|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Лунева Е.Е., Ефремов А.А., Банокин П.И.
Способ идентификации пользователей-экспертов в социальных сетях
// Программные системы и вычислительные методы.
2018. № 4.
С. 86-101.
DOI: 10.7256/2454-0714.2018.4.28301 URL: https://nbpublish.com/library_read_article.php?id=28301
Способ идентификации пользователей-экспертов в социальных сетях
Лунева Елена Евгеньевна
кандидат технических наук
доцент, отделение информационных технологий, федеральное государственное автономное образовательное учреждение высшего образования «Национальный исследовательский Томский политехнический университет»
634050, Россия, г. Томск, ул. Пр. Ленина, 30
Luneva Elena
PhD in Technical Science
Associate Professor, Department of Information Technology, National Research Tomsk Polytechnic University
634050, Russia, g. Tomsk, ul. Pr. Lenina, 30

|
lee@tpu.ru
|
|
 |
Ефремов Александр Александрович
старший преподаватель, отделение автоматизации и робототехники, федеральное государственное автономное образовательное учреждение высшего образования «Национальный исследовательский Томский политехнический университет»
634050, Россия, Томская область, г. Томск, ул. Ленина, 30
Efremov Aleksandr
Senior Lecturer, Department of Automation and Robotics, National Research Tomsk Polytechnic University
634050, Russia, Tomskaya oblast', g. Tomsk, ul. Lenina, 30
|
|
alexyefremov@tpu.ru
|
|
|
|
Банокин Павел Иванович
ассистент, отделение информационных технологий, федеральное государственное автономное образовательное учреждение высшего образования «Национальный исследовательский Томский политехнический университет»
634050, Россия, Томская область, г. Томск, ул. Пр. Ленина, 30
Banokin Pavel
Assistant, Department of Information Technologies, National Research Tomsk Polytechnic University
634050, Russia, Tomskaya oblast', g. Tomsk, ul. Pr. Lenina, 30
|
|
banokin@tpu.ru
|
|
|
|
DOI: 10.7256/2454-0714.2018.4.28301
Дата направления статьи в редакцию:
07-12-2018
Дата публикации:
10-01-2019
Аннотация:
Предметом исследования являются методы и подходы решения класса задач поиска ключевых игроков (key player problem), применимые для идентификации в социальных сетях пользователей-экспертов в определенной предметной области; модель построения социальных графов по данным, выбираемым из социальной сети; методы построения взвешенных ориентированных случайных графов для проведения модельных экспериментов и их сравнительный анализ; методы кластерного анализа результатов ранжирования пользователей социальной сети; сравнительный анализ различных результатов идентификации пользователей-экспертов в заданной предметной области. Методы исследования, применяемые в данной работе, базируются на методах системного анализа, аппарате кластерного анализа, теории графов, а также методах анализа социальных сетей. Для оценки работоспособности предлагаемого способа проводились модельные эксперименты с использованием ЭВМ и эксперименты на реальных данных. В процессе программной реализации сервиса для выполнения экспериментального анализа, а также для демонстрации работоспособности способа использовались методы теории алгоритмов, теории структур данных, объектно-ориентированного программирования. Разработан способ идентификации пользователей-экспертов в социальных сетях в заданной предметной области, учитывающий количественные данные активности этих пользователей. В отличии от существующих способов, пользователи социального графа могут ранжироваться при помощи двух и более эффективных методов, что позволяет использовать преимущества этих методов, а сам способ дает возможность получить дополнительные сведения о пользователях, находящихся под влиянием экспертов-лидеров, а также о потенциальных скрытых лидерах общественного мнения.
Ключевые слова:
социальный граф, ключевые игроки, орграф, кластерный анализ, социальная сеть, лидер общественного мнения, показатель Боргатти, ранжирование Кендалла-Уэя, метод распространения близости, идентификация пользователей
Работа выполнена при финансовой поддержке РФФИ (проект №17-07-00034 А).
Abstract: The subject of the research is methods and approaches for solving a class of key player search tasks (key player problem) applicable for identifying expert users in a certain subject area on social networks; a model for building social graphs from data selected from a social network; methods for constructing weighted oriented random graphs for model experiments and their comparative analysis; methods of cluster analysis of the ranking results of social network users; comparative analysis of various results of the identification of expert users in a given subject area. The research methods used in this work are based on system analysis methods, cluster analysis tools, graph theory, and social network analysis methods. To assess the performance of the proposed method, model experiments were carried out using a computer and experiments on real data. In the process of software implementation of the service, the methods of the theory of algorithms, the theory of data structures, and object-oriented programming were used to demonstrate the operability of the method. A method has been developed for identifying expert users on social networks in a given subject area, taking into account the quantitative data on the activity of these users. Unlike existing methods, users of a social graph can be ranked using two or more effective methods, which allows them to take advantage of these methods, and the method itself provides an opportunity to obtain additional information about users who are influenced by expert leaders, as well as potential hidden leaders public opinion.
Keywords: social graph, key players, directed graph, cluster analysis, social network, opinion leader, Borgatti measure, Kendall-Wei ranking, affinity propagation, user identification
Введение
Социальные сети оказывают значительное влияние на мнение людей, а информация, полученная из них, может быть определяющей при принятии решений как отдельным человеком (например, при покупке товаров или услуг), так и для компаний и организаций. При этом круг задач компаний и организаций может охватывать задачи антитеррористической направленности, политической аналитики, прогнозирования репутационных рисков компании или субъекта, оценки спроса на товар или услугу, а также мониторинга общественного мнения.
Задача поиска влиятельных пользователей социальной сети получила название KPP‑POS (Key Players Problem Positive) [1]. Основным подходом к ее решению считается использование дистанционных методов теории графов, учитывающих длины путей между вершинами социального графа. При этом, среди эффективных методов решения данной задачи можно указать методы, основанные на расчете информационной энтропии и показателе Боргатти [1, 2]. Авторы в работе [3] также предложили использовать для данной задачи процедуру ранжирования Кендалла-Уэя и показали, что данный метод дает результаты, сходные с методом Боргатти.
В настоящее время нельзя определенно назвать единственный лучший метод поиска пользователей-экспертов. Валидация и эффективность способов решения задачи KPP‑POS представлена на подробно описанных в литературе социальных графах, таких как krebs [4] и mexican [5, 6], которые представляют собой невзвешенные и неориентированные графы с заранее известными ключевыми игроками, где большинство известных способов дают сходные, но не идентичные результаты. При этом, для адекватного представления реальной группы пользователей социальных сетей авторы используют ориентированные и взвешенные социальные графы [7]. Проверка эффективности данных способов, применительно к задаче поиска в социальных сетях пользователей-экспертов в заданной предметной области, затруднена отсутствием фактических данных. Такие данные могут быть получены путем трудоемкого процесса проведения многократных социологических опросов в разных предметных областях с последующим сравнением результатов опросов и применяемых способов. Таким образом, в настоящее время нельзя определенно назвать оптимальный метод поиска пользователей-экспертов.
Цель данной работы заключается в разработке способа идентификации пользователей‑экспертов, использующего преимущества наиболее эффективных методов решения данной задачи.
Теоретический анализ
Множество литературных источников посвящено проблеме идентификации значимых узлов в социальных сетях [1, 8, 9]. Для обозначения таких узлов используются разнообразные термины: влиятельный узел, ключевой игрок, критический узел, жизненно важный узел и т.д. [9]. В работе [1] данная проблема была обозначена как проблема поиска ключевых игроков (KPP, Key player problem) и разделена на два класса: Positive (POS) и Negative (NEG). При этом, класс задач KPP‑NEG направлен на поиск такого узла (или группы узлов) социального графа, удаление которого сделает граф максимально фрагментированным. Подходы к решению данной проблемы можно применять для решения задач в области медицины; например, при эпидемиях это задача идентификации группы риска, вакцинация которой максимально сократит распространение заболевания. Также, данные подходы используются для задач антитеррористической направленности, в частности, при выявлении участников, исключение которых из террористической группы максимально разобщит оставшихся членов. Позже данному классу задач был присвоен термин CNP (Critical Node Problem) [8] и дано аналитическое описание.
Второй класс задач KPP‑POS направлен на идентификацию узла (или группы узлов), максимально распространяющего информацию по сети. Решение данной проблемы необходимо, например, для решения задачи внедрения в террористическую сеть информаторов, за счет которых неверная информация максимально быстро распространится по сети [1].
Пользователи социальных сетей, являющиеся экспертами в некоторой предметной области, задают темы для обсуждения, к их мнению прислушиваются другие пользователи. Мнения пользователей-экспертов распространяются по социальной сети за счет различных действий читателей, таких как комментирование, репост, упоминание, «лайк». Задача идентификации пользователей-экспертов в социальных сетях имеет некоторые отличия от задачи CNP и, очевидно, относится к классу задач KPP‑POS.
Анализ литературы [1, 2, 10, 11] позволил выявить следующие способы решения задачи KPP‑POS, считающиеся наиболее эффективными:
- способ, основанный на вычислении показателя Боргатти;
- расчет информационной энтропии вершин графа;
- расчет коммуникационной эффективности.
Разнообразные показатели центральности также могут быть применены для решения этой задачи, однако точность их результатов снижается в случае зашумленных или неполных графов [11].
Однако, применение предложенных способов решения проблемы KPP‑POS к задаче определения пользователей социальных сетей, являющихся лидерами общественного мнения или рассматриваемых в качестве экспертов по заданной тематике, связано со следующими трудностями:
- в литературе решение данной проблемы апробируется на неориентированных и/или невзвешенных графах [1‑3, 7‑11]. Использование таких графов значительно сокращает их способность адекватно представлять реальную группу пользователей социальных сетей, поскольку не позволяет учитывать дополнительную информацию об отношениях между пользователями [3, 7].
- Существует сложность в выборе оптимального способа решения данной задачи, т.к. оценка эффективности решений затруднена отсутствием фактических данных, а также может зависеть от конкретных характеристик анализируемых социальных графов.
Проведенные авторами исследования методов решения задачи идентификации пользователей‑экспертов с учетом описанных выше трудностей позволили сформировать методику построения социального графа, отражающего заинтересованность пользователей социальной сети публикациями пользователей-экспертов, что, в свою очередь, позволило адаптировать и оценить эффективность применения существующих известных способов [3, 7, 12]. Кроме того, результаты исследований позволили подтвердить возможность применения для решения задачи KPP-POS процедуры ранжирования Кендалла-Уэя, несомненным достоинством которой является простота программной реализации алгоритма ранжирования в сравнении с дистанционными алгоритмами [3].
Для повышения достоверности результатов авторы предлагают воспользоваться преимуществами наиболее эффективных методов идентификации влиятельных пользователей и применить их в совокупности, интерпретируя сводные результаты. Для этого предлагается использовать следующий подход при поиске пользователей-экспертов.
1. По выбранным данным из социальной сети строится ориентированный взвешенный социальный граф, ` ` , где `V={v_(i) }` – множество узлов графа `(i=1,2,...N)` , `A={(v_(i), v_(j))} subseteq V^(2)` – множество направленных ребер (дуг), а w – весовая функция, ставящая в соответствие каждой дуге `a_(i j) = (v_(i), v_(j)) in A` некоторое значение `a_{i j} in R` .
При этом узлы графа связаны ребрами по следующему принципу: существует направленное ребро (дуга) `a_{i j}` , связывающее узлы i и j, если j-й пользователь комментировал публикации i-го пользователя, делал их репост или репост с комментарием, упоминал в своих комментариях i-го пользователя. Вес каждого ребра рассматривается как значение функции заинтересованности одного пользователя публикациями другого, т.е. `(a_{i j} ) = f (r_{i j}, c_{i j}, m_{i j}, x_{i j})` , где f - функция заинтересованности; r – количество репостов, с – количество комментариев, m - количество упоминаний пользователя-эксперта, x – репостов с комментариями. Методика построения социального графа и расчета `w(a_{i j})` подробно описана авторами в [7].
2. На основе данных социального графа параллельно выполняется идентификация пользователей-экспертов в соответствии с выбранными способами. Авторы предлагают использовать метод, предложенный Боргатти, и процедуру ранжирования Кендалла-Уэя, как наиболее эффективные [3, 12]. Результат ранжирования указанными способами представляет собой набор из пар чисел `(x_{i}, y_{i}), i= 1...N` , определяющих на координатной плоскости положение точек, соответствующих вершинам `v_{i}` графа. При этом координаты представляют собой значения влиятельности, полученные с помощью процедуры ранжирования Кендалла-Уэя (KW) и метода Боргатти (BG) т.е.:
`forall v_{i} in V, v_{i} rightarrow (x_{i},y_{i}), x_{i}=KW_{i}, y_{i}=BG_{i}`
3. Идентификация группы наиболее влиятельных экспертов проводится с использованием кластеризации полученного массива данных методом распространения близости (AP, affinity propagation) [13].
Следует отметить, что выбранный метод кластерного анализа обладает рядом преимуществ, среди которых можно отметить более низкую ошибку кластеризации по сравнению с другими методами, например, с известным методом кластеризации k‑средних [14]. Также, метод AP самостоятельно определяет количество кластеров и обладает сравнительно низкой вычислительной сложностью при использовании алгоритма, описанного в работе [15] – `O (N^{2}+ MT)` , где N – количество узлов в социальном графе, М – количество ребер графа, Т – число итераций алгоритма.
Результат кластеризации позволяет выделить классы пользователей социальной сети в соответствии с попаданием кластеров в одну из четырех зон на координатной плоскости (рисунок 1):
- зона (A), в которую попадают пользователи, обладающие высокими значениями влиятельности в заданной предметной области в соответствии с каждым из методов;
- зона (B) пользователей, наиболее подверженных влиянию и/или оказывающих минимальное влияние на других участников социальной сети;
- зона (С), в которую попали пользователи, либо являющиеся скрытыми лидерами, либо ошибочно определенные в качестве лидеров одним из методов;
- зона (D), включающая в себя пользователей со средней степенью влиятельности.
Авторы предлагают формировать зоны А, B и С таким образом, чтобы каждая из них представляла собой четверть окружности (рисунок 1). Указанный размер зоны выбран авторами произвольно, исходя из широко распространённого приема работы с квартилями в экспертных методах принятия решений [16]. В зависимости от решаемой задачи, размер зоны может быть скорректирован как в сторону увеличения, так и уменьшения. В частности, предлагается использовать дополнительную зону с увеличенным радиусом, что позволит облегчить визуальный анализ.
Таким образом, кластер, частично или полностью расположенный в зоне А, представляет собой группу пользователей-экспертов.
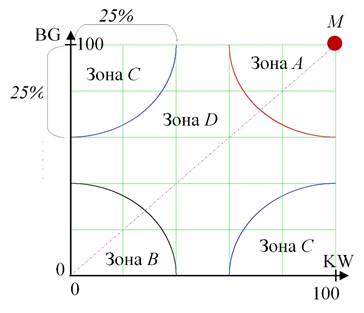
Рисунок 1 – Интерпретация результатов кластерного анализа в предложенном способе
Также, интерес может представлять зона С, в которую попадают группы пользователей, получивших высокую оценку одним из методов и низкую – другим. Более подробный анализ таких групп пользователей требует дополнительных исследований с использованием анализа текстов сообщений.
Постановка эксперимента
Для демонстрации применимости способа авторами предлагается следующая методика проведения экспериментального анализа. На первом этапе оценивается работа способа на смоделированных графах. В ходе выполнения данного этапа будет продемонстрировано, что предлагаемый способ обладает легкостью в интерпретации полученных результатов и обеспечивает идентификацию группы пользователей-экспертов, а также позволяет получить дополнительную информацию для последующего анализа. При этом, для использования модельных графов, наиболее близких к реальным социальным графам, было проведено исследование с оценкой таких параметров как коэффициент кластеризации и средняя длина пути. В качестве социальной сети была выбрана социальная сеть Twitter, что можно объяснить ее популярностью для обсуждения различных тем и событий, а также относительно небольшой длиной сообщений для их последующего анализа в других работах. Для проведения такого исследования авторы получили 50 выборок данных по различным темам.
При выборе тем авторы руководствовались новостными средствами массовой информации, для подбора предметных областей, активность пользователей по которым составляла бы не менее 384 человек. Данный размер выборки объясняется необходимостью получить репрезентативную выборку, которой будет достаточно для оценки мнения российской аудитории данной социальной сети. Согласно данным Левада‑центра в России социальными сетями пользуется только 59% населения старше 18 лет, из которых социальную сеть Twitter использует 7%, т.е. около 4,13 млн. человек [17]. Таким образом, можно говорить о том, что мнения, полученные по крайней мере от 384 человек, представляют репрезентативную выборку с доверительной вероятностью 95% для пользователей данной социальной сети в России.
Для социальных графов, построенных по собранным данным, были определены коэффициент кластеризации и средний кратчайший путь, а также количество сегментов в графе. Можно отметить низкое значение коэффициента кластеризации полученных социальных графов. Так, среднее его значение составило 0,0127, а минимальные и максимальные значения равны 0,01 и 0,2, соответственно. Средний кратчайший путь составляет 1,5. Можно отметить высокую сегментированность используемых для анализа социальных графов: количество сегментов варьируется от 5 до 160. Это объясняется как отсутствием технической возможности сделать полную выборку данных по определенной предметной области, так и возможной особенностью формирования общения пользователей сети, заинтересованных предметной областью. Среди таких пользователей, заинтересованные предметной областью в краткосрочной и долгосрочной перспективе, а также имеющие разную степень заинтересованности. Все это в совокупности может влиять на рассчитанные параметры социальных графов. Кроме этого, можно отметить, что социальные графы проявляют свойство безмасштабных сетей [18]: малое количество узлов обладает высокой степенью связности, тогда как большое количество узлов обладает низкой степенью связности.
На этапе выбора генератора модельных социальных графов для проведения экспериментального анализа был проведен обзор существующих моделей случайных графов, среди которых можно отметить модель Эрдеша-Реньи, позволяющую моделировать сети типа «Мир тесен» [19, 20], и модель Барбаши-Альберта [21]. Также была рассмотрена модель случайного графа с нелинейным правилом предпочтительного связывания, предложенная В.Н. Задорожным [22, 23], позволяющая выращивать случайные графы с использованием механизма предпочтительного связывания.
Модель Задорожного выгодно отличается от других, поскольку позволяет генерировать ориентированные графы [23]. Однако, в рамках настоящего исследования ее использование осложнено отсутствием эталонной модели социального графа.
Таким образом, оценивая характеристики социальных графов, построенных по выборкам из социальной сети, было принято решение использовать модель предпочтительного связывания, с ее адаптацией для взвешенного ориентированного графа, как описано ниже. Случайный ориентированный граф формируется из небольшого графа‑затравки с количеством вершин от 3 до 6. На рисунке 2 представлен пример графа‑затравки.
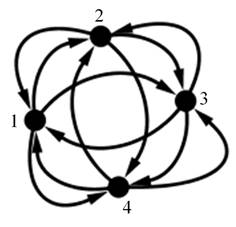
Рисунок 2 – Пример графа-затравки, состоящего из 4 узлов
Далее, к графу добавляется новая вершина, которая связывается направленной входной дугой с другими вершинами в соответствии с моделью Барбаши-Альберта. Таким образом, вероятность связывания новой вершины с существующими определяется по формуле [18]:
`P (k_{i}) = frac{k_{i}}{sum_{j}{:k_{j}:} }` , (1)
где i – вершина, с которой происходит связывание новой вершины, `k_{i}` – полустепень исхода, j=1…N, N – текущее число вершин в графе.
Из формулы (1) видно, что чем больше полустепень исхода вершины, тем выше вероятность её выбора. Такой способ построения исходящих связей имитирует большую значимость тех пользователей, чьи сообщения находят более активный отклик среди читателей в виде репостов, комментариев и т.п.
Входные дуги для новой добавляемой вершиной формируются с постоянной вероятностью независимо для каждого узла в соответствии с моделью Эрдеша-Реньи. Предлагается использовать небольшие значения данной вероятности: 0,09-0,2. Такой способ получения дуг позволяет построить «горизонтальные» связи социального графа, т.е. имитировать заинтересованность любого пользователя сообщениями другого пользователя вне зависимости от его значимости. Далее, дугам построенного ориентированного графа присваивается случайный вес, распределенный в соответствии с бета-распределением [7].
На втором этапе экспериментального анализа работа способа оценивается на реальных данных в областях, в которых либо экспертов можно выявить с использованием внешних данных, либо группа лидеров является официальными источниками распространения информации в заданной предметной области, и по этой причине идентификация лидеров не представляет сложности.
Для проведения экспериментального анализа были выбраны четыре предметных области:
- - Область, связанная с проведением космической миссии BepiColombo по исследованию планеты Меркурий, проходящей в момент подготовки данной работы.
- - Область, связанная с ученым-физиком Стивеном Хокингом; данная область была выбрана в связи с выходом книги данного ученого, что повлияло на объем сообщений в социальной сети.
- - Мнения и отзывы пользователей социальной сети, посвященных годовщине восстания в лагере смерти «Собибор» и выходу одноименного фильма.
- - Мнения и отзывы, посвященные сериалу «Westworld»; данные были собраны в день выхода последней серии второго сезона сериала, что позволило в течение короткого времени получить выборку данных с сообщениями 714 уникальных пользователей.
Экспериментальный анализ
Для проведения экспериментов было разработано специализированное программное обеспечение, позволяющее сгенерировать модельные графы, а также собрать и обработать экспериментальные данные для построения социальных графов. Программный сервис, представляющий собой часть программного комплекса, доступен по адресу http://socgraph.tpu.ru.
Для модельных экспериментов было сгенерировано 50 случайных графов с 400 узлами. Большие размеры случайных графов в модельных экспериментах не использовались с целью экономии вычислительных и временных затрат на их обработку. Диапазоны и средние значения характеристик данных графов приведены в таблице 1.
Таблица 1. Характеристики графов, построенных по данным из социальной сети Twitter
|
Характеристика
|
Количество сегментов
|
Диаметр графа
|
Коэффициент кластеризации графа
|
Средний кратчайший путь
|
|
Значение (диапазон)
|
5-70
|
3-8
|
0,007-0,25
|
1,5-3,47
|
|
Среднее значение
|
34
|
5
|
0,012
|
1,87
|
В соответствии с предлагаемым способом вершины социальных графов были сгруппированы в 3-5 кластеров. На рисунке 3 представлен типовой результат идентификации пользователей-экспертов. В зоне А можно однозначно выделить группу лидеров; в зону B попали пользователи, на которых максимально оказывают влияние другие пользователи.
Для представленного на рисунке 3 примера можно отметить, что оценки одного из способов несколько превышают результаты другого; однако ни один из кластеров не попал в зону С, что не предполагает рассмотрение пользователей из данных групп в качестве скрытых лидеров.
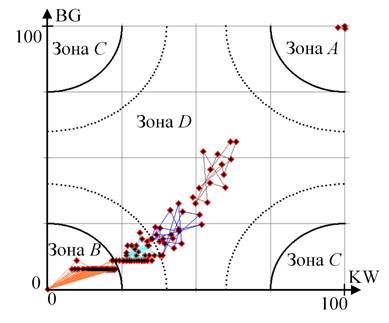
Рисунок 3 – Результаты кластеризации, полученные для случайного графа (N = 400)
В таблице 2 приведены характеристики построенных социальных графов по каждой из четырех анализируемых предметных областей.
Таблица 2. Данные социальных графов для анализируемых предметных областей.
|
Хэштег
|
Количество узлов
|
Количество сегментов
|
Коэффициент кластеризации
|
Средняя длина кратчайшего пути
|
|
#BepiColombo
|
561
|
12
|
0,193
|
1,662
|
|
#StephenHawking
|
899
|
161
|
0,034
|
1,014
|
|
#Собибор
|
357
|
6
|
0,014
|
1,019
|
|
#Westworld
|
714
|
94
|
0,029
|
1,712
|
Для каждого социального графа была выполнена оценка влиятельности пользователей посредством процедуры ранжирования Кендалла-Уэя [24, 25] и методом Боргатти [1]. Таким образом, для каждого узла были получены две числовых характеристики значимости. Для выполнения кластерного анализа полученные результаты были независимо нормированы по каждой характеристике в диапазоне от 0 до 100.
Однако, полученные результаты обладали низким качеством визуализации данных из‑за большого количества точек с близкими значениями числовых характеристик значимости (рисунок 4 а). Поэтому значения числовых характеристик, полученных по результатам процедуры Кендалла-Уэя и метода Боргатти, вначале были прологарифмированы и лишь затем нормированы (рисунок 4 б).
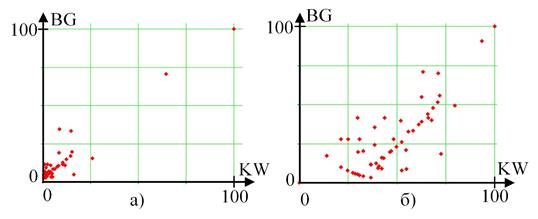
Рисунок 4 – Визуализация результатов идентификации пользователей-экспертов по хэштегу #StephenHawking
а) нормированные данные; б) нормированные прологарифмированные данные
Подготовленные таким образом данные были подвергнуты процедуре кластеризации методом распространения близости [13] с помощью быстрого алгоритма Fast Affinity Propagation (FAP) [15], позволяющего получить тот же результат кластеризации за меньшее число итераций, по сравнению со стандартным алгоритмом [13].
На рисунке 5 представлен результат кластеризации данных, собранных по хэштегу #Bepicolombo, из которого видно, что пользователи разделились на 4 группы. Большинство точек попало в зону B, две группы кластеров расположены в зоне D и не представляют интереса в рамках поставленной задачи. Группа лидеров состоит из 7 пользователей, два из которых попали в зону D. В зависимости от решаемой задачи они могут быть как исключены из группы пользователей-экспертов, так и проанализированы вместе с явными лидерами.
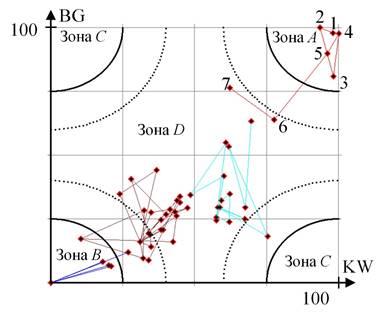
Рисунок 5 – Результат кластеризации вершин социального графа BepiColombo
Завершающим этапом анализа является анализ профилей пользователей, попавших в группу лидеров, с целью исключения возможных случайных результатов. В таблице 3 приведены профили таких пользователей.
Как видно из таблицы 3, пользователи, попавшие в группу лидеров, представляют собой официальные источники распространения информации о миссии BepiColombo, что подтверждает работоспособность предложенного способа. При этом стоит отметить, что два узла, попавшие в группу лидеров, но расположенные в зоне D, также являются официальными источниками. Однако очевидно, что эти источники вызывают меньший интерес пользователей, активных в данной предметной области.
Таблица 3. Профили пользователей-лидеров графа BepiColombo
|
№
|
Имя пользователя
|
Логин пользователя
|
Описание профиля
|
|
1
|
ESA
|
esa
|
Официальный профиль Европейского космического агентства
|
|
2
|
MTM
|
esa_mtm
|
Профиль, посвященный перелетному модулю, созданный ESA (MTM), который перенесет орбитальные устройства к Меркурию
|
|
3
|
ESA Operations
|
esaoperations
|
Профиль Европейского космического агентства, публикующий сведения о миссиях, проходящих в настоящее время.
|
|
4
|
Bepi
|
ESA_Bepi
|
Профиль аппарата, выводимого на орбиту Меркурия
|
|
5
|
BepiColombo
|
BepiColombo
|
Официальный профиль миссии BepiColombo, выполняемой Европейским космическим агентством совместно с Японским космическим агентством.
|
|
6
|
ESA France
|
ESA_fr
|
Профиль Европейского космического агентства на французском языке.
|
|
7
|
JAXA Web
|
JAXA_en
|
Официальный профиль Японского агентства аэрокосмических исследований на английском языке.
|
Аналогично, работоспособность предложенного способа демонстрирует анализ выборки, собранной из социальной сети Twitter по хэштегу #Собибор. На рисунке 6 представлен результат кластеризации данных.
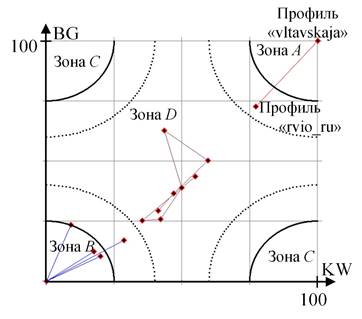
Рисунок 6 –Результат кластеризации вершин социального графа Собибор
Группа лидеров состоит из двух пользователей: профиль Российского военного исторического общества (имя пользователя «rvio_ru»), которое упомянуло о событии в серии твитов, а также профиль пользователя «vltavskaja». Сообщение данного пользователя (доступное по ссылке https://twitter.com/vltavskaja/status/1051373844651565056) вызвало активный отклик среди читателей: 238 ретвитов и 18 комментариев, что и позволило пользователю «vltavskaja» войти в группу лидеров.
Применение предложенного способа к выборке данных, полученной по хэштегу #westworld, дало неожиданные результаты по выявлению лидеров. На рисунке 7 представлен результат кластеризации данных.
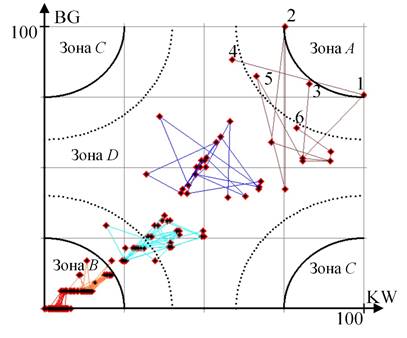
Рисунок 7. Результат кластеризации вершин социального графа Westworld
На границе зоны А можно выделить два узла; при этом используемые способы дали разную оценку этим узлам. Основная группа лидеров расположилась в зоне D, что говорит о том, что группу лидеров составляют пользователи со средней активностью в данной области. Анализ профилей пользователей лидирующей группы продемонстрировал современный тренд распространения информации в социальных сетях посредством мемов [26]. В таблице 4 перечислены ключевые пользователи из группы лидеров и дано описание их профилей.
Таблица 4. Профили пользователей-лидеров графа Westworld
|
№
|
Имя пользователя
|
Логин пользователя
|
Описание профиля
|
|
1
|
HBO Latinoamérica
|
HBOLAT
|
Филиал телевизионного канала HBO для Латинской Америки.
|
|
2
|
9GAG
|
9GAG
|
Профиль одноименного интернет-сайта и социальной сети, основной контент которой составляют интернет-мемы.
|
|
3
|
Selina
|
selinacatherine
|
Профиль пользователя, который поделился твитом во время просмотра заключительной серии, нашедшим большой отклик других пользователей.
|
|
4
|
Peter Farley
|
TheReal_Peeta
|
Пользователь, поделившийся оригинальной шуткой, посвященной сериалу.
|
|
5
|
Westworld
|
WestworldHBO
|
Официальный профиль телевизионного канала HBO, посвященный сериалу «Westworld».
|
|
6
|
Tiffany
|
tiffjaxon
|
Профиль пользователя, который поделился твитом c шутливо высказанном мнением о сериале.
|
Полученные результаты объясняются, в том числе, отсутствием предобработки исходных данных, которая позволила бы исключить профили и твиты юмористической направленности. Кроме этого, на результат повлияло ограничение API Twitter, в результате которого можно выбрать данные публикуемые в момент сбора данных, а также с давностью не более 7 дней. Таким образом, в выборку не попали профили режиссеров и актеров сериала.
Последней эксперимент с помощью предложенного способа был проведен на выборке, полученной по хэштегу #StephenHawking (рисунок 8). В таблице 5 перечислены ключевые пользователи из группы лидеров.
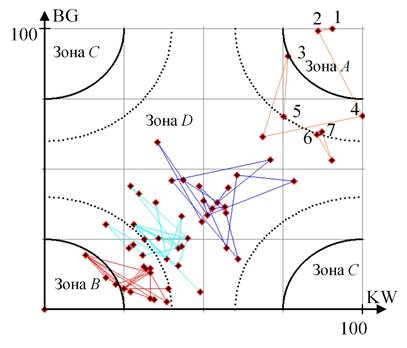
Рисунок 8 – Результат кластеризации вершин социального графа StephenHawking
Таблица 5. Профили пользователей-лидеров графа StephenHawking
|
№
|
Имя пользователя
|
Логин пользователя
|
Описание профиля
|
|
1
|
Lil X Hamster
|
LilXHamster1
|
Пользователь, опубликовавший серию твитов в виде комиксов, посвященных С. Хокингу.
|
|
2
|
Marvel Entertaiment
|
Marvel
|
Профиль крупнейшего издательства комиксов. С. Хокинг появился в качестве персонажа в работах данного издательства.
|
|
3
|
Fabian Schmidt
|
3BodyProblem
|
Взгляд специалиста в области искусственного интеллекта, процитировавшего мнение С. Хокинга о влиянии искусственного интеллекта на будущее человечества.
|
|
4
|
MND Association
|
mndassoc
|
Профиль фонда поддержки исследований в области лечения болезни моторных нейронов.
|
|
5
|
New York Times Books
|
nytimesbooks
|
Профиль издательства, выпустившего книгу С. Хокинга «Краткие ответы на большие вопросы» в октябре 2018 г.
|
|
6
|
Evan Kirstel
|
evankirstel
|
Профиль бизнесмена в области высоких технологий, процитировавшего С. Хокинга в своих публикациях.
|
|
7
|
The Stephen Hawking Foundation
|
HawkingFound
|
Профиль фонда С. Хокинга
|
Полученный результат показывает, что группу лидеров составляют, в том числе, пользователи, которые ищут тренды и используют их для повышения своей популярности внутри социальной сети. Вследствие этого, официальные источники распространения информации, к которым относится фонд С. Хокинга, издательство, опубликовавшее его последнюю книгу, а также фонд исследований, оказались в группе пользователей‑экспертов в зоне D.
Таким образом, проведенный экспериментальный анализ и подробный разбор экспериментов на реальных данных показал, что предлагаемый способ обладает легкостью в интерпретации полученных результатов и обеспечивает идентификацию группы пользователей-экспертов. Развитие данного способа в направлении оценки эмоциональной составляющей в тексте сообщений [27] позволит повысить эффективность идентификации пользователей-экспертов и, при необходимости, исключать пользователей, заинтересованных не столько в предметной области, сколько в своей публичности и узнаваемости.
Заключение
Анализ результатов проведенных модельных экспериментов и экспериментов на реальных данных не вызывает сомнений в возможности применения предложенного способа идентификации пользователей-экспертов, использующего преимущества наиболее эффективных методов решения данной задачи. Дополнительно данный способ позволяет получить сведения о группе пользователей, находящихся под влиянием экспертов-лидеров, задающих общественное мнение, а также о потенциальных скрытых лидерах-экспертах.
В ходе выполнения данной работы был разработан экспериментальный сервис, демонстрирующий работу представленного способа, размещенный по адресу http://socgraph.tpu.ru.
Использование предложенного способа в совокупности с процедурами текстового анализа сообщений позволит повысить эффективность выявления влиятельных пользователей социальных сетей в условиях информационного шума, возможного наличия пользователей, заинтересованных в большей узнаваемости и публичности за счет сознательного использования в своих публикациях социальной неаргументированной провокации.
Работа выполнена при финансовой поддержке РФФИ (проект №17-07-00034 А).
Библиография
1. Borgatti S.P. Identifying sets of key players in a social network // Computational & Mathematical Organization Theory. – 2006. Vol. 12, № 1. – С.21-34
2. Shetty J., Adibi J. Discovering important nodes through graph entropy the case of enron email database // 3rd International Workshop on Link Discovery. – 2015. – С.74-81
3. Ефремов А. А. Использование процедуры ранжирования Кендалла–Уэя для идентификации ключевых игроков социального графа / А. А. Ефремов [и др.] // Доклады ТУСУР. – 2018. – Т. 21, № 1. – С. 80–85. DOI: 10.21293/1818-0442-2018-21-1-80-85
4. Krebs V.E. Uncloaking terrorist networks // Volume. – 2002, Vol. 7, № 4. С. 1-10
5. Batagelj V., Mrvar A.: Pajek datasets. – 2006, URL: http://vlado.fmf.uni-lj.si/pub/networks/data/ (дата обращения: 16.10.2018)
6. UCINET software datasets, webpage, URL: https://sites.google.com/site/ucinetsoftware/datasets/ (дата обращения: 22.11.2018)
7. Сравнение способов идентификации пользователей социальных сетей, являющихся экспертами в заданной предметной области / Е.Е. Лунева, А.А. Ефремов, Е.А. Кочегурова, П.И. Банокин, В.С. Замятина // Системы управления и информационные технологии. – 2017. – №4(70). – С. 63 68
8. Arulselvan A., Commander C., Elefteriadou L., Pardalos P., Detecting critical nodes in sparse graphs // ComputOper Res. – 2009. – №. 36, С. 2193–2200
9. Lalou M., Tahraoui M.A, Kheddouci H. The Critical Node Detection Problem in networks: A survey (Review) // Computer Science Review. – 2018. – №. 28, С. 92–117
10. Ortiz-Arroyo D. Discovering Sets of Key Players in Social Networks // Computational Social Networks Analysis. – 2010. С 27-47
11. Borgatti S.P., Carley K.M., Krackhardt D. On the robustness of centrality measures under conditions of imperfect data // Social Networks. – 2006. Vol. 28, № 2. – С.124-176
12. Luneva E.E., Zamyatina V.S., Banokin P.I., Yefremov A.A. Estimation of social network user's influence in a given area of expertise // Journal of Physics: Conference Series. – 2017. Vol. 803, № 1. – С.1-6
13. Frey B.J., Dueck D. Clustering by passing messages between data points // Science. – 2007. Vol. 315, № 5814. – С. 972-976
14. Jain A.K., Murty M.N., Flynn P.J. Data clustering: A review // ACM Computing Surveys. – 1999. Vol. 31, № 3. – С. 264-323
15. Fujiwara Y., Irie G., Kitahara T. Fast Algorithm for Affinity Propagation // Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence. – 2011. Vol. 3. – С. 2238-2243
16. Орлов А.И. Теория принятия решений. Учебное пособие. – М.: Издательство "Март", 2004. – 656 с.
17. Пользование интернетом. – 2018 URL: https://www.levada.ru/2018/01/18/polzovanie-internetom/ (дата обращения: 16.10.2018).
18. Барабаши А., Бонабо Э. Безмасштабные сети // В мире науки. – 2003. – № 8. – С. 55-63.
19. Erdős P., Rényi A. On random graphs I. // Publ. Math. Debrecen. – 1959. – Vol. 6. – C. 290-297.
20. Райгородский А. М. Модели случайных графов и их применения // Труды МФТИ. – 2010. – Т. 2. № 4. – С. 130–140.
21. Barabási A.-L., Albert R. Emergence of scaling in random networks // Science, 286:509-512, October 15, 1999.
22. Задорожный В.Н. Случайные графы с нелинейным правилом предпочтительного связывания // Проблемы управления. – 2010. – №6. – С. 2-11.
23. Юдин Е.Б. Генерация случайных графов предпочтительного связывания // Омский научный вестник. – 2010. – №2 (90). – С. 7-13.
24. Keener J.P. The Perron–Frobenius Theorem and the Ranking of Football Teams / J.P. Keener // SIAM Review. – 1993. – Vol. 35(1). – C. 80 93.
25. Burk Jr. J.L. Eigenspaces of Tournament Matrices: PhD Thesis / J.L. Burk Jr. – Washington State University, 2012. – 91 с.
26. Polichak J. W. Memes as Pseudoscience // The Skeptic Encyclopedia of Pseudoscience. – 2002. – Vol. 1. – C. 664-667
27. Седова Н.А., Седов В.А. Логико-лингвистическая модель определения уровня квалификации эксперта // Современная наука: актуальные проблемы теории и практики. Серия: естественные и технические науки.-2014. – №7 (8). – С. 3-6.
References
1. Borgatti S.P. Identifying sets of key players in a social network // Computational & Mathematical Organization Theory. – 2006. Vol. 12, № 1. – S.21-34
2. Shetty J., Adibi J. Discovering important nodes through graph entropy the case of enron email database // 3rd International Workshop on Link Discovery. – 2015. – S.74-81
3. Efremov A. A. Ispol'zovanie protsedury ranzhirovaniya Kendalla–Ueya dlya identifikatsii klyuchevykh igrokov sotsial'nogo grafa / A. A. Efremov [i dr.] // Doklady TUSUR. – 2018. – T. 21, № 1. – S. 80–85. DOI: 10.21293/1818-0442-2018-21-1-80-85
4. Krebs V.E. Uncloaking terrorist networks // Volume. – 2002, Vol. 7, № 4. S. 1-10
5. Batagelj V., Mrvar A.: Pajek datasets. – 2006, URL: http://vlado.fmf.uni-lj.si/pub/networks/data/ (data obrashcheniya: 16.10.2018)
6. UCINET software datasets, webpage, URL: https://sites.google.com/site/ucinetsoftware/datasets/ (data obrashcheniya: 22.11.2018)
7. Sravnenie sposobov identifikatsii pol'zovatelei sotsial'nykh setei, yavlyayushchikhsya ekspertami v zadannoi predmetnoi oblasti / E.E. Luneva, A.A. Efremov, E.A. Kochegurova, P.I. Banokin, V.S. Zamyatina // Sistemy upravleniya i informatsionnye tekhnologii. – 2017. – №4(70). – S. 63 68
8. Arulselvan A., Commander C., Elefteriadou L., Pardalos P., Detecting critical nodes in sparse graphs // ComputOper Res. – 2009. – №. 36, S. 2193–2200
9. Lalou M., Tahraoui M.A, Kheddouci H. The Critical Node Detection Problem in networks: A survey (Review) // Computer Science Review. – 2018. – №. 28, S. 92–117
10. Ortiz-Arroyo D. Discovering Sets of Key Players in Social Networks // Computational Social Networks Analysis. – 2010. S 27-47
11. Borgatti S.P., Carley K.M., Krackhardt D. On the robustness of centrality measures under conditions of imperfect data // Social Networks. – 2006. Vol. 28, № 2. – S.124-176
12. Luneva E.E., Zamyatina V.S., Banokin P.I., Yefremov A.A. Estimation of social network user's influence in a given area of expertise // Journal of Physics: Conference Series. – 2017. Vol. 803, № 1. – S.1-6
13. Frey B.J., Dueck D. Clustering by passing messages between data points // Science. – 2007. Vol. 315, № 5814. – S. 972-976
14. Jain A.K., Murty M.N., Flynn P.J. Data clustering: A review // ACM Computing Surveys. – 1999. Vol. 31, № 3. – S. 264-323
15. Fujiwara Y., Irie G., Kitahara T. Fast Algorithm for Affinity Propagation // Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence. – 2011. Vol. 3. – S. 2238-2243
16. Orlov A.I. Teoriya prinyatiya reshenii. Uchebnoe posobie. – M.: Izdatel'stvo "Mart", 2004. – 656 s.
17. Pol'zovanie internetom. – 2018 URL: https://www.levada.ru/2018/01/18/polzovanie-internetom/ (data obrashcheniya: 16.10.2018).
18. Barabashi A., Bonabo E. Bezmasshtabnye seti // V mire nauki. – 2003. – № 8. – S. 55-63.
19. Erdős P., Rényi A. On random graphs I. // Publ. Math. Debrecen. – 1959. – Vol. 6. – C. 290-297.
20. Raigorodskii A. M. Modeli sluchainykh grafov i ikh primeneniya // Trudy MFTI. – 2010. – T. 2. № 4. – S. 130–140.
21. Barabási A.-L., Albert R. Emergence of scaling in random networks // Science, 286:509-512, October 15, 1999.
22. Zadorozhnyi V.N. Sluchainye grafy s nelineinym pravilom predpochtitel'nogo svyazyvaniya // Problemy upravleniya. – 2010. – №6. – S. 2-11.
23. Yudin E.B. Generatsiya sluchainykh grafov predpochtitel'nogo svyazyvaniya // Omskii nauchnyi vestnik. – 2010. – №2 (90). – S. 7-13.
24. Keener J.P. The Perron–Frobenius Theorem and the Ranking of Football Teams / J.P. Keener // SIAM Review. – 1993. – Vol. 35(1). – C. 80 93.
25. Burk Jr. J.L. Eigenspaces of Tournament Matrices: PhD Thesis / J.L. Burk Jr. – Washington State University, 2012. – 91 s.
26. Polichak J. W. Memes as Pseudoscience // The Skeptic Encyclopedia of Pseudoscience. – 2002. – Vol. 1. – C. 664-667
27. Sedova N.A., Sedov V.A. Logiko-lingvisticheskaya model' opredeleniya urovnya kvalifikatsii eksperta // Sovremennaya nauka: aktual'nye problemy teorii i praktiki. Seriya: estestvennye i tekhnicheskie nauki.-2014. – №7 (8). – S. 3-6.
|
 Рус
Рус









