|
Кибернетика и программирование
Правильная ссылка на статью:
Пономарев А.В.
Онтология для описания приложений, использующих элементы крауд-вычислений
// Кибернетика и программирование.
2018. № 3.
С. 25-37.
DOI: 10.25136/2644-5522.2018.3.26556 URL: https://nbpublish.com/library_read_article.php?id=26556
Онтология для описания приложений, использующих элементы крауд-вычислений
Пономарев Андрей Васильевич
кандидат технических наук
старший научный сотрудник, СПИИРАН.
199178, Россия, г. Санкт-Петербург, ул. 14 Линия, 39
Ponomarev Andrei
PhD in Technical Science
Senior Researcher, St. Petersburg Institute of Informatics and Automation of the Russian Academy of Sciences.
199178, Russia, g. Saint Petersburg, ul. 14 Liniya, 39

|
ponomarev@iias.spb.su
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.25136/2644-5522.2018.3.26556
Дата направления статьи в редакцию:
08-06-2018
Дата публикации:
20-06-2018
Аннотация:
Целью работы является разработка машино-читаемого словаря (онтологии) для описания области применения и особенностей реализации программных систем, использующих элементы крауд-вычислений (систем обработки информации, включающих операции, выполняемые людьми, взаимодействие с которыми происходит посредством Интернет). Онтология позволит применять элементы семантического поиска для работы с научно-технической информацией в этой относительно новой, но активно развивающейся области исследований, что, в конечном счете, должно способствовать повышению уровня организации исследований в ней. Построение онтологии производится методом «сверху-вниз» на основе анализа существующих концептуализаций в области человеко-машинных вычислений, описанных в наиболее часто цитируемых обзорных публикациях, проиндексированных в библиографической базе данных Scopus. В результате сформирована онтология CROSS-ODF, позволяющая описать четыре основные характеристики приложений, использующих элементы крауд-вычислений: 1) особенности задачи, для решения которой создано приложение; 2) характеристики заданий, формируемых системой участникам; 3) свойства вклада участников; 4) специфические механизмы по привлечению участников и обработке результатов. Сформированная онтология записана на языке OWL 2 и опубликована в открытом доступе. Разработанная онтология может быть использована в системах поддержки научных исследований для упрощения поиска систем крауд-вычислений, обладающих определенными характеристиками и экспериментальных результатов использования таких систем.
Ключевые слова:
Крауд-вычисления, Краудсорсинг, Онтологии, Семантические технологии, Человеко-машинные системы, Автоматизация исследований, Семантический Веб, OWL, Коллективный интеллект, Семантический поиск
Исследования выполнены при финансовой поддержке РФФИ (проекты 16-37-60107 и 16-07-00466).
Abstract: The purpose of the work is the development of a machine-readable dictionary (ontology) for describing the scope and features of implementing software systems that use elements of crowd computing (information processing systems that include operations performed by people interacting with them via the Internet). Ontology will allow us to apply elements of semantic search to work with scientific and technical information in this relatively new but actively developing field of research, which, ultimately, should help to improve the level of organization of research in it. The ontology is constructed by the "top-down" method on the basis of analysis of the existing conceptualizations in the field of human-machine calculations described in the most frequently cited survey publications indexed in the bibliographic database Scopus. As a result, the ontology CROSS-ODF is formed, which allows describing four main characteristics of applications using the elements of crowd calculations: 1) the features of the problem for which the application was created; 2) the characteristics of the tasks formed by the system to the participants; 3) the contribution properties of the participants; 4) specific mechanisms for attracting participants and processing results. The generated ontology is written in the language OWL 2 and is published in the public domain. The developed ontology can be used in research support systems to simplify the search for crawl computing systems that have certain characteristics and experimental results of using such systems.
Keywords: Crowd computing, Crowdsourcing, Ontologies, Semantic technologies, Human-machine systems, Research automation, Semantic Web, OWL, Collective intelligence, Semantic search
1 Введение
Под крауд-вычислениями (англ. crowd computing) в широком смысле понимается включение операций, выполняемых людьми, в основной процесс функционирования вычислительной системы (или системы обработки информации). Причем, в отличие от традиционных вычислительных систем, взаимодействующих с оператором, при крауд-вычислениях в процесс могут вовлекаться достаточно «случайные» люди, обращение к которым происходит с помощью информационно-телекоммуникационных технологий (как правило, через Интернет).
Основной причиной развития этой технологии является то, что несмотря на современные достижения в области вычислительной техники и теоретической информатики, по-прежнему существуют задачи, которые не могут быть решены исключительно применением программного и аппаратного обеспечения и требуют участия человека. В настоящее время крауд-вычисления находят применение в различных областях человеческой деятельности: в науке (например, [1,2]), в бизнесе (например, [3]), в системах городского и муниципального управления (например, [4,5]).
Таким образом, несмотря на то, что количество практических применений стремительно растет, область достаточно далека от состояния зрелости, потому что общие принципы создания подобных систем еще только находятся в стадии формирования. Несомненно, важную роль в этом формировании играет обобщение опыта применения крауд-вычислений в разных предметных областях, разных задачах, с использованием различных механизмов и способов привлечения (и, возможно, отбора) участников.
Все эти вопросы оказываются в зоне пристального внимания научного сообщества, о чем свидетельствует значительный рост количества публикаций, посвященных различным аспектам создания систем крауд-вычислений и проведению экспериментов с ними. Так, по данным международной библиографической базы данных Scopus (http://scopus.com), включающей материалы более 21 тыс. рецензируемых научно-технических и медицинских изданий, количество ежегодно публикуемых статей, так или иначе связанных с тематикой крауд-вычислений, за последние пять лет удвоилось и в 2017 году составило около 2 тыс. (рис. 1).
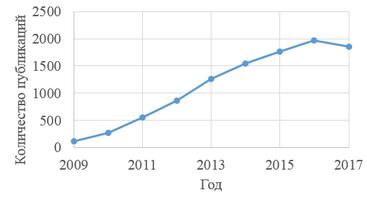
Рисунок 1 – Количество публикаций, имеющих отношение к крауд-вычислениям, в библиографической базе Scopus по годам
Систематизация результатов, представленных в таком количестве публикаций, оказывается непростой задачей, причем ее сложность усугубляется еще и тем, что терминология в данной области исследований окончательно не сложилась, поэтому одни и те же приемы и механизмы могут в разных публикациях называться по-разному.
Разработка методологического и терминологического аппарата новой прикладной области – это сложный многоуровневый процесс. В данной статье предлагается решение одной практической задачи в рамках этого процесса. А именно, использование семантических технологий (в частности, онтологий) для систематизации и облегчения поиска научных публикаций, описывающих устройство приложений, использующих элементы крауд-вычислений, а также опыт их применения. В частности, в статье предлагается OWL 2 онтология CROSS-ODF (CROwd SystemS – Ontological Description Framework), описывающая основные характеристики приложения, включающего элементы крауд-вычислений, и задач, для которых это приложение используется. Предполагается, что классы этой онтологии будут использованы для разметки публикаций, дополняя перечень ключевых слов статьи. Размеченная таким образом коллекция публикаций в значительной мере упростит составление систематизированных обзоров литературы в данной области и поиск существующих систем крауд-вычислений, обладающих заданными характеристиками, что, в конечном счете, будет способствовать повышению уровня организации исследований в данной области.
В статье приводится краткий анализ применения онтологий как при описании систем, использующих крауд-вычисления, так и в целом для систематизации научной информации. Далее описаны методологические основы построения и структура предлагаемой онтологии CROSS-ODF. Приведены примеры использования разработанной онтологии для: а) формального описания классов систем, основанных на использовании крауд-вычислении, и б) описания реальных систем такого рода.
2 Краткий обзор состояния проблемы
2.1 Онтологии краудсорсинга
К настоящему времени было предпринято несколько попыток разработать онтологию краудсорсинга (и крауд-вычислений). Первой работой в этом направлении стала статья L. Hetmank [6], в которой предложена легковесная онтология для корпоративного краудсорсинга (enterprise crowdsourcing). Основным недостатком этой онтологии является ориентация только на одну из форм краудсорсинга – а именно, на биржи микрозаданий (аналогичные Amazon Mechanical Turk или Яндекс.Толока), поэтому использовать ее напрямую для систематизации публикаций по крауд-вычислениям не представляется целесообразным. Вместе с тем, выделенные в данной онтологии концепты (например, «Задание» (Task), «Вклад» (Contribution) и др.), в целом, достаточно хорошо согласуются с терминологией научного дискурса, поэтому разумным представляется, во-первых, использовать эти концепты, во-вторых, по возможности, обеспечить отображение вводимых классов и классов данной онтологии средствами языка OWL 2.
Две другие онтологии – предложенные в статьях [7] и [8] – также обладают специализацией, не вполне совместимой с целями данного проекта. Так, онтология, предлагаемая в работе [7] предназначена, в первую очередь, для описания применения краудсорсинга бизнес-процессов, а онтология, описанная в [8] сфокусирована исключительно на аспектах управления качеством.
Таким образом, онтологий, которые можно было бы напрямую использовать для систематизации публикаций, касающихся опыта применения крауд-вычислений в различных областях, нет. Однако существующие онтологии предлагают набор концептуальных структур, которые могут быть использованы при разработке новой онтологии.
2.2 Онтологии для представления научной информации
В более общей перспективе, формальные возможности онтологий активно применяются для структурирования научной информации. Причем, можно выделить три основных направления применения онтологий:
1) Онтологии используются для семантической разметки научных документов (например, указания того какие именно предложения статьи являются введением, а какие содержат описание научных результатов). Такого рода онтологии не привязаны к конкретной науке или предметной области – их классами являются понятия «Введение», «Научный результат» и пр. Примерами онтологий, относящихся к этому направлению, являются Document ontology [9], ORB [10], Semantic Publishing and Referencing Ontologies [11], DoCO – Document Components Ontology. Подробный обзор подобных онтологий можно найти, например, в [12].
2) Онтологии используются для описания научного дискурса, то есть, с их помощью описываются цели исследований, результаты и аргументы, используемые для их обоснования, наблюдения, структура экспериментов и пр. Примерами таких онтологий являются CISP (Core Information about Scientific Papers) [13], онтология для описания экспериментов EXPO [14], CoreSCs (Core Scientific Concepts) [15].
3) Наконец, онтологии используются для представления самих научных знаний в той или иной дисциплине. В отличие от перечисленных выше онтологий, онтологии, относящиеся к этому направлению, очевидно, обладают предметной направленностью и посредством классов и отношений между ними формально описывают словарь соответствующей дисциплины, отдельной области исследований в рамках дисциплины или даже отдельной проблемы. В частности, активное развитие подобный подход получил в области медицины и биологии; и, в первую очередь, здесь следует отметить библиотеку открытых биомедицинских онтологий OBO, включающую постоянно дополняемые с получением новых научных фактов онтологию генов (Gene Ontology, GO) [16], онтологию протеинов (Protein Ontology, PRO) [17] и др.
Предлагаемую онтологию по целям создания и способам потенциального применения следует отнести к третьему направлению, то есть, она предназначена для описания определенного вида объектов реального мира (систем, использующих крауд-вычисления), затрагивающего устройство этих объектов и особенности их использования. Вместе с тем, поскольку онтологию предполагается использовать для разметки и систематизации научной литературы, возможно включение в нее элементов онтологии второго направления из выделенных выше (или обеспечение совместимости с некоторыми из них).
3 Предлагаемая онтология
3.1 Методология создания онтологии
Итак, целью создания онтологии является определение общего машиночитаемого словаря для описания устройства и назначения приложений, включающих элементы крауд-вычислений, то есть, обращающиеся для выполнения некоторых операций к участникам Интернет-сообщества. Основной целью создания этого словаря является облегчение поиска научных публикаций, описывающих конкретные реализации приложений, использующих крауд-вычисления, и опыт применения подобных систем. Поскольку предполагается, что семантический поиск будет осуществляться на основе разметки документов классами разработанной онтологии вручную (или, во всяком случае, при участии человека), сама онтология должна быть достаточно легковесной. Следует также отметить, что не ставится цель описать детально весь процесс работы приложения – во-первых, это было бы слишком трудоемко, а, во-вторых, онтологии вряд ли оказались бы подходящим инструментом для решения этой задачи.
Для более точной спецификации ожидаемого результата при проектировании онтологий часто приводятся типовые вопросы, на которые онтология должна мочь дать ответ [6,18]. Применительно к разрабатываемой онтологии, такими вопросами являются следующие:
1) В каких научных публикациях описываются системы крауд-вычислений с использованием немонетарного стимулирования?
2) В каких научных публикациях описываются системы крауд-вычислений, участники которых совершают выбор одного из двух вариантов?
3) Какие механизмы обеспечения качества применяются в описанных в литературе системах, основанных на использовании немонетарного стимулирования?
4) Какой механизм привлечения участников, как правило, используется в системах крауд-вычислений, предназначенных для решения задач бизнеса?
При создании онтологии был использован подход «сверху-вниз», то есть выделение классов начиналось с анализа наиболее общих концепций и характеристик систем крауд-вычислений.
Поскольку компьютерная онтология, несмотря на машиночитаемость и связанные с ней возможности автоматического вывода, в первую очередь, предназначена для использования людьми, набор классов онтологии и взаимосвязей между этими классами должен быть максимально близок к используемой в соответствующей предметной области терминологии [18]. Для выполнения этого требования в основу онтологии положены термины и взаимосвязи, найденные в обзорных публикациях по вопросам человеко-машинных вычислений (в том числе, крауд-вычислений, краудсорсинга и еще ряда схожих понятий), проиндексированных в Scopus. В частности, было выделено три группы источников:
1) 5 наиболее цитируемых обзорных публикаций по человеко-машинным системам, не ориентированных на определенный вид приложений. В эту группу попали следующие публикации: [19–23].
2) 5 наиболее цитируемых обзорных публикаций по человеко-машинным системам за последние 5 лет, не ориентированных на определенный вид приложений. В эту группу попали следующие публикации: [24–28]
3) Публикации за 2018 и 2017 годы, посвященные различным разновидностям человеко-машинных вычислений и различным аспектам реализации этих вычислений, исключая, однако, обзорные публикации, посвященные исключительно определенным прикладным областям (медицина и пр.). В эту группу вошли следующие публикации: [29–40].
Кроме того, при составлении онтологии автор опирался на предыдущую работу в данной области [41,42], в том числе, на проведенный ранее обзор методов обеспечения качества результатов крауд-вычислений [43].
Естественно также, что онтология, отображающая какую-либо область знаний, как правило, не является законченной. Причин для этого, как минимум, две. Во-первых, в ходе развития области знаний появляются новые понятия, которые должны быть в эту онтологию добавлены, во-вторых, по мере расширения множества пользователей онтологии некоторые определения могут уточняться для учета позиций различных категорий пользователей. Прагматическим следствием этого является встраивание в онтологию механизма версионности, а также организация публичного репозитария, в котором хранится определение онтологии, дополненного системой отслеживания ошибок.
3.2 Устройство онтологии и ее основные классы
В основу онтологии положен поток работ, присущий большинству систем крауд-вычислений. Система формирует задания (Task), которые выполняются участниками системы (Worker). Результаты выполнения заданий (вклад, Contribution) собираются и обрабатываются системой. Причем формирование заданий является необязательным, поскольку некоторые системы (например, Wikipedia) основываются на свободном выборе участником объекта для приложения своих усилий. Вид и форма представления заданий, формат вклада, а также механизмы его обработки являются важными параметрами структуризации возможных приложений крауд-вычислений. Именно они стали наиболее общими классами предлагаемой онтологий. Помимо этих классов, отражающих наиболее важные аспекты устройства приложения, в онтологию включены также классы, позволяющие охарактеризовать особенности задачи, решаемой с помощью приложения.
Таким образом, все описание приложения, основанного на крауд-вычислениях, разбивается на 4 сферы (рис. 2): 1) задача, для решения которой создано приложение; 2) задания, формируемые системой участникам; 3) особенности вклада участников; 4) специфические механизмы по привлечению участников и обработке результатов.
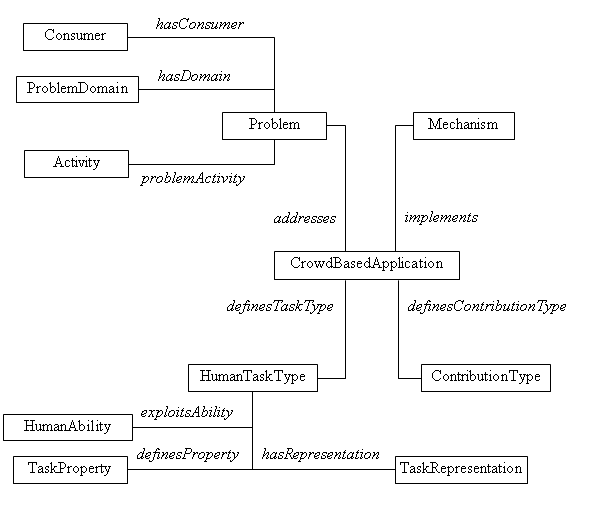
Рисунок 2 – Схема основных классов и отношений онтологии
Описание задачи (класс Problem) призвано раскрыть назначение приложения, основанного на крауд-вычислениях. В частности, задача описывается посредством потребителя результатов задачи (Consumer), предметной области (Domain) и высокоуровневого описания процесса обработки информации, реализуемого данным приложением (Activity). Подклассы класса Activity сформированы на основе классификации задач из [27]. Ими являются, например, сбор данных (класс Collect), выбор данных (класс Filter), поиск (класс Search) и другие.
Важной характеристикой для приложений, основанных на крауд-вычислениях, является тип заданий, передаваемых для выполнения участникам (класс HumanTaskType). Следует отметить, что онтология предназначена не для представления отдельных заданий, то есть, экземпляром здесь является не одно задание, представляемое участнику, а тип заданий, определяемых приложением. На основе анализа существующих классификаций такого рода приложений выявлены три наиболее информативные свойства заданий: специфическая способность человека, критичная для выполнения заданий такого типа, форма представления задания и набор дополнительных признаков, связанных с заданием. В предлагаемой онтологии эти признаки отображены в три класса: HumanAbility, TaskRepresentation и TaskProperty соответственно.
Предполагаемый тип вклада (класс ContributionType), обрабатываемый приложением, классифицируется по двум критериям (не показано на рисунке): причиной вклада (он может быть обусловлен выполнением задания или собственной инициативой участника) и формой вклада (информационный, физический и пр.).
Класс Mechanism представляет собой вычислительную процедуру, которая может быть реализована приложением. Наиболее важными видами механизмов, описанными в предлагаемой онтологии, являются механизм допуска участника к выполнению заданий (класс AdmissionMechanism), механизм распределения заданий (класс TaskDistributionMechanism), механизм мотивации и стимулирования (класс MotivationMechanism) и механизм обработки данных, получаемых от участников (класс ContributionProcessingMechanism).
3.3 Практическая реализация
Предлагаемая онтология записана на языке The Web Ontology Language 2 (OWL 2). Выбор именно этого языка обусловлен тем, что OWL 2 является широко распространенным языком онтологического моделирования, разработанным и развиваемым под эгидой консорциума W3C. Это обеспечивает, во-первых, совместимость с другими онтологиями, созданными с использованием этого языка (что может оказаться полезным, например, при дальнейшей, более детальной спецификации задачи, решению которой посвящено приложение), во-вторых, совместимость с многочисленными программными инструментами, предназначенными для обработки OWL 2 онтологий. В частности, для записи онтологии использован редактор онтологий Protégé.
Для разработанной онтологии был зарегистрирован постоянный локатор ресурса (PURL), обеспечивающий постоянство URI классов онтологии, независимо от фактического размещения документа с их определением.
Сама онтология размещена на веб-сервисе для хостинга и совместной разработки IT-проектов GitHub (https://github.com/m-hatter/cross-odf). Это позволяет не только создать единый информационный ресурс, посвященный использованию данной онтологии, но и упорядочить процесс ее развития с участием сообщества (например, за счет использования компонента отслеживания ошибок, предлагаемого этой платформой).
4 Примеры применения разработанной онтологии
Описывая в машино-читаемой форме концепции и свойства, важные с точки зрения классификации приложений, основанных на применении крауд-вычислений, онтология позволяет формально определять термины в этой области, обеспечивая возможность интеллектуального поиска. Рассмотрим несколько примеров.
Под «краудфандингом» обычно понимается материальная поддержка тех или иных инициатив большой группой людей, взаимодействующих посредством информационно-коммуникационных технологий (то есть, краудом). В этом смысле краудфандинг вполне соответствует введенному в онтологии классу CrowdBasedApplication. Специфика краудфандинга связана с видом вклада, даваемого участниками. Это позволяет определить его следующим образом:
Class: crossodf:CrowdfundingApplication
EquivalentTo:
crossodf:CrowdBasedApplication
and (crossodf:definesContributionType some
crossodf:MonetaryContribution)
Данное определение записано с использованием т.н. манчестерского синтаксиса OWL и означает, что объект принадлежит классу CrowdfundingApplication тогда и только тогда, когда он принадлежит классу CrowdBasedApplication и хотя бы некоторые из типов вклада, определяемых этим приложением, относятся к монетарным.
Другой разновидностью приложений, основанных на крауд-вычислениях, являются так называемые приложения пространственного краудсорсинга. В таких приложениях задания, предлагаемые участникам, связаны с определенной точкой в пространстве. В соответствии с разработанной онтологией его можно определить следующим образом:
Class: crossodf:CrowdsensingApplication
EquivalentTo:
crossodf:CrowdBasedApplication
and (crossodf:definesTaskType some
(crossodf:definesProperty some crossodf:SpatialProperty))
То есть, объект принадлежит классу CrowdsensingApplication тогда и только тогда, когда он принадлежит классу CrowdBasedApplication и определяет тип задач, описываемый пространственным свойством (SpatialProperty). Префикс crossodf здесь соотствует классам, определенным в онтологии CROSS-ODF.
Однако основным назначением онтологии является описание особенностей конкретных приложений. Для описания приложения необходимо выбрать классы онтологии, специфицирующие каждую из 4-х сфер, лежащих в основе онтологии: задача, вид задания, вид вклада, набор механизмов. Приведем в качестве примера описание приложения Bibtaggers для совместной разметки фотографий, предложенного в статье [44].
Приложение предназначено для сбора меток (номеров), видимых на фотографиях. Таким образом, описание задачи с помощью онтологии задается следующим образом:
crossodf:TaggingBibNumbers rdf:type crossodf:Problem ;
crossodf:hasConsumer
[rdf:type crossodf:Society ];
crossodf:problemActivity
[rdf:type crossodf:Collect ] .
При этом потребитель результатов работы приложения и характер обработки данных заданы с помощью анонимных объектов, относящихся к соответствующим классам – Society и Collect.
Тип задания, вводимый приложением, описывается следующим образом:
crossodf:BibtaggersTaskType
rdf:type crossodf:HumanTaskType ;
crossodf:exploitsAbility crossodf:VisualNumberRecognition ;
crossodf:hasRepresentation
[rdf:type crossodf:Image ];
crossodf:requiresAction
[rdf:type crossodf:Describe ] .
Описание типа вклада задается следующим образом:
crossodf:BibtaggersContributionType
rdf:type crossodf:LimitedVocabularyContribution ,
crossodf:TaskResultContribution ;
crossodf:causedByTaskType crossodf:BibtaggersTaskType .
Все приведенные выше описания и перечень механизмов, реализуемых приложением Bibtaggers, объединяются в следующем определении:
crossodf:Bibtaggers rdf:type crossodf:CrowdBasedApplication ;
crossodf:addresses crossodf:TaggingBibNumbers ;
crossodf:definesTaskType crossodf:BibtaggersTaskType ;
crossodf:definesContributionType crossodf:BibtaggersContributionType;
crossodf:implements crossodf:GenericGoldQuestionsQualityThreshold ,
crossodf:GenericIntegrative ,
crossodf:GenericNonmonetary ,
crossodf:GenericPush .
5 Заключение
В статье предложена легковесная онтология CROSS-ODF для машиночитаемого описания назначения и особенностей устройства систем, включающих элементы крауд-вычислений. Использование данной онтологии для семантической разметки публикаций, посвященных крауд-вычислениям, позволит облегчить работу с литературой, а в дальнейшей перспективе и повысить «связность» исследований в данной области.
Развитие работы предполагается в рамках следующих направлений:
1) Разработка (или адаптация одной из существующих – например, Semantic MediaWiki) платформ семантической разметки для программной поддержки семантической разметки публикаций с использованием разработанной онтологии.
2) Расширение онтологии для обеспечения возможности описания и других видов научных результатов, касающихся исследования крауд-вычислений (практических и модельных экспериментов и устанавливаемых в ходе этих экспериментов закономерностей).
3) Использование этой онтологии (или ее расширенного варианта) для построения системы поддержки принятия решений при проектировании приложений, использующих крауд-вычисления. Для этого, в частности, планируется дополнить онтологию конструкциями для описания фактического результата, полученного в статье, чтобы он мог использоваться для быстрой оценки тех или иных решений.
В значительной мере дальнейшие исследования оказываются близки к научной школе Ю.А. Загорулько, последовательно развивающему методологические и инструментальные средства для построения порталов научных знаний на базе онтологий (например, [45,46]). Использование разработанной онтологии в подобном портале способно значительно повысить эффективность работы исследователя в области построения человеко-машинных систем или инженера, разрабатывающего систему с элементами крауд-вычислений.
Библиография
1. Wechsler D. Crowdsourcing as a method of transdisciplinary research-Tapping the full potential of participants // Futures. Elsevier Ltd, 2014. Vol. 60. P. 14–22.
2. Baev V., Sablok G., Minkov I. Next generation sequencing crowd sourcing at BIOCOMP: What promises it holds for us in future? // J. Comput. Sci. Elsevier B.V., 2014. Vol. 5, №
3. P. 325–326. 3.Ye H. (Jonathan), Kankanhalli A. Investigating the antecedents of organizational task crowdsourcing // Inf. Manag. Elsevier B.V., 2015. Vol. 52, № 1. P. 98–110.
4. Fraternali P. et al. Putting humans in the loop: Social computing for Water Resources Management // Environ. Model. Softw. Elsevier Ltd, 2012. Vol. 37. P. 68–77.
5. Nunes A. a., Galvão T., Cunha J.F.E. Urban Public Transport Service Co-creation: Leveraging Passenger’s Knowledge to Enhance Travel Experience // Procedia-Soc. Behav. Sci. Elsevier B.V., 2014. Vol. 111. P. 577–585.
6. Hetmank L. A Lightweight Ontology for Enterprise Crowdsourcing // Ecis. 2014. № section 4. P. Paper 886.
7. Thuan N.H. et al. Building an Enterprise Ontology of Business Process Crowdsourcing: a Design Science Approach // Proceedings of PACIS. 2015. № August.
8. Alabduljabbar R., Al-Dossari H. Ontology for Task and Quality Management in Crowdsourcing // Int. J. Comput. 2016. Vol. 22, № 1. P. 90–102.
9. Document Ontology [Electronic resource]. URL: http://www.cs.umd.edu/projects/plus/SHOE/onts/docmnt1.0.html (accessed: 08.06.2018).
10. Ontology of Rhetorical Blocks [Electronic resource]. URL: http://www.w3.org/2001/sw/hcls/notes/orb/#ontology (accessed: 08.06.2018).
11. SPAR [Electronic resource]. URL: http://purl.org/spar.
12. Ruiz-Iniesta A., Corcho O. A review of ontologies for describing scholarly and scientific documents // CEUR Workshop Proc. 2014. Vol. 1155.
13. Soldatova L., Liakata M. An ontology methodology and CISP-the proposed Core Information about Scientific Papers. 2007. № December.
14. Soldatova L.N., King R.D. An ontology of scientific experiments // J. R. Soc. Interface. 2006. Vol. 3, № 11. P. 795–803.
15. Liakata M. et al. Corpora for the conceptualisation and zoning of scientific papers // Proc. Lr. 2010. P. 2054–2061.
16. Ashburner M. et al. Gene Ontology: tool for the unification of biology // Nat. Genet. 2000. Vol. 25, № 1. P. 25–29.
17. Natale D.A. et al. The Protein Ontology: a structured representation of protein forms and complexes // Nucleic Acids Res. 2011. Vol. 39, № Database. P. D539–D545.
18. Arp R., Smith B., Spear A.D. Building Ontologies with Basic Formal Ontology. 2015. 248 p.
19. Yuen M.C., King I., Leung K.S. A survey of crowdsourcing systems // Proceedings-2011 IEEE International Conference on Privacy, Security, Risk and Trust and IEEE International Conference on Social Computing, PASSAT/SocialCom 2011. 2011. P. 766–773.
20. Yuen M.-C., Chen L.-J., King I. A Survey of Human Computation Systems // 2009 International Conference on Computational Science and Engineering. 2009. № July 2014. P. 723–728.
21. King I., Li J., Chan K.T. A brief survey of computational approaches in Social Computing // 2009 International Joint Conference on Neural Networks. 2009. P. 1625–1632.
22. Pedersen J. et al. Conceptual foundations of crowdsourcing: A review of IS research // Proc. Annu. Hawaii Int. Conf. Syst. Sci. 2013. P. 579–588.
23. Quinn A.J., Bederson B.B. Human Computation: A Survey and Taxonomy of a Growing Field // Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’11). 2011. P. 1403–1412.
24. Morschheuser B., Hamari J., Koivisto J. Gamification in crowdsourcing: A review // Proceedings of the Annual Hawaii International Conference on System Sciences. 2016. Vol. 2016–March. P. 4375–4384.
25. Hossain M., Kauranen I. Crowdsourcing: a comprehensive literature review // Strateg. Outsourcing An Int. J. 2015. Vol. 8, № 1. P. 2–22.
26. Senaratne H. et al. A review of volunteered geographic information quality assessment methods // Int. J. Geogr. Inf. Sci. 2016. Vol. 8816, № May. P. 1–29.
27. Li G. et al. Crowdsourced Data Management: A Survey // IEEE Trans. Knowl. Data Eng. 2016. Vol. 28, № 9. P. 2296–2319.
28. Buettner R. A Systematic Literature Review of Crowdsourcing Research from a Human Resource Management Perspective // 48th Hawaii International Conference on System Sciences (HICSS). 2015. P. 4609–4618.
29. Restuccia F. et al. Quality of Information in Mobile Crowdsensing: Survey and Research Challenges. 2017. Vol. 13, № 4.
30. Feng W. et al. A Survey on Security, Privacy and Trust in Mobile Crowdsourcing // IEEE Internet Things J. 2017. Vol. 4662, № c. P. 1–24.
31. Vergara-Laurens I.J., Jaimes L.G., Labrador M.A. Privacy-Preserving Mechanisms for Crowdsensing: Survey and Research Challenges // IEEE Internet Things J. 2017. Vol. 4, № 4. P. 855–869.
32. Tsvetkova M. et al. Understanding Human-Machine Networks: A Cross-Disciplinary Survey // ACM Comput. Surv. 2015. Vol. 50, № 1. P. Article 12.
33. Durward D., Blohm I., Leimeister J.M. Is There PAPA in Crowd Work? A Literature Review on Ethical Dimensions in Crowdsourcing // The IEEE International Conference on Internet of People,. 2016.
34. Ghezzi A. et al. Crowdsourcing: A Review and Suggestions for Future Research // Int. J. Manag. Rev. 2017. Vol. 0. P. 1–21.
35. Assis Neto F.R., Santos C.A.S. Understanding crowdsourcing projects: A systematic review of tendencies, workflow, and quality management // Inf. Process. Manag. 2018. Vol. 54, № 4. P. 490–506.
36. Daniel F. et al. Quality Control in Crowdsourcing: A Survey of Quality Attributes, Assessment Techniques and Assurance Actions. 2018. Vol. 0, № 0.
37. Ramírez-Montoya M.S., García-Peñalvo F.-J. Co-creation and open innovation: Systematic literature review // Comunicar. 2018. Vol. 26, № 54. P. 9–18.
38. Wazny K. Crowdsourcing’s ten years in: A review // J. Glob. Health. 2017. Vol. 7, № 2. P. 1–13.
39. Morschheuser B. et al. Gamified crowdsourcing: Conceptualization, literature review, and future agenda // Int. J. Hum. Comput. Stud. Elsevier Ltd, 2017. Vol. 106, № March 2016. P. 26–43.
40. Liang X., Yan Z. A survey on game theoretical methods in Human-Machine Networks // Futur. Gener. Comput. Syst. Elsevier B.V., 2017.
41. Sandkuhl K., Smirnov A., Ponomarev A. Crowdsourcing in business process outsourcing: An exploratory study on factors influencing decision making // Lecture Notes in Business Information Processing. 2016. Vol. 261.
42. Smirnov A., Ponomarev A. Exploring Requirements for Multipurpose Crowd Computing Framework // ESOCC 2015: Advances in Service-Oriented and Cloud Computing. Springer, 2016. P. 299–307.
43. Пономарев А.В. Методы обеспечения качества в системах крауд-вычислений: аналитический обзор // Труды СПИИРАН. 2017. Vol. 54, № 5. P. 152–184.
44. Пономарев А.В. Разметка изображений массового мероприятия его участниками на основе немонетарного стимулирования // Информационно-управляющие системы. 2017. № 3. P. 104–114.
45. Загорулько Ю.А. Построение порталов научных знаний на основе онтологии // Вычислительные технологии. 2007. Vol. 12, № СВ 2.
46. Загорулько Ю.А. et al. Концепция и архитектура тематического интеллектуального научного интернет-ресурса // Труды XV Всероссийской научной конференции RCDL’2013. Ярославль: ЯрГУ, 2013. P. 57–62.
References
1. Wechsler D. Crowdsourcing as a method of transdisciplinary research-Tapping the full potential of participants // Futures. Elsevier Ltd, 2014. Vol. 60. P. 14–22.
2. Baev V., Sablok G., Minkov I. Next generation sequencing crowd sourcing at BIOCOMP: What promises it holds for us in future? // J. Comput. Sci. Elsevier B.V., 2014. Vol. 5, №
3. P. 325–326. 3.Ye H. (Jonathan), Kankanhalli A. Investigating the antecedents of organizational task crowdsourcing // Inf. Manag. Elsevier B.V., 2015. Vol. 52, № 1. P. 98–110.
4. Fraternali P. et al. Putting humans in the loop: Social computing for Water Resources Management // Environ. Model. Softw. Elsevier Ltd, 2012. Vol. 37. P. 68–77.
5. Nunes A. a., Galvão T., Cunha J.F.E. Urban Public Transport Service Co-creation: Leveraging Passenger’s Knowledge to Enhance Travel Experience // Procedia-Soc. Behav. Sci. Elsevier B.V., 2014. Vol. 111. P. 577–585.
6. Hetmank L. A Lightweight Ontology for Enterprise Crowdsourcing // Ecis. 2014. № section 4. P. Paper 886.
7. Thuan N.H. et al. Building an Enterprise Ontology of Business Process Crowdsourcing: a Design Science Approach // Proceedings of PACIS. 2015. № August.
8. Alabduljabbar R., Al-Dossari H. Ontology for Task and Quality Management in Crowdsourcing // Int. J. Comput. 2016. Vol. 22, № 1. P. 90–102.
9. Document Ontology [Electronic resource]. URL: http://www.cs.umd.edu/projects/plus/SHOE/onts/docmnt1.0.html (accessed: 08.06.2018).
10. Ontology of Rhetorical Blocks [Electronic resource]. URL: http://www.w3.org/2001/sw/hcls/notes/orb/#ontology (accessed: 08.06.2018).
11. SPAR [Electronic resource]. URL: http://purl.org/spar.
12. Ruiz-Iniesta A., Corcho O. A review of ontologies for describing scholarly and scientific documents // CEUR Workshop Proc. 2014. Vol. 1155.
13. Soldatova L., Liakata M. An ontology methodology and CISP-the proposed Core Information about Scientific Papers. 2007. № December.
14. Soldatova L.N., King R.D. An ontology of scientific experiments // J. R. Soc. Interface. 2006. Vol. 3, № 11. P. 795–803.
15. Liakata M. et al. Corpora for the conceptualisation and zoning of scientific papers // Proc. Lr. 2010. P. 2054–2061.
16. Ashburner M. et al. Gene Ontology: tool for the unification of biology // Nat. Genet. 2000. Vol. 25, № 1. P. 25–29.
17. Natale D.A. et al. The Protein Ontology: a structured representation of protein forms and complexes // Nucleic Acids Res. 2011. Vol. 39, № Database. P. D539–D545.
18. Arp R., Smith B., Spear A.D. Building Ontologies with Basic Formal Ontology. 2015. 248 p.
19. Yuen M.C., King I., Leung K.S. A survey of crowdsourcing systems // Proceedings-2011 IEEE International Conference on Privacy, Security, Risk and Trust and IEEE International Conference on Social Computing, PASSAT/SocialCom 2011. 2011. P. 766–773.
20. Yuen M.-C., Chen L.-J., King I. A Survey of Human Computation Systems // 2009 International Conference on Computational Science and Engineering. 2009. № July 2014. P. 723–728.
21. King I., Li J., Chan K.T. A brief survey of computational approaches in Social Computing // 2009 International Joint Conference on Neural Networks. 2009. P. 1625–1632.
22. Pedersen J. et al. Conceptual foundations of crowdsourcing: A review of IS research // Proc. Annu. Hawaii Int. Conf. Syst. Sci. 2013. P. 579–588.
23. Quinn A.J., Bederson B.B. Human Computation: A Survey and Taxonomy of a Growing Field // Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’11). 2011. P. 1403–1412.
24. Morschheuser B., Hamari J., Koivisto J. Gamification in crowdsourcing: A review // Proceedings of the Annual Hawaii International Conference on System Sciences. 2016. Vol. 2016–March. P. 4375–4384.
25. Hossain M., Kauranen I. Crowdsourcing: a comprehensive literature review // Strateg. Outsourcing An Int. J. 2015. Vol. 8, № 1. P. 2–22.
26. Senaratne H. et al. A review of volunteered geographic information quality assessment methods // Int. J. Geogr. Inf. Sci. 2016. Vol. 8816, № May. P. 1–29.
27. Li G. et al. Crowdsourced Data Management: A Survey // IEEE Trans. Knowl. Data Eng. 2016. Vol. 28, № 9. P. 2296–2319.
28. Buettner R. A Systematic Literature Review of Crowdsourcing Research from a Human Resource Management Perspective // 48th Hawaii International Conference on System Sciences (HICSS). 2015. P. 4609–4618.
29. Restuccia F. et al. Quality of Information in Mobile Crowdsensing: Survey and Research Challenges. 2017. Vol. 13, № 4.
30. Feng W. et al. A Survey on Security, Privacy and Trust in Mobile Crowdsourcing // IEEE Internet Things J. 2017. Vol. 4662, № c. P. 1–24.
31. Vergara-Laurens I.J., Jaimes L.G., Labrador M.A. Privacy-Preserving Mechanisms for Crowdsensing: Survey and Research Challenges // IEEE Internet Things J. 2017. Vol. 4, № 4. P. 855–869.
32. Tsvetkova M. et al. Understanding Human-Machine Networks: A Cross-Disciplinary Survey // ACM Comput. Surv. 2015. Vol. 50, № 1. P. Article 12.
33. Durward D., Blohm I., Leimeister J.M. Is There PAPA in Crowd Work? A Literature Review on Ethical Dimensions in Crowdsourcing // The IEEE International Conference on Internet of People,. 2016.
34. Ghezzi A. et al. Crowdsourcing: A Review and Suggestions for Future Research // Int. J. Manag. Rev. 2017. Vol. 0. P. 1–21.
35. Assis Neto F.R., Santos C.A.S. Understanding crowdsourcing projects: A systematic review of tendencies, workflow, and quality management // Inf. Process. Manag. 2018. Vol. 54, № 4. P. 490–506.
36. Daniel F. et al. Quality Control in Crowdsourcing: A Survey of Quality Attributes, Assessment Techniques and Assurance Actions. 2018. Vol. 0, № 0.
37. Ramírez-Montoya M.S., García-Peñalvo F.-J. Co-creation and open innovation: Systematic literature review // Comunicar. 2018. Vol. 26, № 54. P. 9–18.
38. Wazny K. Crowdsourcing’s ten years in: A review // J. Glob. Health. 2017. Vol. 7, № 2. P. 1–13.
39. Morschheuser B. et al. Gamified crowdsourcing: Conceptualization, literature review, and future agenda // Int. J. Hum. Comput. Stud. Elsevier Ltd, 2017. Vol. 106, № March 2016. P. 26–43.
40. Liang X., Yan Z. A survey on game theoretical methods in Human-Machine Networks // Futur. Gener. Comput. Syst. Elsevier B.V., 2017.
41. Sandkuhl K., Smirnov A., Ponomarev A. Crowdsourcing in business process outsourcing: An exploratory study on factors influencing decision making // Lecture Notes in Business Information Processing. 2016. Vol. 261.
42. Smirnov A., Ponomarev A. Exploring Requirements for Multipurpose Crowd Computing Framework // ESOCC 2015: Advances in Service-Oriented and Cloud Computing. Springer, 2016. P. 299–307.
43. Ponomarev A.V. Metody obespecheniya kachestva v sistemakh kraud-vychislenii: analiticheskii obzor // Trudy SPIIRAN. 2017. Vol. 54, № 5. P. 152–184.
44. Ponomarev A.V. Razmetka izobrazhenii massovogo meropriyatiya ego uchastnikami na osnove nemonetarnogo stimulirovaniya // Informatsionno-upravlyayushchie sistemy. 2017. № 3. P. 104–114.
45. Zagorul'ko Yu.A. Postroenie portalov nauchnykh znanii na osnove ontologii // Vychislitel'nye tekhnologii. 2007. Vol. 12, № SV 2.
46. Zagorul'ko Yu.A. et al. Kontseptsiya i arkhitektura tematicheskogo intellektual'nogo nauchnogo internet-resursa // Trudy XV Vserossiiskoi nauchnoi konferentsii RCDL’2013. Yaroslavl': YarGU, 2013. P. 57–62.
|
 Рус
Рус










