wp-2492054.pdf (data obrashcheniya: 23.01.2019).
5. M. V. Shcherbakov, Chan Van Fu, Sai Van Kvong Grammatika zaprosov dlya khranilishcha raznorodnykh dannykh v proaktivnykh sistemakh // Programmnye produkty i sistemy. 2018. № 4. s. 659-667. DOI:10.15827/0236-235X.124.659-666
6. V. L. Volushkova Geterogennye bazy dannykh v korporativnykh informatsionnykh sistemakh // Informatsionnye tekhnologii v nauke, obrazovanii i upravlenii materialy XLIV mezhdunarodnoi konferentsii i XIV mezhdunarodnoi konferentsii molodykh uchenykh IT + S&E`16. pod redaktsiei E.L. Gloriozova. 2016. S. 69-72.
7. Martin Fowler. Domain Specific Languages. Addison-Wesley Professional, 2010. 640s.
8. Terence Parr The Definitive ANTLR 4. Reference. Pragmatic Bookshelf, 2013.326s
9. Querydsl [Electronic resource] URL: http://www.querydsl.com (data obrashcheniya: 23.01.2019).
10. V. L. Volushkova, A.Yu. Volushkova Poisk strukturirovannoi informatsii v geterogennykh bazakh dannykh // Informatsionnye tekhnologii v nauke, obrazovanii i upravlenii pod redaktsiei prof. E.L. Gloriozova. Moskva, 2015. S. 132-136.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования – способ интеграции разнородных данных в корпоративных информационных системах (включая подсистему синтаксического анализа и построения семантической модели, подсистему принятия решений, базу данных и интерфейс пользователя).
Методология исследования основана на сочетании теоретического, модельного и эмпирического подходов с применением методов анализа, программирования, тестирования, сравнения, обобщения, синтеза.
Актуальность исследования обусловлена широким применением различных баз данных в корпоративных информационных системах и, соответственно, необходимостью их исследования, проектирования и оптимизации, включая способы интеграции разнородных (структурированных, полуструктурированных, неструктурированных) данных, распределённых по разнообразным репозиториям корпоративных систем.
Научная новизна связана с обоснованием автором способа интеграции гетерогенных данных, обеспечивающего сокращение времени передачи информации и повышение её достоверности. Обоснованы ряд языков для распознавания информации от каждого источника, а также семантическая модель, позволяющая отражать данные из сети Интернет в базах данных.
Стиль изложения научный. Статья написана русским литературным языком.
Структура рукописи включает следующие разделы: Интеграция разнородных данных в корпоративных информационных системах (единое информационное пространство как ключевой фактор успешности современного бизнеса, задача интеграции гетерогенных данных, система хранения структурированных данных в различных базах данных, задача построения гетерогенных систем, мастер-данные, три основных сценария – выгрузка массива данных по расписанию, подписка на обновления, поисковые запросы, создание общего для всех пользователей интерфейса, Oracle, NoSQL, MongoDB, архитектура системы интеграции больших данных на основе ETL (Extract, Transform, Load), предметно-специфичный язык DSL-Based Development, архитектура системы, модули системы), Подсистема синтаксического анализа и построения семантической модели (сценарий обработки поисковых запросов, синтаксический анализатор (парсер), генератор парсеров ANTLR, ANTLR-скрипт, описывающий грамматику для синтаксического анализатора, примеры запросов с использованием созданной грамматики, ANTLR-скрипт для распознавания html-страницы сайта Megogo.com, дерево для формирования списка персон, иерархия классов MongoDB), Подсистемы принятия решений (сервис DecisionMaker), Базы данных и интерфейс пользователя (схема данных для хранения информации о фильмах и персонах, связанных с киноиндустрией, модель в MongoDB, Object-relational mapping Google.morphia, технологии JSP, css, JavaScript, Spring, язык Java, эксперименты под управлением операционной системы Ubuntu 17.04 с процессором Intel(R) Core(TM) i7-2630QM CPU, результаты тестирования созданной базы), Заключение (выводы), Библиография. Точки в названиях разделов не ставятся.
Текст содержит семь рисунков, одну таблицу. Точки в названиях рисунков следует удалить. Оформление скриптов в виде рисунков не представить целесообразным. Название таблицы 1 нужно изменить (например, «Результаты тестирования»), поскольку не ясно, о какой статистике и о какой системе идёт речь. Сокращение для миллисекунды – мс.
Содержание в целом соответствует названию. В то же время, возможно, в формулировке заголовка следует указать, что речь идёт об объединении в гетерогенной базе данных (БД) реляционной БД Oracle и БД MongoDB. Обращает внимание, что название статьи в целом совпадает с названием первого раздела («Интеграция разнородных данных в корпоративных информационных системах»), которое следует изменить (например, «Введение»). Описание процедуры тестирования следует представить более подробно, не ограничиваясь ссылкой на работу [10].
Библиография включает 10 источников отечественных и зарубежных авторов – монографии, научные статьи, материалы научных мероприятий, Интернет-ресурсы. Библиографические описания некоторых источников нуждаются в корректировке в соответствии с ГОСТ и требованиями редакции, например:
1. Jürgensen K. Master Data Management (MDM): Help or Hindrance? – URL: https://www.red-gate.com/simple-talk/sql/database-delivery/master-data-management-mdm-help-or-hindrance (date of access: 23.01.2019).
3. Чодороу К., Дирольф М. MongoDB: The Definitive Guide. Место издания ??? : O’Reilly Media, 2010. 216 р.
5. Щербаков М. В., Чан Ван Фу, Сай Ван Квонг Грамматика запросов для хранилища разнородных данных в проактивных системах // Программные продукты и системы. 2018. № 4. С. 659–667.
6. Волушкова В. Л. Гетерогенные базы данных в корпоративных информационных системах // Информационные технологии в науке, образовании и управлении : материалы XLIV международной конференции и XIV международной конференции молодых учёных IT + S&E`16 / под ред. Е. Л. Глориозова. Место издания ???, 2016. С. 69–72.
10. Волушкова, А.Ю. Волушкова Поиск структурированной информации в гетерогенных базах данных // Информационные технологии в науке, образовании и управлении / под ред. Е. Л. Глориозова. М., 2015. С. 132–136.
Апелляция к оппонентам (Щербаков М. В., Чодороу К., Дирольф М., Чан Ван Фу, Сай Ван Квонг, Jürgensen K., Fowler M., Parr T.) имеет место.
Замечен ряд опечаток: к задаче управления наборами структурированных, полу структурированных и неструктурированных данных – к задаче управления наборами структурированных, полуструктурированных и неструктурированных данных; На рисунке 3. приведен ANTLR скрипт, описывающий грамматику для синтаксического анализатора – На рисунке 3 приведен ANTLR-скрипт, описывающий грамматику для синтаксического анализатора; ANTLR скрипт для распознавания html страницы – ANTLR-скрипт для распознавания html-страницы; Имеется таблица созданная в Oracle Database – Имеется таблица, созданная в Oracle Database; (Таблица1) – (таблица 1); для анализа web страниц – для анализа web-страниц.
Аббревиатуры БД, НСИ нужно привести полностью.
В целом рукопись соответствует основным требования, предъявляемым к научным статьям. Материал представляет интерес для читательской аудитории и после доработки может быть опубликован в журнале «Программные системы и вычислительные методы» (рубрика «Базы данных»).
|
 Рус
Рус


















