|
Кибернетика и программирование
Правильная ссылка на статью:
Башмаков Д.А.
Точность предсказания пикселей фоновых областей цифровых изображений в задаче стеганоанализа методом Weighted Stego
// Кибернетика и программирование.
2018. № 2.
С. 38-47.
DOI: 10.25136/2644-5522.2018.2.25706 URL: https://nbpublish.com/library_read_article.php?id=25706
Точность предсказания пикселей фоновых областей цифровых изображений в задаче стеганоанализа методом Weighted Stego
Башмаков Даниил Андреевич
аспирант, кафедра Проектирования и безопасности компьютерных систем, федеральное государственное автономное образовательное учреждение высшего образования «Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики»
197101, Россия, Ленинградская область, г. Санкт-Петербург, Кронверкский проспект, 49
Bashmakov Daniil Andreevich
post-graduate student of the Department of Computing System Design and Safety at ITMO University (Saint Petersburg National Research University of Information Technologies, Mechanics and Optics)
197101, Russia, Leningradskaya oblast', g. Saint Petersburg, Kronverkskii prospekt, 49

|
bashmakov.dan@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.25136/2644-5522.2018.2.25706
Дата направления статьи в редакцию:
12-03-2018
Дата публикации:
23-04-2018
Аннотация:
Предметом исследования является точность функции предсказания пикселей фоновых областей неподвижных цифровых изображений методом Weighted Stego Image в задачах пассивного противодействия каналам передачи данных, использующим метод встраивания в наименьший значащий бит пространственной области неподвижных цифровых изображений со значительной долей однородного фона. Анализируется зависимость точности определения длины встроенного сообщения от точности предсказания пикселей фоновых областей изображения. Рассматривается оригинальный алгоритм Weighted Stego Image и ряд его модификаций, в том числе AWSPAM. Анализируется формула оценки длины встроенного сообщения и связь её точности с точностью функции предсказания пикселя. Точность предсказания пикселей оценивается как распределение вероятности ошибки между предсказанным и реальным значением. Точность алгоритма стеганоанализа оценивается как доля ложноположительных классификаций при заданной доле корректных классификаций. Показана недостаточность данных о непосредственно окружающих пикселях для точного предсказания пикселя. Показана связь точности функции предсказания пикселя с точностью оценки длины встроенного сообщения, и, следовательно, с точностью классификации методом Weighted Stego. Показана наибольшая точность функции предсказания пикселя, предложенной в алгоритме AWSPAM по сравнению с функцией предсказания оригинального алгоритма и прочих его модификаций.
Ключевые слова:
стеганография, стеганоанализ, бинарная классификация, младший значащий бит, пассивное противодействие, статистический стеганоанализ, пространственная область изображения, точность метода стеганоанализа, стеганографическое встраивание, алгоритм стеганоанализа
Abstract: The subject of the research is the accuracy of predicting pixels of background areas of static digital images using the Weighted Stego Image method as part of passive resistance to data transmission channels that use the method of embedding the spatial domain of static digital images with a significant share of homogeneous background in the least significant bit. In his research Bashmakov analyzes the dependence of the accuracy of defining the length of an embedded message on the accuracy of pixel prediction of the image background area. The author focuses on an original algorithm Weighted Stego Image and a number of modifications thereof including the AWSPAM version. He analyzes the formula for calculating an embedded message length and the relationship between its accuracy and the accuracy of pixel prediction. The pixel prediction accuracy is viewed as an error distribution between the predicted and actual values. The accuracy of the stegoanalysis algorithm is viewed as the share of false-positive classifications given the share of correct classifications. The author demonstrates that information about surrounding pixels is not enought for an accurate prediction of pixel and proves that there is a certain relationship between the accuracy of pixel predition and accuracy of an embedded message length, or, in other words, accuracy of the classification using the Weighted Stego method. The author also demonstrates that the AWSPAM algorithm can predict pixels with the highest accuracy compared to the original algorithm prediction function and other modifications thereof.
Keywords: steganography, steganalysis, binary classification, least significant bit, passive resistance, statistical steganalysis, image spatial domain, steganalysis method accuracy, steganographic embedding, steganalytic algorithm
Введение
Стеганография с использованием неподвижных цифровых изображений в качестве контейнера находит широкое применение как легальное, так и в преступных целях [1]. Это обуславливает актуальность стеганоанализа как средства противодействия стеганографическим каналам передачи информации. Встраивание информации в наименьший значащий бит относится к наиболее простым и доступным методам стеганографии, не требующим использования сложного программного обеспечения и значительных аппаратных ресурсов [2]. В то же время, возможности современных алгоритмов стеганоанализа по выявлению факта встраивания в LSB на малых значениях полезной нагрузки не позволяют организовать эффективное противодействие стеганографическому каналу, использующему LSB-встраивание [3, 10].
Алгоритм стеганоанализа Weighted Stego (WS) [4] и ряд его модификаций [5 - 9] показывают наилучшую точность в детектировании факта LSB-встраивания. В то же время, исследования показывают, что при анализе изображений со значительной долей однородного фона алгоритм WS работает с пониженной точностью [8, 9]. В работах [8, 9] приводятся способы нивелировать потерю точности при анализе изображений со значительной долей однородного фона, однако не анализируются причины падения точности анализа в фоновых областях и не приводится данных по точности предсказания различными методами. Требуется изучение причин понижения точности анализа в фоновых областях и выделение оптимального способа анализа в фоновой области.
Цель работы
В работе приводится анализ причин падения точности стеганоанализа методом WS в фоновых областях неподвижных цифровых изображений, анализируются причины некорректного предсказания пикселей фоновых областей. Оценивается точность предсказания пикселей фоновой области изображения с помощью различных известных моделей предсказания. Определяется наиболее оптимальный способ предсказания в фоновой области.
Методика проведения экспериментов
Эксперименты проводятся на множестве тестовых изображений, являющихся цифровыми фотографиями. Поскольку рассматриваемая проблема падения точности проявляется при анализе изображений со значительной долей однородного фона, множество подразделяется на выборки HB и LB:
· Выборка HB содержит изображения, в которых доля однородного фона превышает 40%;
· Выборка LB содержит изображения, в которых доля однородного фона не превышает 5%.
Изображения, не попавшие ни в одну из выборок, удаляются из тестового множества.
Выделение фона для оценки его доли в изображении производится методом, описанным в работе [9].
После удаления изображений, не попавших в выборки HB и LB, каждая из выборок также подразделяется на две подвыборки – чистых изображений и стеганограмм. Для стеганограмм имитируется последовательное LSB-встраивание на различных значениях полезной нагрузки, не превышающих 5%.
При анализе изображения оценивается точность предсказания пикселей анализатором, лежащим в основе алгоритма WS. Чистые изображения и стеганограммы анализируются алгоритмом WS для определения точности классификации отдельно в каждой из выборок. Полученные значения оценены численно, зависимость от характеристик изображений и значений полезных нагрузок приведены в виде графиков.
Условия проведения экспериментов
Для формирования исходного множества тестовых изображений используется коллекция изображений BOWS2, широко используемая в качестве тестового множества при определении точности стеганоанализа различными алгоритмами [11].
Мощность изначальной тестовой выборки – 10000 изображений разрешениями от 300х400 до 4000х5000 пикселей. После выделения выборок HB и LB мощность выборки составляет 7000 изображений.
Моделирование стеганографического встраивания в цветных изображениях производится раздельно по каждой цветовой плоскости. Результаты, полученные для трёх цветовых плоскостей, усредняются. В случае если изображение оригинально представлено в оттенках серого, используется единственная доступная цветовая плоскость.
Способ оценки точности методов стеганоанализа
Алгоритм статистического стеганоанализа WS и его модификации, рассматриваемые в статье, в качестве результата работы имеют оценку длины встроенного в LSB пикселей сообщения. При построении систем детектирования факта стеганографического встраивания к результату работы алгоритма применяется бинарная классификация. Из превышения оцененной длинной сообщения определённого порога делается вывод о наличии либо отсутствии факта стеганографического встраивания в сообщение.
Идеальный классификатор всегда определяет оригинальные изображения как чистые (True Negative, TN) и модифицированные – как стеганограммы (True Positive, TP). В реальных условиях классификатор может допускать ошибки, классифицируя оригинальные изображения как стеганограммы (False Positive, FP) и модифицированные изображения как чистые (False Negative, FN). Распределение доли классификации по классам зависит от корректности оценки длины сообщения алгоритмом. В качестве оценки точности стеганоанализа используется процент некорректной классификации при заданном проценте корректной классификации.
При анализе точности функции предсказания пикселей в фоновых областях в качестве метрики точности используется отклонение предсказанного значения от действительного, усреднённое по фоновой области изображения, и, далее, по всем изображениям выборки.
Анализ причин падения точности при работе в фоновых областях изображения
При стеганоанализе методов WS оценивается длина встроенного в изображение сообщения. Дальнейший вывод о наличии или отсутствии встроенного сообщения зависит от выбранного порога. Тем не менее, правильность оценки длины сообщения напрямую влияет на точность итоговой классификации.
В работе [8] показан эффект падения точности стеганоанализа при работе на изображениях со значительной долей однородного фона. В статье представлен итоговый эффект, который может быть вызван двумя факторами:
· При рассмотрении системы как бинарного анализатора – за счёт завышения доли положительных или отрицательных ложных срабатываний алгоритма при работе на выборке HB;
· При рассмотрении алгоритма, оценивающего длину встроенного сообщения – за счёт системного завышения или занижения оцененной длины сообщения на выборке HB по сравнению с таковой на выборке LB.
Для выявления доли положительных и отрицательных ложных срабатываний оценена доля положительных и отрицательных ложных классификаций среди всех классификаций на подвыборках только чистых изображений и только стеганограмм соответственно. Точность оценивалась раздельно для выборок HB и LB. Полезная нагрузка встраивания 3%. Результаты приведены в таблице 1.
|
Выборка / Подвыборка
|
HB
|
LB
|
|
Чистые изображения (Доля ПЛК)
|
22,4%
|
13,1%
|
|
Стеганограммы (Доля ОЛК)
|
10,0%
|
9.5%
|
Таблица 1 – Доля ложных классификаций в зависимости от доли фоновой области изображения
Для оценки смещения длины предсказанного сообщения алгоритм запущен на подвыборке стеганограмм с постоянной полезной нагрузкой и абсолютной длиной встроенного сообщения раздельно для выборок HB и LB. Для обеспечения постоянной абсолютной длины встроенного сообщения при постоянной полезной нагрузке использованы только изображения одинаковых разрешений. Оценено отклонение предсказанной длины сообщения в процентах от действительной длины сообщения (положительный процент означает завышение длины, отрицательный – занижение). Результаты представлены в таблице 2.
|
Нагрузка / Подвыборка
|
HB
|
LB
|
|
5%
|
21,0%
|
8,3%
|
|
3%
|
26,8%
|
10,7%
|
|
1%
|
34,9%
|
15,4%
|
Таблица 2 – Отклонение предсказанной длины сообщения в зависимости от доли фоновой области изображения
Как видно из таблиц 1 и 2, падение точности стеганоанализа обеспечено практически полностью повышенной долей положительных ложных классификаций. Повышенная доля ПЛС, в свою очередь, обеспечена завышением оцененной длины встроенного сообщения по сравнению с действительной длиной. Для повышения точности стеганоанализа в фоновых областях требуется повысить точность оценки длины встроенного сообщения.
Для понимания причины завышения оцененной длины следует обратиться к итоговой формуле длины сообщения, приведённой в [4]:
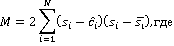 
Из формулы очевидно, что итоговая длина сообщения складывается из разности между предсказанным и действительным пикселем изображения-стеганограммы. Множитель 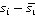 не зависит ни от чего, кроме одного отдельно взятого пикселя изображения для каждого слагаемого итоговой суммы, и, следовательно, распределение его значений очевидно не зависит от доли фона в анализируемом изображении. Учитывая, что растёт именно доля положительных ложных срабатываний, то есть, эффект наблюдается в том числе при анализе только чистых изображений, можно предположить, что в фоновых областях систематически завышается предсказанное значение пикселя по отношению к реальному в тех случаях, когда не зависит ни от чего, кроме одного отдельно взятого пикселя изображения для каждого слагаемого итоговой суммы, и, следовательно, распределение его значений очевидно не зависит от доли фона в анализируемом изображении. Учитывая, что растёт именно доля положительных ложных срабатываний, то есть, эффект наблюдается в том числе при анализе только чистых изображений, можно предположить, что в фоновых областях систематически завышается предсказанное значение пикселя по отношению к реальному в тех случаях, когда 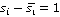 . Для проверки этого предположения алгоритм запущен на подвыборке чистых изображений отдельно для выборок HB и LB. График на рисунке 1 показывает характер распределения разности предсказанного и реального значения пикселя . Для проверки этого предположения алгоритм запущен на подвыборке чистых изображений отдельно для выборок HB и LB. График на рисунке 1 показывает характер распределения разности предсказанного и реального значения пикселя 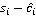 для для двух выборок. для для двух выборок.
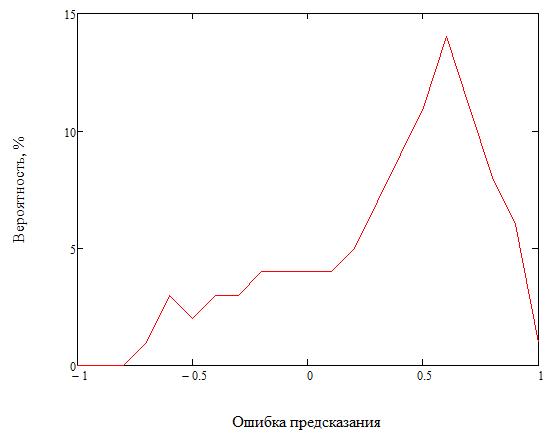
Рисунок 1 – Распределение вероятности ошибки предсказания пикселя методом WS
Из графика на рисунке 1 видно, что при анализе изображений со значительной долей фона предсказанное значение действительно имеет пик вероятности в зоне завышения. Это объясняет высокую долю положительных ложных срабатываний.
Точность предсказания пикселей с использованием различных моделей предсказания
График на рисунке 1 показывает завышение предсказанного значения пикселя при использовании стандартной модели предсказания, предложенной авторами алгоритма в [5]. Модель предсказания пикселя проста и описывается формулой:
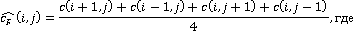 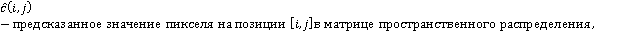 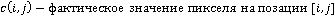
Таким образом, при предсказании каждого конкретного пикселя полной информацией для функции предсказания являются четыре его соседних пикселя (без учёта диагонально расположенных к данному). Ясно, что общее завышение предсказанного значения, так или иначе, складывается из завышения в каждом конкретном случае.
Выделение случаев, наиболее часто влияющих на точность предсказания может помочь нивелировать завышение. Попытка рассмотрения комбинаций значения предсказанного и окружающих пикселей для выборки тестовых изображений ожидаемо даёт огромное число различных комбинаций: фоновая область изображения сама по себе может быть в целом светлее или темнее от изображения к изображению. Однако, анализатор каждый раз работает на одном конкретном изображении, и оттенок и яркость фона данного изображения по сравнению с другими из той же выборки не имеет значения. Следовательно, можно нормировать значения фоновых пикселей по отношению к среднему значению яркости фоновой области (для каждой цветовой плоскости отдельно):

В результате нормирования и выделения фона для изображения получим множество нормированных фоновых пикселей 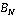 . Набор полной информации предсказателя в данном случае можно представить в виде четырёх соседних нормированных пикселей. Для оценки точности предсказания также следует добавить в набор действительное и предсказанное значение пикселя. Для определения типичных наборов, вводящих наибольшую ошибку предсказания, оценено количество уникальных наборов четырёх соседей пикселя, ведущих к ошибке предсказания более чем на 0,5 относительно реального пикселя изображения. Для тестовой выборки в среднем для одного изображения количество таких уникальных наборов составляет 317. Такое количество не даёт возможности введения индивидуальных правил предсказания для каждого набора за разумное время. Следовательно, для улучшения точности предсказания следует изменить общую функцию предсказания пикселей изображения. . Набор полной информации предсказателя в данном случае можно представить в виде четырёх соседних нормированных пикселей. Для оценки точности предсказания также следует добавить в набор действительное и предсказанное значение пикселя. Для определения типичных наборов, вводящих наибольшую ошибку предсказания, оценено количество уникальных наборов четырёх соседей пикселя, ведущих к ошибке предсказания более чем на 0,5 относительно реального пикселя изображения. Для тестовой выборки в среднем для одного изображения количество таких уникальных наборов составляет 317. Такое количество не даёт возможности введения индивидуальных правил предсказания для каждого набора за разумное время. Следовательно, для улучшения точности предсказания следует изменить общую функцию предсказания пикселей изображения.
В [6] авторами предложен также усовершенствованный метод предсказания, оперирующий восемью соседними пикселями. Предсказание в этом случае осуществляется по формуле:
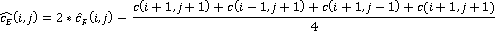
График на рисунке 2 показывает характер распределения разности предсказанного и реального значения пикселя при предсказании по восьми соседним пикселям.
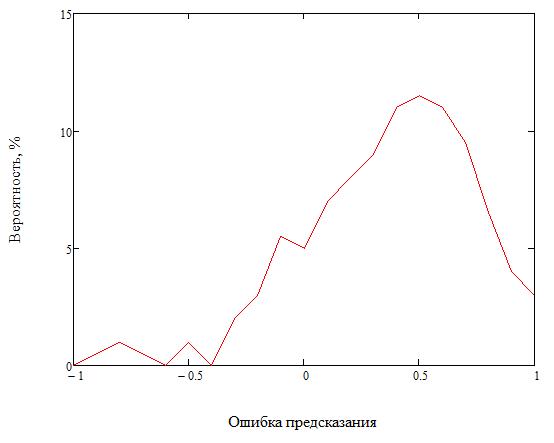
Рисунок 2 - Распределение вероятности ошибки предсказания пикселя методом WS с восемью соседними пикселями
Как видно из рисунка 2, метод не позволяет значительно снизить разницу между предсказанным и действительным значением пикселя.
Факт неточного предсказания приведёнными выше методами позволяет сделать вывод: окружающих пикселей в фоновых областях недостаточно для эффективного предсказания значения пикселя. В то же время, включение в модель предсказания соседей следующих порядков (отстоящих на 2 и более пикселей от предсказываемого) приводит к слишком сильному разрастанию карты соответствия, являя собой одно из проявлений «проклятия размерности» (“the curse of dimensionality”) [13]. Для преодоления «проклятия размерности» требуется исключить «лишние» измерения из предсказания. Это сделано в методе предсказания по матрице соседства пикселей, описанной в [8]. В статье приводятся данные по увеличению точности анализа алгоритмом WS изображений со значительной долей однородного фона при применении указанной модели предсказания.
График на рисунке 3 показывает характер распределения разности предсказанного и реального значения пикселя в фоновой области при применении модели предсказания по матрице соседства пикселей.
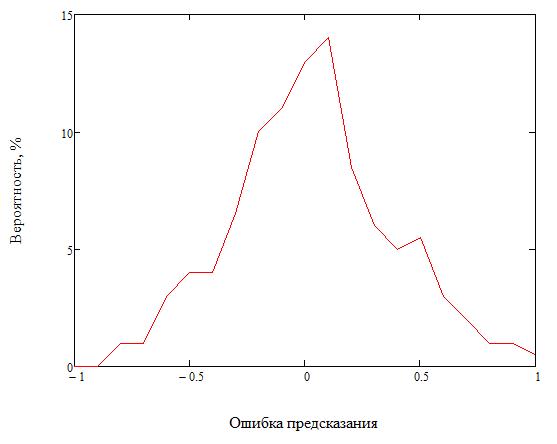
Рисунок 3 - Распределение вероятности ошибки предсказания пикселя методом AWSPAM
Видно, что при использовании модели предсказания по матрице соседства пикселей точность предсказания значительно выше, и пик вероятности распределения ошибки предсказания лежит левее значения x=0.5, что критически важно для итоговой точности анализа методом WS, что обсуждается в работе [9].
Оценка практической эффективности применения различных моделей предсказания в фоновой области
Поскольку падение точности стеганоанализа, как показано выше, обуславливалось высокой долей положительных ложных срабатываний классификатора, для подтверждения практической эффективности применения альтернативных моделей предсказания оценена доля ПЛС при доле корректной классификации 95% при анализе чистых выборок алгоритмом WS с различными моделями предсказания. Результаты приведены для выборки HB, иллюстрируя падение доли ПЛС в фоновых областях. Таблица 3 содержит численные оценки доли ПЛС для различных значений полезной нагрузки при использовании рассмотренных выше моделей предсказания.
|
Модель / Нагрузка
|
1%
|
3%
|
5%
|
|
4 соседа [5]
|
26%
|
17%
|
16%
|
|
8 соседей [6]
|
22%
|
16%
|
16%
|
|
Матрица соседства (SPAM) [12]
|
19%
|
14%
|
13%
|
|
Матрица соседства (AWSPAM) [8, 9]
|
11%
|
8%
|
3%
|
Таблица 3 – Доли ПЛС для различных функций предсказания пикселя
Обсуждение результатов
Алгоритм WS показывает высокую точность детектирования факта встраивания в LSB неподвижных цифровых изображений. В то же время, алгоритм уязвим при анализе изображений со значительной долей однородного фона. Уязвимость проявляется за счёт системного завышения оцененной длины встроенного сообщения, что обеспечивает высокую долю положительных ложных срабатываний.
Использование моделей предсказания, основанных на задействовании непосредственно соседних с предсказываемым пикселей не позволяет снизить ошибку предсказания в степени, достаточной для того, чтобы значительно снизить процент положительных ложных срабатываний алгоритма.
Включение в модель предсказания большего числа окружающих пикселей, с учётом противодействия «проклятию размерности» позволяет снизить ошибку предсказания в фоновой области, выводя среднее значение ошибки предсказания в диапазон [0; 0.5], что, в свою очередь, позволяет повысить итоговую точность анализа в изображениях со значительной долей однородного фона.
Заключение
В работе проведён анализ причин падения точности стеганоанализа методом Weighted Stego при работе на изображениях со значительной долей однородного фона. Рассмотрены причины, приводящие к некорректному предсказыванию пикселей в фоновой области, объяснена связь некорректного предсказания пикселей с итоговой точностью стеганоанализа.
Проведён сравнительный анализ точности предсказания пикселей в фоновых областях при использовании различных моделей предсказания. Определена модель, позволяющая добиться минимизации ошибки предсказания пикселя в фоновой области – модель предсказания по матрице соседства пикселей, представленная в работе [8].
Библиография
1. Steganography: A Powerful Tool for Terrorists and Corporate Spies // Stratfor [Электронный ресурс]. Режим доступа: https://www.stratfor.com/analysis/steganography-powerful-tool-terrorists-and-corporate-spies, свободный. Яз. англ. (дата обращения 22.08.2017).
2. Gayathri C., Kalpana V. Study on image steganography techniques // International Journal of Engineering and Technology (IJET). 2013. V. 5. P. 572–577.
3. Prokhozhev N., Mikhailichenko O., Sivachev A., Bashmakov D., Korobeynikov A.G. Passive Steganalysis Evaluation: Reliabilities of Modern Quantitative Steganalysis Algorithms // Advances in Intelligent Systems and Computing. 2016. V. 451. Р. 89–94. doi:10.1007/978-3-319-33816-3_9
4. Jessica Fridrich, Miroslav Goljan, "On estimation of secret message length in LSB steganography in spatial domain", Proc. SPIE 5306, Security, Steganography, and Watermarking of Multimedia Contents VI, (22 June 2004); doi: 10.1117/12.521350; https://doi.org/10.1117/12.521350
5. Ker, Andrew. (2007). A Weighted Stego Image Detector for Sequential LSB Replacement. Proceedings-IAS 2007 3rd Internationl Symposium on Information Assurance and Security. 453-456. 10.1109/IAS.2007.71.
6. Andrew D. Ker, Rainer Böhme, "Revisiting weighted stego-image steganalysis", Proc. SPIE 6819, Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, 681905 (18 March 2008); doi: 10.1117/12.766820; https://doi.org/10.1117/12.766820
7. Xiaoyi Yu and Noboru Babaguchi, "Weighted stego-Image based steganalysis in multiple least significant bits," 2008 IEEE International Conference on Multimedia and Expo, Hannover, 2008, pp. 265-268.
8. Башмаков Д.А., Прохожев Н.Н., Михайличенко О.В., Сивачев А.В. Применение матриц соседства пикселей для улучшения точности стеганоанализа неподвижных цифровых изображений с однородным фоном // Кибернетика и программирование. — 2018.-№ 1.-С.64-72. DOI: 10.25136/2306-4196.2018.1.24919. URL: http://e-notabene.ru/kp/article_24919.html
9. Башмаков Д.А. Адаптивное предсказание пикселей в градиентных областях для улучшения точности стеганоанализа в неподвижных цифровых изображениях // Кибернетика и программирование. — 0.-№ 0.-С.0-0. DOI: 10.25136/2306-4196.0.0.25514. URL: http://e-notabene.ru/kp/article_25514.html (Статья ожидает публикации)
10. Прохожев Н.Н., Михайличенко О.В., Башмаков Д.А., Сивачев А.В., Коробейников А.Г. Исследование эффективности применения статистических алгоритмов количественного стеганоанализа в задаче детектирования скрытых каналов передачи информации // Программные системы и вычислительные методы. 2015. № 3. С. 281–292. doi: 10.7256/2305-6061.2015.3.17233
11. BOWS2 the 10 000 original images [Электронный ресурс]. Режим доступа: http://bows2.ec-lille.fr/, свободный. Яз. англ. (дата обращения 12.04.2017).
12. T. Pevny, P. Bas and J. Fridrich, "Steganalysis by Subtractive Pixel Adjacency Matrix," in IEEE Transactions on Information Forensics and Security, vol. 5, no. 2, pp. 215-224, June 2010. doi: 10.1109/TIFS.2010.2045842
13. Richard Ernest Bellman. Dynamic Programming. — Courier Dover Publications, 2003. — ISBN 978-0-486-42809-3
References
1. Steganography: A Powerful Tool for Terrorists and Corporate Spies // Stratfor [Elektronnyi resurs]. Rezhim dostupa: https://www.stratfor.com/analysis/steganography-powerful-tool-terrorists-and-corporate-spies, svobodnyi. Yaz. angl. (data obrashcheniya 22.08.2017).
2. Gayathri C., Kalpana V. Study on image steganography techniques // International Journal of Engineering and Technology (IJET). 2013. V. 5. P. 572–577.
3. Prokhozhev N., Mikhailichenko O., Sivachev A., Bashmakov D., Korobeynikov A.G. Passive Steganalysis Evaluation: Reliabilities of Modern Quantitative Steganalysis Algorithms // Advances in Intelligent Systems and Computing. 2016. V. 451. R. 89–94. doi:10.1007/978-3-319-33816-3_9
4. Jessica Fridrich, Miroslav Goljan, "On estimation of secret message length in LSB steganography in spatial domain", Proc. SPIE 5306, Security, Steganography, and Watermarking of Multimedia Contents VI, (22 June 2004); doi: 10.1117/12.521350; https://doi.org/10.1117/12.521350
5. Ker, Andrew. (2007). A Weighted Stego Image Detector for Sequential LSB Replacement. Proceedings-IAS 2007 3rd Internationl Symposium on Information Assurance and Security. 453-456. 10.1109/IAS.2007.71.
6. Andrew D. Ker, Rainer Böhme, "Revisiting weighted stego-image steganalysis", Proc. SPIE 6819, Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, 681905 (18 March 2008); doi: 10.1117/12.766820; https://doi.org/10.1117/12.766820
7. Xiaoyi Yu and Noboru Babaguchi, "Weighted stego-Image based steganalysis in multiple least significant bits," 2008 IEEE International Conference on Multimedia and Expo, Hannover, 2008, pp. 265-268.
8. Bashmakov D.A., Prokhozhev N.N., Mikhailichenko O.V., Sivachev A.V. Primenenie matrits sosedstva pikselei dlya uluchsheniya tochnosti steganoanaliza nepodvizhnykh tsifrovykh izobrazhenii s odnorodnym fonom // Kibernetika i programmirovanie. — 2018.-№ 1.-S.64-72. DOI: 10.25136/2306-4196.2018.1.24919. URL: http://e-notabene.ru/kp/article_24919.html
9. Bashmakov D.A. Adaptivnoe predskazanie pikselei v gradientnykh oblastyakh dlya uluchsheniya tochnosti steganoanaliza v nepodvizhnykh tsifrovykh izobrazheniyakh // Kibernetika i programmirovanie. — 0.-№ 0.-S.0-0. DOI: 10.25136/2306-4196.0.0.25514. URL: http://e-notabene.ru/kp/article_25514.html (Stat'ya ozhidaet publikatsii)
10. Prokhozhev N.N., Mikhailichenko O.V., Bashmakov D.A., Sivachev A.V., Korobeinikov A.G. Issledovanie effektivnosti primeneniya statisticheskikh algoritmov kolichestvennogo steganoanaliza v zadache detektirovaniya skrytykh kanalov peredachi informatsii // Programmnye sistemy i vychislitel'nye metody. 2015. № 3. S. 281–292. doi: 10.7256/2305-6061.2015.3.17233
11. BOWS2 the 10 000 original images [Elektronnyi resurs]. Rezhim dostupa: http://bows2.ec-lille.fr/, svobodnyi. Yaz. angl. (data obrashcheniya 12.04.2017).
12. T. Pevny, P. Bas and J. Fridrich, "Steganalysis by Subtractive Pixel Adjacency Matrix," in IEEE Transactions on Information Forensics and Security, vol. 5, no. 2, pp. 215-224, June 2010. doi: 10.1109/TIFS.2010.2045842
13. Richard Ernest Bellman. Dynamic Programming. — Courier Dover Publications, 2003. — ISBN 978-0-486-42809-3
|
 Рус
Рус












