|
Исторический журнал: научные исследования
Правильная ссылка на статью:
Шпирко С.В., Баранкова Г.С.
Применение одного математического подхода к задаче генеалогической классификации текстов списков средневекового произведения (на примере «Закона Судного людем»)
// Исторический журнал: научные исследования.
2017. № 5.
С. 37-69.
DOI: 10.7256/2454-0609.2017.5.24088 URL: https://nbpublish.com/library_read_article.php?id=24088
Применение одного математического подхода к задаче генеалогической классификации текстов списков средневекового произведения (на примере «Закона Судного людем»)
Шпирко Сергей Валерьевич
кандидат физико-математических наук, кандидат исторических наук
доцент, Российский Государственный Гуманитарный Университет, Историко-Архивный институт
119313, Россия, г. Москва, Ленинский проспект, 88, корп. 3
Shpirko Sergey
Associate Professor, Moscow State Historical Archives Institute, Russian State University for the Humanities
119313, Russia, g. Moscow, ul. Leninskii Prospekt, 88 korpus 3, kv. 122

|
shpirkos@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
Баранкова Галина Серафимовна
кандидат филологических наук
ведущий научный сотрудник, Институт русского языка им. В.В. Виноградова РАН
141076, Россия, Московская область, г. Королев, ул. Калининградская, 17, корп. 2
Barankova Galina
PhD in Philology
BARANKOVA Galina Serafimovna – Senior Research Associate, V. V. Vinogradov Institute of Russian Language of the Russian Academy of Sciences;
Kaliningradskaya ulitsa 17/2 apt. 278, Korolev, Moskovskaya oblast’ 141076 Russia
141076, Russia, Moskovskaya oblast', g. Korolev, ul. Kaliningradskaya, 17 korpus 2, kv. 278
|
|
barankova@inbox.ru
|
|
|
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0609.2017.5.24088
Дата направления статьи в редакцию:
04-09-2017
Дата публикации:
02-11-2017
Аннотация:
Предметом исследования является формализованная классификация сохранившихся списков средневекового произведения «Закон Судный людем», которое является древнейшим переводным памятником славянского права и одним из самых древних текстов на славянском языке. Для решения задачи текстологической классификации автором была предложена модель, опирающаяся на естественные предположения относительно процесса копирования списков и разработан метод, базирующийся на идее применения теории нечетких множеств. Преимущество нечеткого подхода заключается в построении стеммы списков с заданным уровнем надежности, учитывающей возможную контаминацию списков. Предложенный метод основан на формализованном анализе матрицы нечеткого отношения предпочтения, сформированной в результате попарного сличения текстов списков. Для количественной оценки вклада отдельных разночтений была разработана типологизация разночтений и развит метод косвенной экспертизы. Настоящая статья описывает первый опыт применения метода нечеткой генеалогической классификации к крупной рукописной традиции (57 списков, около 6500 разночтений). Полученные результаты в целом не противоречат результатам традиционного текстологического анализа и иных формализованных методов и позволяют уточнить группировку отдельных списков и их взаимосвязи. Разработанный подход является универсальным и может быть применен для классификации других рукописных текстов.
Ключевые слова:
текстология, разночтения, нечеткая классификация, контаминация, матрица нечеткого отношения, стемма, типологизация, теория нечетких множеств, непрямой экспертный метод, весовые коэффициенты
Статья подготовлена в рамках проекта, поддержанного Российским фондом фундаментальных исследований (РФФИ), грант N 16-06-00365 A «Историко-текстологический анализ средневековых русских текстов на основе применения подходов, алгоритмов и программы нечеткой классификации»
Abstract: The subject of this study is the formalized classification of the surviving copies of the medieval Slavic text "Zakon Sudnyj Ljudem", which is the oldest transferred monument of Slavic law and one of the earliest texts in the Slavic language. To resolve the difficulty of textological classification, the authors propose a model based on natural assumptions regarding the process of copying texts and have developed a method using the idea of applying the fuzzy set theory. The advantage of the fuzzy approach is the building of a stemma of the existing copies with their given level of reliability, taking into account their possible contamination. The proposed method is based on a formalized analysis of the fuzzy relation preference matrix, formulated as a result of a pairwise textual comparison of copies. To quantify the contribution of every reading discrepancy, a typology of readings was created, as well as an indirect estimation method was developed. This article describes the first experiment of applying the fuzzy genealogical classification method to a large manuscript tradition (57 copies, about 6500 readings). The obtained results as a whole do not contradict the results of the traditional textological analysis or other formalized methods and allow us to specify the grouping of copies and their interrelations. The developed approach is universal and can be applied to the classification of other manuscript texts.
Keywords: weight coefficients, indirect expert method, fuzzy set theory, typology, stemma, fuzzy relation matrix, contamination, fuzzy classification, readings, textology
Разрабатывать и применять формализованные методы к задачам текстологической классификации начинают с 1960-х гг. Такие методы традиционно делят на две категории - кластерные (от англ. cluster – пучок) и кладистические (от др.-греч. κλάδος – ветвь) [1]. Если первые ставят перед собой цель выделить текстологически близкие группы из сохранившихся списков, то вторые нацелены на выяснение истории бытования письменного текста, установления его архетипа – текста, наиболее близкого к оригиналу. Кластерный подход для задач текстологии был впервые предложен в начале 1960-х гг. выдающимся библеистом Э. Колвеллом [2]. Позже данный подход был творчески развит в работах голландских (А. Деес [3], Э. Ваттель [4]) и российского (А.А. Алексеев [5]) ученых. В основе всех кластерных методов лежит попарное сравнение (сличение) текстов списков и анализ таблицы с количественной оценкой попарной близости списков (матрицы расстояния).
1. Кластерные методы
В процессе попарного сличения выделяются узлы разночтений и подсчитывается число общих чтений. Разделив данное число на общее число узлов получаем так называемый коэффициент близости (процент совпадения). Предполагается, что чем больше (ближе к единице) данный коэффициент, тем ближе «генеалогически» пара списков друг к другу. И, наоборот, чем данный коэффициент меньше (ближе к нулю), тем более независима соответствующая пара списков. Далее из этих коэффициентов формируется таблица (матрица близости). Каждая строка и каждый столбец этой матрицы соответствует определенному списку, а на их пересечении стоит процент совпадения соответствующей пары списков. Не трудно видеть, что в данной матрице пары элементов, стоящие зеркально относительно главной диагонали, имеют одинаковые значения (такая матрица называется симметричной).
Общий подход заключается в перегруппировке строк и столбцов матрицы таким образом, чтобы рядом стояли списки с максимально большими коэффициентами. Различие между кластерными методами заключается в порядке группировки. Например, можно рассматривать списки в порядке убывания коэффициентов. Вначале выбирается максимально большой коэффициент, и соответствующая пара списков образует первую группу. Далее находится следующий по величине коэффициент. Соответствующая пара либо образует новую группу, либо включается в первую. И так далее до тех пор, пока не будут перебраны все списки. Переставленные списки в итоговой матрице будут следовать в том же порядке, в каком они объединялись в группы. Данный подход был предложен и успешно применен Э. Колвеллом для классификации греческой новозаветной традиции [2].
Несмотря на изящность и простоту, данный подход обладает рядом недостатков. Как отмечают сами авторы данного подхода (Э. Колвелл, Э. Тьюн), процесс группировки неустойчив – изменение порядка рассмотрения списков может привести к иным результатам. Это обусловлено размытостью границ выделенных групп (кластеров) – список невозможно однозначно отнести к тому или иному кластеру.
Также добавим следующие замечания: 1) поскольку матрица близости симметрична, то хронологическое упорядочивание выявленных групп приходится проводить из эвристических соображений; 2) при вычислении коэффициентов близости необходимо учитывать разную значимость слов для целей группировки. Таким образом, возникает задача типологизации чтений и формализованного оценивания их значимости (весовые коэффициенты).
Среди кладистических подходов остановимся подробнее на методе групп, разработанном французским текстологом Д.Ж. Фроже [6] и творчески развитом группой московских ученых во главе с Л.В. Миловым и Л.И. Бородкиным [7].
2. Метод групп
В отличие от других формализованных подходов метод групп не основан на попарном сличении списков. Вначале из эвристических отношений выбирается основной (старший) список. Чтения, отличающиеся от чтений основного списка, объявляются отклонениями (ошибочными). Чем больше ошибочных чтений содержит список, тем он генеалогически «дальше» от основного. В основе предложенной Фроже модели лежат три предположения: 1) при переписывании ошибки могут только добавляться; 2) одни и те же ошибки не могут содержаться в разных ветвях генеалогической стеммы; 3) каждый список может иметь только один протограф.
Применяя теоретико-множественный подход, Фроже приходит к поистине замечательным результатам: метод групп позволяет не только строить стемму из сохранившихся списков, но и восстанавливать утраченные звенья. Вершина полученной стеммы соответствует основному списку. При необходимости эту стемму можно совершенно «бесплатно» ориентировать относительно иного списка, выбранного в качестве основного. Для этого достаточно «потянуть» в стемме за данный список - все остальные списки заново распределятся друг относительно друга наподобие шарнирного механизма.
В 1970-х гг. данный метод был развит для классификации переводного древнерусского произведения «Закон Судный людем» (ЗСЛ) на материале М.Н. Тихомирова [7]. Ниже приведены два варианта получающейся генеалогической стеммы в зависимости от выбора основного списка.
Рис. 1
Стемма списков ЗСЛ, где в качестве основного выбрана Новгородская Кормчая, Синодальное Собрание, 132)
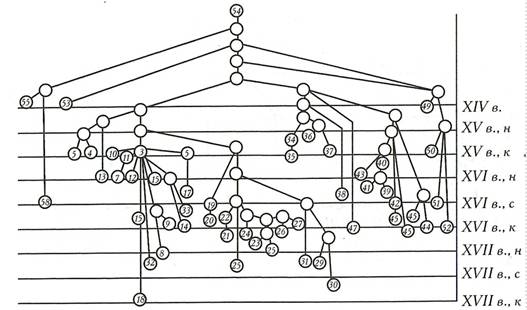
Рис. 2
Стемма списков ЗСЛ при выборе в качестве исходного списка протографа Устюжской Кормчей (Румянцевское собрание, 230)
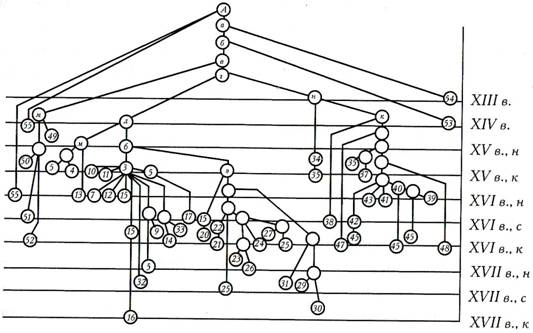
(Перечень списков ЗСЛ см. в Приложении 1)
Несмотря на поразительные результаты, данный метод, к сожалению, не лишен недостатков. Главный недостаток, с точки зрения автора настоящей статьи, заключается в очень жестких предположениях модели. Особенно третье предположение об одном протографе, что в условиях закрытой рукописной традиции выполнить не представляется возможным. Также остается повторить те же замечания, что и для кластерного подхода. При контаминации один и тот же список может нести черты нескольких протографов, принадлежащих порой разным группам. Хочется иметь в арсенале исследовательских средств механизм, учитывающий принадлежность списка различным группам с той или иной степенью надежности. Меняя параметр модели, можно менять степень размытости выявленных групп и, таким образом, степень детализированности получающейся стеммы. По мнению автора, все эти соображения органично укладываются в рамки теории нечетких множеств, предложенной в середине прошлого века американским ученым Лотфи Заде [8].
3. Элементы теории нечетких множеств
Данная теория является обобщением таких классических отраслей математического знания как теория множеств, математическая логика и др. Одним из важнейших понятий этой теории является нечеткое множество.
Данное множество представляет собой конечный набор пар объектов. Первый объект каждой пары – это элемент некоторого базового множества. Второй – это число, принимающее значение между нулем и единицей. Данное число ставится в соответствие первому объекту и носит название функции принадлежности. В терминах текстологии базовое множество это набор исследуемых списков (их текстов), а нечеткое множество – группы текстологически близких списков (редакции, изводы, виды). Тогда функция принадлежности нечеткого множества отражает степень уверенности, с которой можно соотнести список к соответствующей группе. Чем ближе к единице это значение, тем «типичнее» список для данной группы. Если это число занимает промежуточное положение между нулем и единицей, то достаточно достоверной представляется гипотеза о контаминации (правке по списку из другой группы). Наконец, при значении, близком к нулевому, можно констатировать, что рассматриваемый список не входит в данную группу.
Наряду с нечеткими множествами центральное место в нашем анализе будут играть нечеткие отношения. Нечеткое отношение является частным случаем нечеткого множества при условии, что рассматривается не пара, а тройка объектов. Первые два объекта каждой тройки – это пара элементов из базового множества, а третий объект – их функция принадлежности.
Нечеткое отношение удобно представлять как в виде матрицы, так и в виде ориентированного графа. Ниже приведен пример такого графа, узлами которого являются элементы из базового множества, а ориентированным (имеющим направление) дугам приписаны соответствующие значения функции принадлежности (взвешенные дуги).
Рис. 3
Пример графического и матричного представления бинарного нечеткого отношения
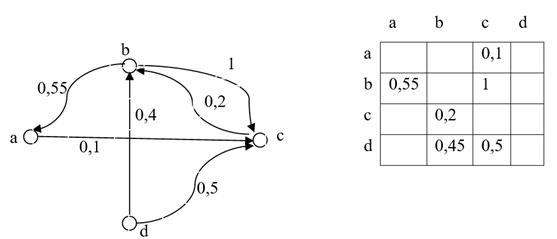
Примерами нечетких отношений являются «x приблизительно равно y», «x намного меньше чем y» на множестве чисел; «x похоже на y», «х не младше чем y» на множестве людей и т.д. В этом ключе можно так интерпретировать данные рисунка 3: b не младше с однозначно, а c не младше b с долей уверенности 20%. Формальные определения введенных понятий приведены в работе [9].
4. Метод нечеткой генеалогической классификации. Базовые принципы
В основе предлагаемой автором настоящей работы модели лежат два фундаментальных предположения относительно процесса копирования текстов списков [9]:
1) Чем больше ошибок (уклонений от нормы) перешло из одного текста в другой, тем достовернее гипотеза о том, что первый список генеалогически предшествует второму;
2) Чем меньше общих ошибок у пары списков, тем более независимы они друг от друга.
Таким образом, анализируются только ошибочные чтения. Здесь мы опираемся на классический принцип: «общность ошибок свидетельствует об общности происхождения» (К. Лахманн [10]). При этом возникают два вопроса: что считать ошибками и как оценивать их значимость? Под ошибочными чтениями мы будем понимать как собственно ошибки (пропуски фрагментов текста, описки, повторы), так и сознательное редактирование текста смысловой, идеологической, языковой и стилистической направленности. Оставляя пока в стороне ответ на второй вопрос, считаем, что каждое чтение типизировано и имеет свой вес. Опишем теперь процесс построения матрицы нечеткого отношения, играющей в нашем анализе ту же роль, что и матрица близости для кластерных методов.
5. Вычисление коэффициентов матрицы нечеткого отношения
Рассмотрим произвольную пару из имеющихся в наличии списков и выявим все их общие ошибки. Будем считать, что каждой ошибке приписан определенный вес. Вычислим сумму всех общих ошибок пары списков и разделим это число на сумму всех ошибок первого и второго списков. Полученные два числа интерпретируются как доля унаследованных ошибок из первого списка во второй и из второго в первый. Поскольку число ошибок в первом и во втором списке различно, то и получающиеся два числа (доли) также не равны друг другу. Составим из этих долей таблицу (матрицу нечеткого отношения). Не трудно видеть, что эта матрица не симметрична. На самом деле, это является не недостатком, а преимуществом данного подхода. Оказывается, используя аппарат нечетких множеств, из исходного отношения можно выделить два его типа: симметричное и антисимметричное [11]. Первый тип позволяет разбивать исходное базовое множество на семейство эквивалентных классов (схожих классов), а второй – устанавливать между ними частичный порядок (выделять генеалого-преемственные связи).
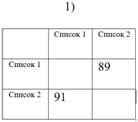
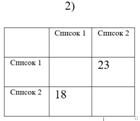
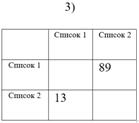
В зависимости от значений пары долей возможны три экстремальных случая (см. рис. 4):
1) Оба значения достаточно близки к единице (симметричность). Это значит, что почти все ошибки первого списка наследуются во второй, и, наоборот, все ошибки второго переходят в первый список. В текстологии такое возможно в двух случаях: либо списки переписывались слово в слово один из другого, либо оба принадлежат одной группе с общим протографом;
2) Оба значения достаточно близки к нулю (симметричность), списки не содержат общих ошибок. Отсюда можем заключить, что списки находятся в группах, не зависимых друг от друга (в разных ветвях стеммы);
3) Оба значения близки к разным концам отрезка от нуля до единицы (антисимметричность). Например, доля ошибок, унаследованных из первого во второй список близка к единице, а доля ошибок, унаследованных из второго в первый - к нулю. Другими словами, почти все ошибки первого списка перешли во второй, и лишь ничтожно малая часть ошибок второго перешла в первый. Такое возможно, если первый список генеалогически предшествует второму, является его протографом.
Рис. 4
Примеры симметричного и антисимметричного нечеткого отношения
6. Типологизация чтений
В процессе анализа 57 списков «Закона Судного людем» (на материале М.Н. Тихомирова + 3 добавленных) авторами настоящей работы было выделено 14 типов ошибочных чтений [12]: I - лексические замены; II - пропуски/ вставки глав; III - пропуск/ вставка предложений или их части; IV - пропуск/ вставка словосочетаний (не более 3 слов); V - пропуск/ вставка слов; VI - пропуск/ вставка частицы «не»; VII - смысловые ошибки; VIII - пропуск/ изменение названия главы; IX - перестановка слов/ нескольких слов; X – исправления; XI – орфография (в данный тип входят ранние правописные нормы и нормы т.н. 2-го южнославянского влияния); XII - описки, включая повторы; XIII – русизмы (в данный тип входят фонетические и морфологические русизмы) ; XIV - архаика (в данный тип входят нестяженные формы местоименных прилагательных и имперфекта, супин, двойственное число, склонение кратких (именных) прилагательных, старый сигматический аорист и т.п.).
Итак, мы видим, что в предложенной типологизации собраны типы чтений совершенно разной степени значимости для целей классификации. Интуитивно понятно, что лексические замены (I тип) или пропуски глав (II) оказывают гораздо большее влияние на группировку списков, чем орфография (XI) или описки (XII) (обратимые ошибки). Учитывать их значимость будем с помощью весовых коэффициентов (чисел от нуля до единицы). Самый простой способ – это прямое указание весов исходя из экспертной оценки. Такой подход возможен, но в то же время он обладает двумя существенными недостатками: 1) субъективность эксперта; 2) склонность эксперта размещать веса на целых делениях оценочной шкалы. Для максимального устранения второго недостатка автором настоящей работы было предложено использовать так называемый метод косвенной экспертизы (Т. Саати) [13].
7. Косвенный экспертный метод для оценки значимости типов чтений
Согласно данному подходу рассматриваем все возможные пары типов, и для каждой пары предлагаем эксперту оценить значимость одного типа относительно другого по девятибалльной шкале. Для упрощения каждому баллу ставится в соответствие качественная оценка на естественном языке типа «слабо значимее», «существенно значимее», «несравнимы» и т.д. Предполагается, что оценить один тип относительно другого гораздо проще, чем определить его значимость относительно совокупности всех остальных типов.
Полученное для каждой пары число заносится в квадратную таблицу, называемою матрицей попарных сравнений. Таким образом, на основе предложенной типологизации авторами настоящей статьи была построена качественная (и количественная) шкала степеней значимости типов разночтений для текстологической классификации [12]. Далее, используя формальную процедуру, на основе данной шкалы формируется искомый ряд весовых коэффициентов:
Таблица 1
Весовые коэффициенты для типов ошибочных разночтений (на основе «Закона Судного людем»)
|
Типы
|
I
|
II
|
III
|
IV
|
V
|
VI
|
VII
|
|
Веса
|
0,915
|
1
|
0,466
|
0,125
|
0,075
|
0,102
|
0,127
|
|
Типы
|
VIII
|
IX
|
X
|
XI
|
XII
|
XIII
|
XIV
|
|
Веса
|
0,204
|
0,08
|
0,05
|
0,07
|
0,048
|
0,102
|
0,171
|
Предложенный метод экспертной оценки играет ключевую роль для нечеткой классификации. Он позволяет определенным формальным образом оценить значимость того или иного разночтения в тексте. Подробное описание предложенного авторами косвенного метода приводится в работе [12]. Перейдем теперь к демонстрации работы метода нечеткой классификации на примере «Закона Судного людем».
8. Метод нечеткой генеалогической классификации. Предварительный этап
Целью предварительного этапа является построение матрицы нечеткого отношения (см. п.5). На вход метода подается файл с текстами рассматриваемых списков. Чтобы получить этот файл, необходимо провести большую и кропотливую работу по 1) выделению среди всех списков всех узлов разночтений; 2) представлению всех рассматриваемых текстов в виде последовательности узлов разночтений. В качестве таких узлов может выступать как слово, так и сочетание слов, перестановка слов или словосочетаний, пропуск/вставка. Степень детализации зависит от тех целей и задач, которые ставит перед собой исследователь. Можно, например, ограничиться выделением лишь характерных разночтений (примет). В случае ЗСЛ у автора настоящего доклада выделилось порядка 2000 узлов и 6700 разночтений (в силу большого объема материала авторы оставляют за собой право на некоторую корректировку получающейся матрицы нечеткого отношения и, соответственно, результатов проведенной классификации).
Рис. 5
Входной файл программы нечеткой классификации (фрагмент Новгородского списка (Нв))

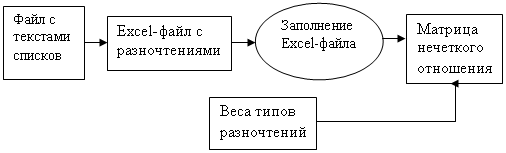
Результат работы программы по сличению списков выдается в отдельный Excel-файл.
Рис. 6
Таблица разночтений списков (фрагмент Excel-файла)
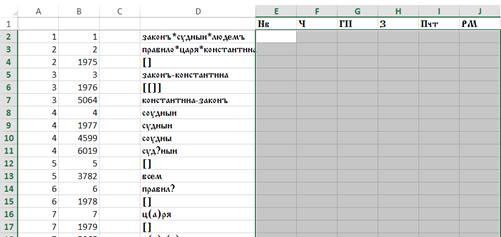
В столбце A указаны номера узлов разночтений, столбце B – номера разночтений (понятно, их может быть несколько для каждого узла), в столбце D приведены собственно чтения. Незаполненными остались столбец C – типы ошибок (см. п.6) и столбцы начиная с E – коды ошибок. Через знак «*» обозначается соединение слов в словосочетании, «[]» – пропуск словосочетания, «[[]]» – отсутствие перестановки, «?» – пропущенные редуцированные после выносной буквы. Заполнение этой таблицы - трудоемкая и ответственная часть работы эксперта. От его компетентной работы зависит – будет ли данное чтение включено в рассмотрение (признано ошибочным, см. п.4), и с каким весом оно будет входить в формулу расчета коэффициента (см. п.5). Ниже приведен фрагмент такого заполнения, выполненного автором настоящей статьи:
Рис. 7
Заполненная таблица разночтений списков (фрагмент Excel-файла)
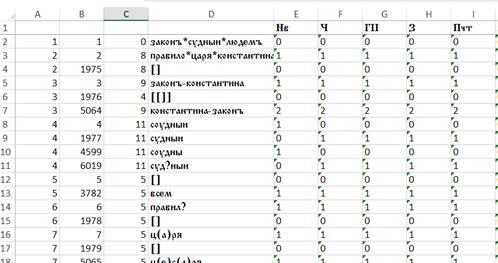
В столбцах начиная с E и заканчивая BI (всего 57 столбцов – по числу рассматриваемых списков) приводятся коды ошибок: нормальные чтения помечены нулем, ошибочные – натуральным числом от единицы и выше. Если чтения помечены одним и тем же числом (в одном столбце и в строках, соответствующих одному узлу), то с точки зрения программы они становятся неразличимы.
Работу эксперта можно на порядок упростить, если ограничиться заполнением лишь одного столбца с кодами ошибок. С ЗСЛ этого избежать, к сожалению, не удается. Данный памятник бытовал на протяжении столетий, книжные нормы также изменялись.
Таким образом, при анализе чтений нами вводится дополнительный разрез. При анализе очередного списка мы «встаем» на точку зрения его потенциального переписчика, жившего в определенный период времени и местности, работавшего в определенном скриптории. С учетом этих соображений в расчет формулы для коэффициентов (п. 5) вводятся необходимые корректировки.
Что касается ЗСЛ, то здесь была произведена некоторая оптимизация. С точки зрения книжной рукописной нормы было выделено четыре хронологических периода: 1) до 2ЮСЛ, до начала XV века; 2) период 2ЮСЛ, с начала XV века по середину XVI века; 3) с середины XVI века по середину XVII века (начало никоновских реформ); 4) с середины XVII века. Поскольку известно примерное время создания каждого списка, то каждый из них попадает в свою хронологическую группу. Таким образом, задача эксперта существенно упрощается: вместо 57 остается заполнить лишь четыре столбца и «растиражировать» их по своим группам. Заметим, что в течение указанных периодов менялись в основном орфографические нормы [14]. Поскольку тип XI входит с небольшим весовым коэффициентом (см. ч. 7) в формулу расчета матрицы, то можно предположить, что подобное хронологическое разбиение вряд ли приведет к большим ее изменениям.
Опять же, в случае неуверенности у эксперта всегда остается возможность не выделять чтение как ошибочное, поставить в соответствующей клетке ноль. Но необходимо помнить, что чем больше будет заполнена таблица, тем рельефнее и актуальнее получится итоговая картина.
Итак, работу программы на предварительном этапе можно представить в виде следующей схемы:
Рис. 8
Предварительный этап работы программы нечеткой классификации: схема
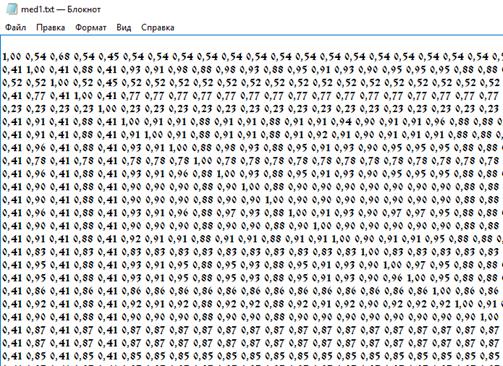
Ниже приведен фрагмент получившейся квадратной матрицы размером 57 X 57.
Рис. 9
Матрица нечеткого отношения для 57 списков ЗСЛ (фрагмент из Приложения 2)
9. Метод нечеткой классификации. Выделение классов эквивалентности
Подробное формализованное описание метода нечеткой генеалогической классификации приводится в работе [15]. Ниже остановимся на качественном описании его этапов.
Сначала необходимо построить классы нечеткой эквивалентности, которые в нашем анализе являются аналогами текстологически близких групп. Как указывалось в п.5, эти классы будут строиться на основе симметричного отношения. Для этого возьмем каждую пару элементов матрицы, расположенных симметрично относительно главной диагонали, выберем из них минимальное и присвоим его второму элементу (например, рассматривается один элемент из первой строки, второго столбца и второй – из второй строки, первого столбца). Формируем из этих элементов новую таблицу, которая уже будет матрицей симметричного отношения.
Рис. 10
Матрица симметричного отношения для списков ЗСЛ (фрагмент)

Каждому списку ЗСЛ соответствует своя строка этой матрицы (и такой же по порядку столбец, поскольку матрица теперь симметричная).
Пример 1. Например, Новгородскому списку соответствует первая строка (1,00 0,41 0,52 0,41 0,23 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,41 0,41 0,41 0,41 0,58 0,30 0,56 0,52 0,41); Чудовскому – вторая строка (0,41 1,00 0,41 0,77 0,23 0,91 0,91 0,96 0,78 0,96 0,90 0,88 0,95 0,90 0,91 0,83 0,95 0,95 0,86 0,88 0,88 0,87 0,87 0,85 0,87 0,87 0,85 0,78 0,78 0,79 0,79 0,83 0,86 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,30 0,41 0,41 0,82), Устюжскому – пятьдесят третья (0,58 0,41 0,52 0,41 0,23 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,41 0,41 0,41 0,41 1,00 0,30 0,56 0,52 0,41), и так далее. Другими словами, каждому списку поставим в соответствие нечеткое множество, функция принадлежности которого принимает значения из соответствующей строки. Тогда все эти числа можно интерпретировать следующим образом: множеству 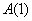 Новгородский список принадлежит со 100% уверенностью, Чудовский – с 41%; множеству Новгородский список принадлежит со 100% уверенностью, Чудовский – с 41%; множеству 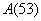 Новгородский список принадлежит с 58% и так далее. Новгородский список принадлежит с 58% и так далее.
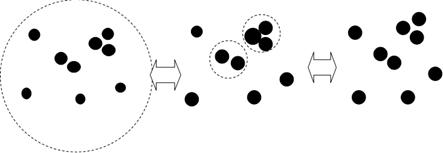
Теперь будем определять эквивалентные множества и объединять их в классы. Казалось бы, 58% - достаточно большой процент сходства, и оба множества и можно объединить в один класс. Оказывается, этого недостаточно. Значения функции принадлежности пары множеств должны быть синхронизированы и для всех остальных элементов. Это положение удобно раскрыть в терминах гистограмм. А именно представим каждое из нечетких множеств в виде набора «столбиков», высота которых равна соответствующему значению функции принадлежности. Тогда если столбики обоих множеств «растут» или «падают» одновременно, то такие множества являются эквивалентными. При этом они совершенно не обязаны принимать одинаковые значения – важна только их динамика. Более точно, если значение первой функции принадлежности больше какого-то высокого порога, то и значение второй также должно быть не ниже его. И, наоборот, если значение первой функции ниже какого-то малого порога, то и значение второй также должно быть мало.
Пример 2. Возвращаясь к примеру 1, видим, что нечеткие множества Новгородского и Устюжского списков ведут себя «симметрично» на всех элементах, начиная с первого: 1,00 против 0,58; 0,41 против 0,41; 0,52 против 0,52 и так далее. Подобного вывода нельзя сделать для Новгородского и Чудовского. Здесь картина «ломается» уже на первых элементах: 1,00 против 0,41; 0,41 против 1,00. Таким образом, можно сделать вывод, что вплоть до уровня 58% классы , продолжают оставаться эквивалентными. В то же время, классы ,  с 41% перестают быть эквивалентными. с 41% перестают быть эквивалентными.
Итак, задаваясь определенным уровнем надежности, мы всегда можем определить – эквивалентны ли класс и нечеткое множество или нет. В первом случае множество включается в существующий класс. Во втором – формирует новый класс эквивалентности. Повторяя эту процедуру для всех списков, получаем разбиение исходного множества  на семейство на семейство  непересекающихся классов эквивалентности. Иными словами, все множество списков мы разбили на непересекающиеся текстологически близкие группы. непересекающихся классов эквивалентности. Иными словами, все множество списков мы разбили на непересекающиеся текстологически близкие группы.
Понятно, что чем ниже этот уровень, тем больше шансов у множеств объединиться в один класс. И, наоборот, чем выше зададим такой порог, тем на большее число классов распадается наше исходное множество. В крайнем случае каждый класс будет соответствовать одному списку. Таким образом, мы на качественном уровне показали как порог надежности (а это входной параметр метода) регулирует степень детализации получающейся стеммы.
Рис. 11
Выделение классов эквивалентности с ростом порога надежности
10. Метод нечеткой классификации. Упорядочивание
Устанавливать генеалого-преемственные связи между классами нечеткой эквивалентности будем в несколько подэтапов.
Выбор эталонных списков. Для каждого получившегося класса эквивалентности в качестве эталона может быть выбран произвольный список, нечеткое множество которого включено в данный класс.
Установление частичного порядка между эталонами. На семействе классов построим новое нечеткое отношение следующим образом: строки и столбцы матрицы соответствуют эталонным спискам, а на их пересечении стоит соответствующее значение функции принадлежности исходного отношения (см. рис. 9). Можно строго доказать, что построенное отношение является антисимметричным в том смысле, что дуги любых пар узлов не могут иметь значения, одновременно больше порогового [9] (см. граф на рис.3). Итак, вместо стеммы классов мы фактически строим стемму эталонов.
Нахождение максимально связанных подмножеств эталонов. Граф назовем связным если любая пара его вершин соединена хотя бы одной дугой с весом, большим порогового. Возвращаясь к примеру графа на рис.3, не трудно видеть, что при величине порога 0,5 множество его вершин распадается на три связных подмножества: a и b, b и c, d (выделены цветом).
Рис. 12
Связные подмножества графа из рис. 3 (при пороге 50%)
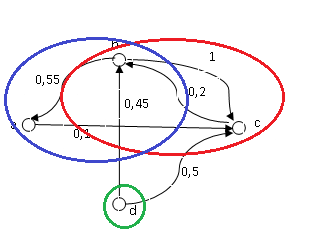
Как мы видим, вершина b является общей для двух подмножеств. Каждое из связных подмножеств соответствует своей ветви на графе.
Линейное упорядочивание связных подмножеств. Каждому связному множеству соответствует своя ветвь стеммы. Зададимся порогом надежности и упорядочим хронологически все узлы на этой ветви. Другими словами, в каждой паре соседних узлов один из них выступает протографом, а другой – его непосредственным потомком. Можно показать, что в нашем случае (антисимметричное отношение) такая процедура упорядочивания существует и является корректной (см. работу [9]). Ниже приведен результат работы такой процедуры для подмножеств из рис.12.
Рис. 13
Граф нечеткого отношения из рис. 12 (при пороге 50%)
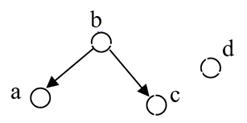
На основе изложенного алгоритма автором настоящей статьи на языке Delphi 2012 была разработана программа нечеткой генеалогической классификации.
11. Классификация ЗСЛ: историография вопроса
Классификация списков ЗСЛ ведет свое происхождение от классификации Русской Правды, встречающегося с ЗСЛ в одних и тех же сборниках (Кормчие Книги, Мерила Праведные). В настоящее время большинством текстологов используется классификация М.Н. Тихомирова [16], которая, в свою очередь, восходит в целом к классификации В.П. Любимова [17]. Попытки классифицировать это древнерусское произведение делались и раньше (Э. Тобин, Н.В. Калачев, В.И. Сергеевич, С.В. Юшков), но именно Любимов подошел к данной задаче не только с точки зрения текстологии, но и анализа словарного состава списков. Классификации Любимова мы и будем придерживаться в нашей работе. Отметим, что в настоящее время Корогодиной М.В. предложена новая классификация списков Кормчих, основывающаяся на текстологическом анализе их состава [18].
Любимов делит все имеющиеся списки (а их у него более ста) на виды. Списки, содержащие ЗСЛ, входят в Троицкий, Новгородско-Софийский, Розенкампфовский и Ферапонтовский виды. Отдельно находится древнейший Новгородский (Синодальный) список. Позже, при анализе уже ЗСЛ, Тихомиров включит Новгородский список наряду с Устюжским, Варсонофьевским и Иосафовским списками в Древнейшую редакцию [16]. Любимов отмечает близость Новгородско-Софийского вида к Новгородскому списку, вторичность Ферапонтовского вида по отношению к Розенкампфовскому. Новгородско-Софийский вид разделяется ученым на две ветви: собственно Новгородско-Софийскую с близким к нему Румянцевским списком и Вязниковскую.
Выводы Тихомирова относительно классификации Русской Правды частично разошлись с выводами Любимова. Так, в отличие от Любимова, Тихомиров считает, что списки Ферапонтовского вида правились не по Новгородско-Софийскому, а по Троицкому виду. В качестве основного для Розенкампфовского вида Тихомиров признает не Розенкампфовский список, а Чудовский, из-за чего данный вид принимает у него наименование Чудовского извода. Еще до выделения Ферпонтовского, Чудовской извод разделялся на две ветви: первую – Чудовский, Розенкампфовский и другие списки, вторую – Крестининский и другие списки. При этом ученый отмечал влияние Крестининского на Чудовский список. Позже, анализируя уже исключительно ЗСЛ, Тихомиров объединяет Чудовский и Ферапонтовский изводы в одну редакцию – Чудовскую. Наиболее древними Тихомиров считает списки Новгородский и Троицкого извода, независимо восходящие к общему протографу. Выводы ученых сведены в виде отдельных тезисов в таблицу.
Заметим, что все вышеозначенные выводы делались относительно Русской Правды - произведения, имеющего иной генезис чем Закон Судный людем (древнерусский против переводного древнеславянского) [19]. Поскольку традиционный текстологический анализ ЗСЛ не проводился, то приходится подключать к изучению результаты, полученные текстологами для Русской Правды. Результаты применения Миловым и Бородкиным метода групп к ЗСЛ [7] в основном подтвердили выводы Тихомирова по Русской Правде. Все же вопрос о древнейших списках ЗСЛ остается открытым. На основании эвристических соображений в качестве такого основного Миловым было предложено считать Устюжский.
Выводы относительно классификации списков, содержащих ЗСЛ, сведены в таблицу 2 в виде тезисов. Знаком «+» отмечаются разделяемые учеными тезисы, знаком «-» – оспариваемые. Для оценки правильности тезисов в таб.6 предусмотрена дополнительная градация: «+-» – «скорее да, чем нет «; «-+» – «скорее нет, чем да». Через «?» обозначаются тезисы, оставленные авторами без внимания. В этой же таблице учтены результаты, получающиеся при применении метода нечеткой классификации с различным выбором порога надежности (см. п.9). В крайнем столбце указана ссылка на соответствующий скриншот экрана со стеммой.
Таблица 2
Классификация списков Русской Правды и Закона Судного людем согласно Любимову В.П., Тихомирову М.Н., результатам применения метода групп (Милов Л.В. и Бородкин Л.И.) и нечеткой генеалогической классификации
|
nn
|
Тезис
|
Любимов РП
|
Тихомиров РП
|
Милов-Бородкин ЗСЛ
|
Нечеткая классиф. ЗСЛ
|
Ссылка на рисунок
|
|
1
|
Почти одновременное возникновение двух сборников – Новгородской Кормчей и Мерила Праведного
|
?
|
+
|
?
|
+-
|
16
|
|
2
|
Троицкий I – наиболее древний и исправный список из Мерил праведных
|
+
|
+
|
+
|
+
|
16
|
|
3
|
Тексты Русской Правды и ЗСЛ в рукописях Мерила Праведного однородны и, по-видимому, восходят к одному общему источнику
|
+
|
+
|
+
|
+
|
14, 15, 16
|
|
4
|
Независимое происхождение Синодального и Троицкого списков исходя из сравнения некоторых их заголовков и чтений. Эти списки близки и ведут свое происхождение от общего источника. Черты этого протографа во многих случаях точнее отразились в Троицком списке, чем в Синодальном.
|
?
|
+
|
?
|
+-
|
16
|
|
5
|
Синодальный II, Синодальный III, Кирилло-Белозерский III произошли, по-видимому, не от Троицкого списка, а от общего с ним протографа
|
+
|
+
|
+
|
+-
|
16
|
|
6
|
Указание на основании некоторых общих чтений на древнее происхождение списков Синодального, Новгородско-Софийского видов и списков Мерил Праведных
|
+
|
+
|
+
|
+
|
14, 16, 17
|
|
7
|
Близость списков Синодального, Новгородско-Софийского видов и списков Мерил Праведных
|
+
|
+
|
+
|
+-
|
16, 17
|
|
8
|
Разделение Новгородско-Софийского вида на две ветви: Новгородско-Софийскую и Вязниковскую
|
+
|
?
|
+
|
-+
|
17, 18
|
|
9
|
Совпадение Новгородско-Софийского и Румянцевского I списков Новгородско-Софийского вида
|
+
|
+
|
+
|
+
|
17, 18
|
|
10
|
Вязниковская ветвь с более поздними разночтениями и чертами языка чем Новгородско-Софийская ветвь Новгородско-Софийского вида
|
+
|
+
|
+
|
+
|
17, 18
|
|
11
|
Вязниковский – древнейший список Вязниковской ветви
|
+
|
?
|
-
|
-+
|
17, 18
|
|
12
|
Прилуцкий – важный список Вязниковской ветви
|
+
|
?
|
+
|
+
|
18
|
|
13
|
Близость к Вязниковскому Ярославского и Прилуцкого списков Вязниковской ветви
|
+
|
+
|
-
|
+
|
18, 17
|
|
14
|
Фроловский-Браиловский стоит в ближайшей связи с Соловецким III
|
+
|
+
|
+
|
-
|
19
|
|
15
|
Прилуцкий – заглавный список Вязниковской ветви Новгородско-Софийского вида
|
-
|
-
|
+
|
+
|
18
|
|
16
|
Выделение Розенкампфовского (Чудовского) вида как отдельного в составе Кормчих в соединении с Мерилом Праведным
|
+
|
+
|
+
|
+
|
19
|
|
17
|
Розенкампфовский – основной список Розенкампфовского вида
|
+
|
-
|
-
|
-
|
19
|
|
18
|
Розенкамфовский вид стоит в общем дальше Троицкого вида, чем списки Синодальный I и Новгородско-Софийского вида
|
+
|
+
|
+
|
+
|
17, 14
|
|
19
|
Чудовский - основной список Розенкамфского вида
|
-
|
+
|
+
|
+
|
19
|
|
20
|
Ряд особенностей Розенкампфовского вида указывает на его происхождение от протографа Троицкого извода
|
?
|
+
|
?
|
-
|
19
|
|
21
|
Списки Розенкампфовского вида делятся на две ветви: Чудовский с близким к нему Розенкамфскому и др. и Крестининский с иной группой списков
|
?
|
+
|
-
|
+-
|
19
|
|
22
|
Текст Чудовского списка принадлежит к первой ветви Чудовского извода, но правлен по тексту второй (Крестининский) и еще по другому источнику
|
?
|
+
|
+-
|
+
|
19
|
|
23
|
Списки Розенкампфовского вида делятся на две ветви: Чудовский с 14 списками и 3 списка (Розенкамфский, Троицкий V и Антониево-Сийский)
|
-
|
-
|
+
|
-
|
19
|
|
24
|
Хлудовский и Никифоровский списки включены в Розенкампфский вид
|
-
|
-
|
+
|
+-
|
19
|
|
25
|
Погодинский III стоит в ближайшей связи с Погодинским II, повторяя его ошибки
|
+
|
+
|
+
|
+
|
19
|
|
26
|
Соловецкий II и Овчинниковский I как исходный его предшественник (двойное звено)
|
?
|
?
|
+
|
-
|
19
|
|
27
|
Архивский II и Чудовский как исходный его предшественник (двойное звено)
|
?
|
?
|
+
|
-
|
19
|
|
28
|
Троицкий III и Чудовский как исходный его предшественник (двойное звено)
|
?
|
?
|
+
|
+
|
19
|
|
29
|
Чудовский – Музейский I – Забелинский (тройное звено)
|
?
|
?
|
+
|
+-
|
19
|
|
30
|
Чудовский – список Публичной библиотеки – Возмицкий (тройное звено)
|
?
|
?
|
+
|
+-
|
19
|
|
31
|
Выделение Ферапонтовского как отдельного вида в составе Кормчих в соединении с Мерилом Праведным
|
+
|
+
|
+
|
+
|
19
|
|
32
|
Ферапонтовский вид – производный от Розенкампфовского вида
|
+
|
+
|
+
|
-
|
19
|
|
33
|
Ферапонтовский – основной список Ферапонтовского вида
|
+
|
+
|
+
|
+
|
19
|
|
34
|
Ферапонтовский вид - результат взаимодействия Кормчих Новгородско-Софийского и Розенкампфовского видов
|
+
|
-
|
-
|
-
|
19
|
|
35
|
Никифоровский – особый список Ферапонтовского вида, писец которого продолжил работу этого вида, присоединив еще ряд черт из Новгородско-Софийского вида
|
+
|
?
|
-
|
-+
|
19
|
|
37
|
Толстовский II и Ферапонтовский как его исходный предшественник (двойное звено)
|
?
|
?
|
+
|
+-
|
19
|
|
38
|
Кирилло-Белозерский I и Кирилло-Белозерский II тесно связаны
|
+
|
+
|
+
|
+
|
19
|
|
39
|
Фроловский I и Соловецкий IV как его исходный предшественник (двойное звено)
|
?
|
?
|
+
|
+-
|
19
|
12. Классификация ЗСЛ согласно методу нечеткой классификации: результаты
Проверим с точки зрения нечеткой классификации некоторые тезисы из таблицы 2. Указанные в кружках стеммы цифры означают количество списков, попавших в соответствующий нечеткий класс.
Рис. 14
Выделение редакций Древнейшей, Троицкой, Новгородско-Софийской, Чудовской
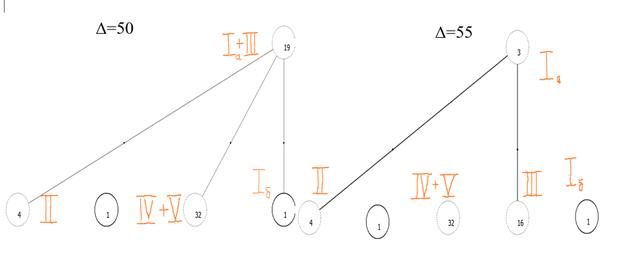
Iа – Нв У Врс;Iб – Ио; II - Тр СII КБIII СIII ; III - ГII С Р ВЧ Я ПМ СМIII АД Е Ц ОII ХБ ТБIII ЕII ФБ ; IV+V - Ч З РМ ТV ПБ СМII ТII ЦII КР О АНII АС И ТIII ИМ ВМ ФМ ТБII Ф СМIV ЕIV АДII РII РЛII КБ КБII ПII ПIII ЦIII Х Н Прм ;
Как следует из рис.14, при уровне надежности 50 % из общего массива выделяются три группы близкородственных списков ЗСЛ. Первая группа состоит из списков Древнейшей и Новгородско-Софийской редакций (19 списков). Вторая – из четырех списков Троицкой редакции. Наконец, третья состоит из 32 списков еще не размежевавшихся Розенкапфовского и Ферапонтовского видов (Чудовская редакция). Причем выявляется первичность первой группы относительно двух остальных. При увеличении порога надежности (55%) первая группа распадается на первичную Древнейшую (3 списка – Новгородский, Варсонофьевский и Устюжский) и вторичную Новгородско-Софийскую редакцию (16 списков).
Рис. 15
Соотношение списков внутри Древнейшей редакции (Δ=59)

Вызывает интерес взаимоотношение списков внутри Древнейшей редакции. Если обратиться к соответствующим данным матрицы нечеткого отношения (см. таб. 3), то первичность протографа Устюжского списка не вызывает возражений, что нельзя сказать о Варсонофьевском: процент унаследованных ошибок из протографа Варсонофьевского списка в протограф Новгородского составляет 60%, а из протографа Новгородского в протограф Варсонофьевского – 56%. Таким образом, первичность протографа Варсонофьевского списка обеспечивается с минимальным разрывом.
Таб. 3
Фрагмент матрицы нечеткого соотношения для ЗСЛ
|
|
Нв
|
У
|
Врс
|
|
Нв
|
|
0,58
|
0,56
|
|
У
|
0,67
|
|
0,56
|
|
Врс
|
0,60
|
0,58
|
|
Для Варсонофьевского списка также отметим связь его протографа с Троицким видом, пропадающую при пороге 71% (см. рис. 16). Также на основе этого рисунка можно наметить близость списков КБIII, СIII, имеющих общий протограф.
Рис. 16
Соотношение списков внутри Троицкого вида

IIб – КБIII, СIII, СII
На следующем рисунке отражена связь Новгородско-Софийского вида с протографом Новгородского списка. Также среди этого вида выделяется группа первичных списков (протографа Софийского, Румянцевского, Вязниковского, Ярославского и Прилуцкого).
Рис. 17
Соотношение списков внутри Новгородско-Софийского вида. I часть
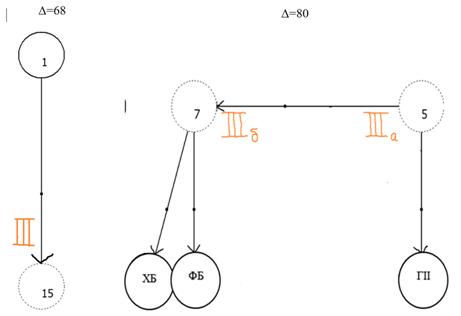
IIIб – СМIII, АД, Е, Ц, ОII, ТБIII, ЕII ; IIIа – C, Р, Вч, Я, ПМ
С увеличением порога происходит дальнейшее дробление этого извода, в том числе уточняется взаимоотношения среди протографов пяти первичных списков. Из них Софийский и Румянцевский образуют отдельную группу и влияют наряду с протографом Прилуцкого списка на группу, состоящую из Вязниковского и Ярославского списков. первичными оказываются протографы Софийского, Румянцевского списка, а также протограф Прилуцкого (см. рис.18).
Рис. 18
Соотношение списков внутри Новгородско-Софийского вида. II часть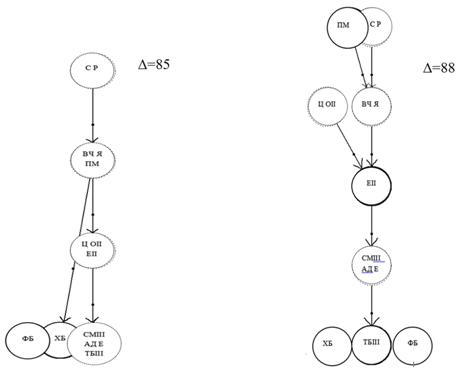
Списки Чудовской редакции демонстрируют наибольшую однородность, разделяясь в целом на две ветви (Розенкапфовская выделена красным, Ферапонтовская - зеленым цветом) лишь с порога 90%.
Рис. 19
Соотношение списков внутри Чудовской редакции (Δ=90)
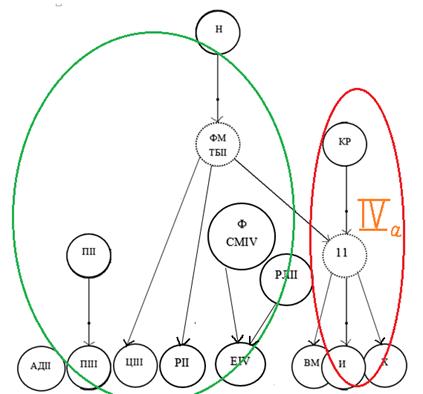
IVа -Ч РМ ТV ПБ ТII ЦII О АНII АС ТIII ИМ
Как следует из рис. 19, внутри Ферапонтовского вида выделяются группы родственных списков. Одна группа состоит из Погодинского II и Погодинского III списков. Другая – из Фроловского I, Соловецкого IV, Егоровского IV, Рогожского II списка. Наконец, третья группа состоит из одного списка - Никифоровского.
Что касается Ферапонтовского списка, то, как следует из рис. 19, его протограф занимает промежуточное положение между протографами Ферапонтовского и Розенкампфовского видов (предшествует протографам Розенкампфовского вида). Но если обратиться к данным матрицы нечеткого отношения, то это предшествование является минимальным (92% против 88%).
Списки Розенкапфовского вида довольно однородны, выделяясь из единой группы лишь при величине порога 92%. Из рис. 19 видно, что протограф Крестининского списка влияет на остальные списки Розенкапфовского вида. Пермский список (ПРМ) не показан на рис.19, поскольку выделяется из единой группы уже при уровне порога 83%. Схожая ситуация происходит и с списком Макариева Унженского монастыря (КСТ) из Новгородско-Софийской редакции. Это можно объяснить тем, что при вводе обоих списков в программу нечеткой классификации использовались не материалы Тихомирова, а непосредственно оригиналы текстов.
Выводы
Результаты нечеткой классификации в целом не противоречат как результатам традиционного анализа, так и результатам применения метода групп. Так, выделяются одни и те же редакции; между ними устанавливаются схожие генеалого-преемственные связи (например, первичность Древнейшей и Троицкой редакций по сравнению с Новгородско-Софийской и Чудовской редакциями; первичность Новгородско-Софийской относительно Вязниковской ветви внутри Новгородско-Софийской редакции). Подчеркнем еще раз, что в отличие от остальных подходов метод нечеткой классификации может выдавать стемму с разной степенью детализации. Проведенное исследование указывает на древность протографа Устюжского списка внутри Древнейшей редакции, подтверждает близость Новгородско-Софийской редакции и протографа Новгородского списка. Определено влияние Крестининского списка на Розенкампфовскую ветвь, что подтверждает наблюдения Тихомирова. Наоборот, Хлудовский список, также как и у Милова-Бородкина, размещается в Розенкампфовской ветви, что не совпадает с выводами Любимова и Тихомирова. Также нечеткая классификация иначе определяет взаимоотношение списков Розенкампфовского и Ферапонтовского видов: в отличие от выводов остальных ученых не подтверждается производность второго вида относительно первого. Для проверки и уточнения этих выводов требуется дополнительное исследование, в частности, сравнение текстов по отдельным разночтениям, привлечение к анализу программой оригиналов списков.
В заключение авторы выражают глубокую признательность профессору МГУ им. М.В. Ломоносова Л.И. Бородкину, ведущему научному сотруднику Института российской истории РАН Беляковой Е.В. за внимание и плодотворное обсуждение в процессе написания настоящей работы, а также сотрудникам Государственного архива Костромской области за помощь в отыскании необходимой рукописи.
Приложение 1
Перечень списков Закона Судного людем
|
nn
|
Список
|
Датировка
|
Шифр
|
|
Чудовский и Ферапонтовский виды
|
|
3
|
Чудовский
|
1499 г.
|
Ч
|
|
4
|
Розенкампфовский
|
конец XV века
|
РМ
|
|
5
|
Троицкий V
|
конец XVI века
|
ТV
|
|
6
|
Список Публичной библиотеки им. М.Е. Салтыкова-Щедрина
|
конец XV века
|
ПБ
|
|
7
|
Соловецкий II
|
начало XVI века
|
СМII
|
|
8
|
Троицкий II
|
начало XVI века
|
ТII
|
|
9
|
Царского II список
|
вторая половина XVI века
|
ЦII
|
|
10
|
Крестининский
|
конец XV века
|
КР
|
|
11
|
Овчинниковский I
|
конец XV века
|
О
|
|
12
|
Академический II
|
начало XVI века
|
АНII
|
|
13
|
Антониево-Сийский
|
начало XIV века
|
АС
|
|
14
|
Ионовский
|
конец XIV века
|
И
|
|
15
|
Троицкий III
|
начало XVI века
|
ТIII
|
|
16
|
Музейский I
|
вторая половина XVI века
|
ИМ
|
|
17
|
Возмицкий
|
1533 г.
|
ВМ
|
|
18
|
Забелинский
|
конец XVII века
|
З
|
|
19
|
Ферапонтовский
|
середина XVI века
|
ФМ
|
|
20
|
Толстовский II
|
вторая половина XVI века
|
ТБII
|
|
21
|
Фроловский I
|
конец XVI века
|
Ф
|
|
22
|
Соловецкий IV
|
вторая половина XVI века
|
СМIV
|
|
23
|
Егоровский IV
|
конец XVI века – начало XVII века
|
ЕIV
|
|
24
|
Архивский II
|
конец XVI века
|
АДII
|
|
25
|
Румянцевский II (Никоновский)
|
1620 г.
|
РII
|
|
26
|
Рогожский II
|
начало XVII века
|
РЛII
|
|
27
|
Кирилло-Белозерский I
|
вторая половина XVI века
|
КБ
|
|
28
|
Кирилло-Белозерский II
|
1590 г.
|
КБII
|
|
29
|
Погодинский II
|
первая половина XVII века
|
ПII
|
|
30
|
Погодинский III
|
вторая половина XVII века
|
ПIII
|
|
31
|
Царского III список
|
первая половина XVII века
|
ЦIII
|
|
32
|
Хлудовский
|
первая половина XVII века
|
Х
|
|
33
|
Никифоровский
|
вторая половина XVII века
|
Н
|
|
57
|
Пермский
|
вторая половина XV века
|
ПРМ
|
|
Новгородско-Софийский вид
|
|
34
|
Новгородско-Софийский
|
1470-1490 гг.
|
C
|
|
35
|
Румянцевский
|
конец XV века
|
Р
|
|
36
|
Вязниковский
|
вторая половина XV века
|
ВЧ
|
|
37
|
Ярославский
|
конец XV века
|
Я
|
|
38
|
Прилуцкий
|
1534 г.
|
ПМ
|
|
39
|
Соловецкий III
|
1519 г.
|
СМIII
|
|
40
|
Архивский I
|
конец XV века – начало XVI века
|
АД
|
|
41
|
Егоровский I
|
начало XVI века
|
Е
|
|
42
|
Царского I список
|
середина XVI века
|
Ц
|
|
43
|
Овчинниковский II
|
1518 г.
|
ОII
|
|
44
|
Хворостининский
|
конец XVI века
|
ХБ
|
|
45
|
Толстовский III
|
конец XVI века
|
ТБIII
|
|
46
|
Егоровский II
|
вторая половина XVI века
|
ЕII
|
|
47
|
Годуновский II
|
конец XVI века
|
ГII
|
|
48
|
Фроловско-Браиловский
|
вторая половина XV века
|
ФБ
|
|
58
|
Макариева Унженского монастыря список
|
1560-е гг.
|
КСТ
|
|
Троицкий вид (Мерила Праведного)
|
|
49
|
Троицкий
|
XIV век
|
Тр
|
|
50
|
Синодальный II
|
1467-1481 гг.
|
СII
|
|
51
|
Кирилло-Белозерский
|
середина XVI века
|
КБIII
|
|
52
|
Синодальный III
|
1587 г.
|
СIII
|
|
Древнейшая редакция
|
|
53
|
Варсонофьевский
|
XIV век
|
ВРС
|
|
54
|
Новгородский
|
1280 г.
|
НВ
|
|
55
|
Устюжский
|
XIV век
|
У
|
|
56
|
Иосафовский
|
XVI век
|
ИО
|
|
|
|
59
|
Печатной Кормчей список
|
1649-1653 гг.
|
ПЧТ
|
Приложение 2
Нормализованная матрица нечеткого отношения предпочтения (приведена построчно, нумерация согласно порядку списков во входном файле)
1 (Нв): 1,00 0,54 0,68 0,54 0,45 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,68 0,59 0,59 0,59 0,59 0,58 0,50 0,56 0,61 0,54
2 (Ч): 0,41 1,00 0,41 0,88 0,41 0,93 0,91 0,98 0,88 0,98 0,93 0,88 0,95 0,91 0,93 0,90 0,95 0,95 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
3 (ГII): 0,52 0,52 1,00 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
4 (З): 0,41 0,77 0,41 1,00 0,41 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,77 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,77
5 (Пчт): 0,23 0,23 0,23 0,23 1,00 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23 0,23
6 (РМ): 0,41 0,91 0,41 0,88 0,41 1,00 0,91 0,91 0,88 0,91 0,91 0,88 0,91 0,91 0,94 0,90 0,91 0,91 0,96 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,91 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
7 (ТV): 0,41 0,91 0,41 0,88 0,41 0,91 1,00 0,91 0,88 0,91 0,91 0,88 0,91 0,92 0,91 0,90 0,91 0,91 0,91 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,91 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
8 (ПБ): 0,41 0,96 0,41 0,88 0,41 0,93 0,91 1,00 0,88 0,98 0,93 0,88 0,95 0,91 0,93 0,90 0,95 0,95 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
9 (СМII): 0,41 0,78 0,41 0,78 0,41 0,78 0,78 0,78 1,00 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,78
10 (ТII): 0,41 0,96 0,41 0,88 0,41 0,93 0,91 0,96 0,88 1,00 0,93 0,88 0,95 0,91 0,93 0,90 0,95 0,95 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
11 (ЦII): 0,41 0,90 0,41 0,88 0,41 0,90 0,90 0,90 0,88 0,90 1,00 0,88 0,90 0,90 0,90 0,90 0,90 0,90 0,90 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,90 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
12 (КР): 0,41 0,90 0,41 0,88 0,41 0,90 0,90 0,90 0,88 0,90 0,90 1,00 0,90 0,90 0,90 0,90 0,90 0,90 0,90 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,90 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
13 (О): 0,41 0,96 0,41 0,88 0,41 0,93 0,91 0,96 0,88 0,97 0,93 0,88 1,00 0,91 0,93 0,90 0,97 0,97 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
14 (АНII): 0,41 0,90 0,41 0,88 0,41 0,90 0,90 0,90 0,88 0,90 0,90 0,88 0,90 1,00 0,90 0,90 0,90 0,90 0,90 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,91 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
15 (АС): 0,41 0,91 0,41 0,88 0,41 0,92 0,91 0,91 0,88 0,91 0,91 0,88 0,91 0,91 1,00 0,90 0,91 0,91 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,91 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
16 (И): 0,41 0,83 0,41 0,83 0,41 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 1,00 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
17 (ТIII): 0,41 0,95 0,41 0,88 0,41 0,93 0,91 0,95 0,88 0,95 0,93 0,88 0,95 0,91 0,93 0,90 1,00 0,97 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
18 (ИМ): 0,41 0,95 0,41 0,88 0,41 0,93 0,91 0,95 0,88 0,95 0,93 0,88 0,95 0,91 0,93 0,90 0,96 1,00 0,95 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,88 0,87 0,87 0,88 0,93 0,88 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
19 (ВМ): 0,41 0,86 0,41 0,86 0,41 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 1,00 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
20 (ФМ): 0,41 0,92 0,41 0,88 0,41 0,92 0,91 0,92 0,88 0,92 0,92 0,88 0,92 0,91 0,92 0,90 0,92 0,92 0,92 1,00 0,91 0,92 0,92 0,90 0,89 0,93 0,89 0,89 0,89 0,87 0,87 0,90 0,93 0,89 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
21 (ТБII): 0,41 0,90 0,41 0,88 0,41 0,90 0,90 0,90 0,88 0,90 0,90 0,88 0,90 0,90 0,90 0,90 0,90 0,90 0,90 0,90 1,00 0,92 0,92 0,90 0,89 0,90 0,89 0,89 0,89 0,87 0,87 0,90 0,90 0,89 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
22 (Ф): 0,41 0,87 0,41 0,87 0,41 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 1,00 0,96 0,90 0,87 0,88 0,89 0,89 0,89 0,87 0,87 0,87 0,87 0,87 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
23 (СМIV): 0,41 0,87 0,41 0,87 0,41 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,96 1,00 0,90 0,87 0,88 0,89 0,89 0,89 0,87 0,87 0,87 0,87 0,87 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
24 (ЕIV): 0,41 0,85 0,41 0,85 0,41 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 1,00 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
25 (АДII): 0,41 0,87 0,41 0,87 0,41 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,88 1,00 0,87 0,88 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
26 (РII): 0,41 0,87 0,41 0,87 0,41 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,87 0,88 0,88 0,88 0,87 1,00 0,88 0,88 0,88 0,87 0,87 0,87 0,87 0,87 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
27 (РЛII): 0,41 0,85 0,41 0,85 0,41 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,91 0,85 0,85 1,00 0,85 0,85 0,85 0,85 0,85 0,85 0,85 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
28 (КБ): 0,41 0,78 0,41 0,78 0,41 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 1,00 0,95 0,78 0,78 0,78 0,78 0,78 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,78
29 (КБII): 0,41 0,78 0,41 0,78 0,41 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,78 0,93 1,00 0,78 0,78 0,78 0,78 0,78 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,78
30 (ПII): 0,41 0,79 0,41 0,79 0,41 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 1,00 0,91 0,79 0,79 0,79 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,79
31 (ПIII): 0,41 0,79 0,41 0,79 0,41 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 0,79 1,00 0,79 0,79 0,79 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,79
32 (ЦIII): 0,41 0,83 0,41 0,83 0,41 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 0,83 1,00 0,83 0,83 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
33 (Х): 0,41 0,86 0,41 0,86 0,41 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 0,86 1,00 0,86 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
34 (Н): 0,41 0,92 0,41 0,88 0,41 0,92 0,92 0,92 0,88 0,92 0,92 0,88 0,92 0,92 0,92 0,94 0,92 0,92 0,92 0,90 0,90 0,90 0,90 0,90 0,89 0,90 0,89 0,89 0,89 0,87 0,87 0,90 0,94 1,00 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 0,82
35 (С): 0,52 0,52 0,83 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 1,00 0,98 0,93 0,93 0,87 0,88 0,88 0,88 0,87 0,87 0,85 0,88 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
36 (Р): 0,52 0,52 0,83 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,95 1,00 0,93 0,93 0,87 0,88 0,88 0,88 0,87 0,87 0,85 0,88 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
37 (ВЧ): 0,52 0,52 0,83 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,84 0,84 1,00 0,99 0,87 0,88 0,88 0,88 0,87 0,87 0,85 0,88 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
38 (Я): 0,52 0,52 0,83 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,84 0,84 0,95 1,00 0,87 0,88 0,88 0,88 0,87 0,87 0,85 0,88 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
39 (ПМ): 0,52 0,52 0,83 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,84 0,84 0,93 0,93 1,00 0,88 0,88 0,88 0,87 0,87 0,85 0,88 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
40 (СМIII): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 1,00 0,94 0,94 0,82 0,82 0,81 0,90 0,82 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
41 (АД): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,99 1,00 0,94 0,82 0,82 0,81 0,90 0,82 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
42 (Е): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,96 0,94 1,00 0,82 0,82 0,81 0,90 0,82 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
43 (Ц): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,93 0,93 0,93 1,00 0,91 0,81 0,90 0,94 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
44 (ОII): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,91 0,91 0,91 0,89 1,00 0,81 0,90 0,89 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
45 (ХБ): 0,52 0,52 0,73 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 0,73 1,00 0,73 0,73 0,73 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
46 (ТБIII): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,87 0,87 0,87 0,82 0,82 0,81 1,00 0,82 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
47 (ЕII): 0,52 0,52 0,78 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,78 0,78 0,78 0,78 0,78 0,88 0,88 0,88 0,87 0,87 0,81 0,88 1,00 0,80 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
48 (ФБ): 0,52 0,52 0,75 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 0,75 1,00 0,52 0,52 0,52 0,52 0,52 0,50 0,52 0,57 0,52
49 (Тр): 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 1,00 0,79 0,83 0,82 0,41 0,41 0,41 0,41 0,41
50 (СII): 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,72 1,00 0,76 0,76 0,41 0,41 0,41 0,41 0,41
51 (КБIII): 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,72 0,78 1,00 0,81 0,41 0,41 0,41 0,41 0,41
52 (СIII): 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,72 0,78 0,84 1,00 0,41 0,41 0,41 0,41 0,41
53 (У): 0,67 0,54 0,67 0,54 0,45 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,67 0,59 0,59 0,59 0,59 1,00 0,50 0,56 0,61 0,54
54 (Ио): 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 0,30 1,00 0,30 0,30 0,30
55 (Врс): 0,60 0,54 0,60 0,54 0,45 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,54 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,60 0,71 0,71 0,71 0,71 0,58 0,50 1,00 0,60 0,54
56 (Кст): 0,52 0,52 0,55 0,52 0,45 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,52 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,55 0,52 0,52 0,52 0,52 0,52 0,50 0,52 1,00 0,52
57 (Прм): 0,41 0,82 0,41 0,82 0,41 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,82 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,41 0,44 0,44 0,44 0,44 0,41 0,41 0,41 0,41 1,00
Библиография
1. Прикладная и компьютерная лингвистика/ И.С.Николаев, О.В.Митренина, Т.М.Ландо., М.: 2016. 320 C.
2. Colwell E.C. and Tune E.W. The quantitative relationship between MS text-types// Biblical and patristic studies in memory of R.P.Casey/ Ed. by J.N.Birdsall and P.W.Thomson. Freiburg, 1963. P.25-32.
3. Dees A. Sur une constellation de quatre manuscits// Melanges de linguistique et de literature offertes a Lein Geschiere. Amsterdam, 1975. P.1-9.
4. Wattel E. Constructing Initial Binary Trees in Stemmatology// Studies in Stemmatology II/ Ed. By Reenen P.van, Mulken M. van. Amsterdam, 2004. P.145-166.
5. Алексеев А.А. Текстология славянской библии. Спб., 1999. 190 С.
6. Froger D.J. La critique des textes et son automatization. Paris, 1968. 280 P.
7. Бородкин Л.И., Милов Л.В. О некоторых аспектах автоматизации текстологического исследования (Закон Судный людем)// Математические методы в историко-экономических и историко-культурных исследованиях: сборник статей. М., 1977. С. 235-280.
8. Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. М., 1976. 165 С.
9. Шпирко С.В. Применение теории нечетких множеств к задаче генеалогической классификации в текстологическом исследовании// Историческая информатика: Информационные технологии и математические методы в исторических исследованиях. Барнаул, 2013. № 3. С. 39-51.
10. Лихачев Д.С. Текстология. М.-Л., 1983. 640 С.
11. Мелихов А.Н., Бернштейн Л.С., Коровин С.Я. Ситуационные советующие системы с нечеткой логикой. М., 1990. 272 С.
12. Шпирко С.В., Баранкова Г.С. О некоторых аспектах построения формализованной генеалогической классификации текстов списков средневекового произведения с применением теории нечетких множеств (на материале «Закона Судного людем»)// Исторический журнал: научные исследования. 2017. № 1. С. 56-64. DOI: 10.7256/2222-1972.2017.1.21194.
13. Saaty T.L. Measuring the fuzziness of sets// Journal of Cybernetics. V. 4. 1974. P.53-61.
14. Гальченко М. Г. О времени появления и характере распространения ряда графико-орфографических признаков второго южнославянского влияния в древнерусских рукописях конца ХІV — первой половины ХV вв. // Лингвистическое источниковедение и история русского языка./ Сборник статей. М., 2000. С. 123—152.
15. Шпирко С.В. Методы текстологической генеалогической классификации: матрица близости vs матрица нечеткого отношения// Историческая информатика: Информационные технологии и математические методы в исторических исследованиях. Барнаул, 2016. № 3-4. С. 24-32.
16. Закон Судный людем краткой редакции// Тихомиров М.Н., Милов Л.В. М.,1961. 177 С.
17. Правда Русская. Том 1. Тексты. М.-Л., 1940. 505 С.
18. Корогодина М.В. Кормчие книги XIV – первой половины XVII вв. как исторический источник: диссертация доктора исторических наук: 07.00.09: защищена 21.10.2015. Спб., 2015. 540 С.
19. Максимович К.А. Закон Судный людем. Источниковедческие и лингвистические аспекты исследования славянского юридического памятника. М., 2004. 240 С.
References
1. Prikladnaya i komp'yuternaya lingvistika/ I.S.Nikolaev, O.V.Mitrenina, T.M.Lando., M.: 2016. 320 C.
2. Colwell E.C. and Tune E.W. The quantitative relationship between MS text-types// Biblical and patristic studies in memory of R.P.Casey/ Ed. by J.N.Birdsall and P.W.Thomson. Freiburg, 1963. P.25-32.
3. Dees A. Sur une constellation de quatre manuscits// Melanges de linguistique et de literature offertes a Lein Geschiere. Amsterdam, 1975. P.1-9.
4. Wattel E. Constructing Initial Binary Trees in Stemmatology// Studies in Stemmatology II/ Ed. By Reenen P.van, Mulken M. van. Amsterdam, 2004. P.145-166.
5. Alekseev A.A. Tekstologiya slavyanskoi biblii. Spb., 1999. 190 S.
6. Froger D.J. La critique des textes et son automatization. Paris, 1968. 280 P.
7. Borodkin L.I., Milov L.V. O nekotorykh aspektakh avtomatizatsii tekstologicheskogo issledovaniya (Zakon Sudnyi lyudem)// Matematicheskie metody v istoriko-ekonomicheskikh i istoriko-kul'turnykh issledovaniyakh: sbornik statei. M., 1977. S. 235-280.
8. Zade L. Ponyatie lingvisticheskoi peremennoi i ego primenenie k prinyatiyu priblizhennykh reshenii. M., 1976. 165 S.
9. Shpirko S.V. Primenenie teorii nechetkikh mnozhestv k zadache genealogicheskoi klassifikatsii v tekstologicheskom issledovanii// Istoricheskaya informatika: Informatsionnye tekhnologii i matematicheskie metody v istoricheskikh issledovaniyakh. Barnaul, 2013. № 3. S. 39-51.
10. Likhachev D.S. Tekstologiya. M.-L., 1983. 640 S.
11. Melikhov A.N., Bernshtein L.S., Korovin S.Ya. Situatsionnye sovetuyushchie sistemy s nechetkoi logikoi. M., 1990. 272 S.
12. Shpirko S.V., Barankova G.S. O nekotorykh aspektakh postroeniya formalizovannoi genealogicheskoi klassifikatsii tekstov spiskov srednevekovogo proizvedeniya s primeneniem teorii nechetkikh mnozhestv (na materiale «Zakona Sudnogo lyudem»)// Istoricheskii zhurnal: nauchnye issledovaniya. 2017. № 1. S. 56-64. DOI: 10.7256/2222-1972.2017.1.21194.
13. Saaty T.L. Measuring the fuzziness of sets// Journal of Cybernetics. V. 4. 1974. P.53-61.
14. Gal'chenko M. G. O vremeni poyavleniya i kharaktere rasprostraneniya ryada grafiko-orfograficheskikh priznakov vtorogo yuzhnoslavyanskogo vliyaniya v drevnerusskikh rukopisyakh kontsa KhІV — pervoi poloviny KhV vv. // Lingvisticheskoe istochnikovedenie i istoriya russkogo yazyka./ Sbornik statei. M., 2000. S. 123—152.
15. Shpirko S.V. Metody tekstologicheskoi genealogicheskoi klassifikatsii: matritsa blizosti vs matritsa nechetkogo otnosheniya// Istoricheskaya informatika: Informatsionnye tekhnologii i matematicheskie metody v istoricheskikh issledovaniyakh. Barnaul, 2016. № 3-4. S. 24-32.
16. Zakon Sudnyi lyudem kratkoi redaktsii// Tikhomirov M.N., Milov L.V. M.,1961. 177 S.
17. Pravda Russkaya. Tom 1. Teksty. M.-L., 1940. 505 S.
18. Korogodina M.V. Kormchie knigi XIV – pervoi poloviny XVII vv. kak istoricheskii istochnik: dissertatsiya doktora istoricheskikh nauk: 07.00.09: zashchishchena 21.10.2015. Spb., 2015. 540 S.
19. Maksimovich K.A. Zakon Sudnyi lyudem. Istochnikovedcheskie i lingvisticheskie aspekty issledovaniya slavyanskogo yuridicheskogo pamyatnika. M., 2004. 240 S.
|
 Рус
Рус