|
Кибернетика и программирование
Правильная ссылка на статью:
Потапов Д.Р., Артемов М.А., Барановский Е.С., Селезнев К.Е.
Обзор методов построения контейнеров данных «ключ-значение» для использования в самоадаптирующихся контейнерах данных
// Кибернетика и программирование.
2017. № 5.
С. 14-45.
DOI: 10.25136/2644-5522.2017.5.23557 URL: https://nbpublish.com/library_read_article.php?id=23557
Обзор методов построения контейнеров данных «ключ-значение» для использования в самоадаптирующихся контейнерах данных
Потапов Данила Романович
аспирант, кафедра программного обеспечения и администрирования информационных систем, Воронежский государственный университет
394018, Россия, г. Воронеж, ул. Университетская Площадь, 1, ауд. 222
Potapov Danila Romanovich
post-graduate student of the Department of Software and Information Systems Administration at Voronezh State University
394018, Russia, Voronezh, str. Universitetskaya Square, 1, room No. 222

|
potapovd36@gmail.com
|
|
 |
Артемов Михаил Анатольевич
доктор физико-математических наук
заведующий кафедрой программного обеспечения и администрирования информационных систем, Воронежский государственный университет
394018, Россия, г. Воронеж, ул. Университетская Площадь, 1, ауд. 222
Artemov Mikhail Anatol'evich
Doctor of Physics and Mathematics
head of the Department of Software and Information Systems Administration at Voronezh State University
394018, Russia, Voronezh, str. Universitetskaya Square, 1, room No. 222
|
|
artemov_m_a@mail.ru
|
|
 |
Барановский Евгений Сергеевич
кандидат физико-математических наук
доцент, кафедра программного обеспечения и администрирования информационных систем, Воронежский государственный университет
394018, Россия, г. Воронеж, ул. Университетская Площадь, 1, ауд. 222
Baranovskii Evgenii Sergeevich
PhD in Physics and Mathematics
associate professor of the Department of Software and Information Systems Administration at Voronezh State University
394018, Russia, Voronezh, str. Universitetskaya Square, 1, room No. 222
|
|
esbaranovskii@gmail.com
|
|
 |
|
Селезнев Константин Егорович
кандидат технических наук
доцент, кафедра программного обеспечения и администрирования информационных систем, Воронежский государственный университет
394018, Россия, г. Воронеж, ул. Университетская Площадь, 1, ауд. 222
Seleznev Konstantin Egorovich
PhD in Technical Science
associate professor of the Department of Software and Information Systems Administration at Voronezh State University
394018, Russia, Voronezh, str. Universitetskaya Square, 1, room No. 222
|
|
skostik@relex.ru
|
|
 |
|
DOI: 10.25136/2644-5522.2017.5.23557
Дата направления статьи в редакцию:
10-07-2017
Дата публикации:
30-10-2017
Аннотация:
В статье рассматриваются существующие методы построения ассоциативных контейнеров данных, которые могут быть использованы в самоадаптирующихся контейнерах данных. Построение ассоциативных контейнеров является актуальной задачей в связи с возросшей популярностью и частым использованием таких контейнеров в области NoSQL и BigData. В работе представлен обзор и анализ отсортированных и хешированных контейнеров, таких как различные виды деревьев, SSTable, хеш-таблицы и др. Кроме того, рассматриваются основные области применения этих структур. Статья имеет обзорный характер и направлена на анализ и сравнение существующих методов построения контейнеров данных «ключ-значение». Несмотря на то, что данная тематика достаточно широко представлена в научной литературе, к настоящему времени не существует работ, полностью посвященных систематическому обзору и анализу методов построения контейнеров данных «ключ-значение». В результате проведенного в статье анализа были выявлены основные сферы применения контейнеров при реализации самоадаптирующихся ассоциативных контейнеров данных.
Ключевые слова:
хранение данных, оптимальный контейнер, ассоциативные контейнеры, Б-деревья, сбалансированные деревья, SSTable, LSM-дерево, фрактальное дерево, куча, хеширование
УДК: 004.043
Abstract: The article is devoted to existing methods of constructing associative data containers that can be used in self-adapting data containers. Construction of associative containers is a topical issue due to the growing popularity and frequent use of such containers in the spheres of NoSQL and BigData. The present article provides a review and analysis of sorted-out and hashed containers such as various kinds of trees, SSTable, hash-tables, etc. In addition, the authors of the article also analyze the scope of application of these structures. The article is of reviewing nature and aims at analysis and comparison of existing methods of key-value data containers construction. Despite the fact that this topic is widely presented in the academic literature, at the present time there are no works that would be fully devoted to the systematic review and analysis of key-value data containers construction. As a result of the research, the authors have defined the main spheres of application of data containers when using self-adapting associative data containers.
Keywords: store the data, optimal container, associative containers, B-trees, balanced trees, SSTable, LSM tree, fractal tree, heap, hashing
Введение
В течение долгого времени реляционные базы данных (БД) доминировали в индустрии программного обеспечения, предоставляя механизмы для хранения данных, работы с многопоточностью и транзакциями и в основном стандартные интерфейсы для интеграции с приложениями и генерации отчетности. Однако в последнее время возрасла популярность нового типа баз данных, известного как NoSQL, который стал альтернативой реляционным базам данных. Под NoSQL («неSQL» или «не только SQL») понимают ряд подходов, направленных на реализацию хранилищ баз данных, которые существенно отличаются от реляционных и имеют возможность линейно масштабироваться. В отличие от реляционной модели, данные в таких БД не структурированы (структура данных не регламентирована) и агрегированы (одна сущность не разбивается на несколько таблиц и максимально оптимизирована под нужды приложения).
Появление NoSQL баз данных связано с появлением больших объемов данных, для работы с которыми возникла необходимость в распределенных БД, работающих на кластерах. Для создания таких баз пришлось ослабить свойства ACID (атомарность, согласованность, изолированность, надежность), применяемые к реляционным базам данных, и ввести новый набор свойств BASE (базовая доступность, гибкое состояние, согласованность в конечном счете). Это означает, что большинство NoSQL БД жертвуют согласованностью данных для обеспечения двух других свойств из теоремы CAP (согласованность, доступность, устойчивость к разделению), утверждающей, что для распределенных систем возможно выполнение только двух из трех свойств.
Кроме того, для обеспечения линейной масштабируемости применяются шардинг (разделение данных между узлами) и репликация (копирование данных на другие узлы при обновлении).
Существует несколько типов таких баз данных:
1. Хранилище «ключ-значение». Данный тип является простейшим с точки зрения пользователя и использует для доступа к значению ключ. При этом значение хранится в двоичном виде и БД не содержит сведений о структуре данных. Такие БД используются для хранения предпочтений пользователя, сессии, корзины покупателя. Примерами хранилищ «ключ-значение» являются Berkeley DB, Couchbase, MemcacheDB, upscaledb, Redis, Riak, Voldemort, Oracle BDB, Amazon DynamoDB.
2. Документо-ориентированное хранилище. Такое хранилище хранит данные в виде «ключ-значение», где значение представлено в виде иерархической структуры. Документо-ориентированные хранилища применяются для систем управления контентом, платформ для блогов, web- и онлайн- аналитики, электронной коммерции. К таким БД относятся MongoDB, CouchDB, Terrastore, OrientDB, RavenDB, eXist, Berkeley DB XM.
3. Хранилище семейств колонок. Данные в таком хранилище хранятся в семействах колонок (аналог таблиц в реляционных БД). Главное отличие от реляционной модели в том, что набор колонок у каждой строки может быть уникален и в любой момент колонку у конкретной строки можно удалить или добавить. Хранилища семейств колонок используются для платформ для блогов, систем управления контентом, хранения различных счетчиков, времени жизни объектов, записи логов. Примерами таких БД являются Cassandra, HBase, Hypertable, Amazon DynamoDB, Apache Accumulo, SimpleDB.
4. Хранилище на основе графа. Данный тип хранит данные в виде узлов графа, а отношения между объектами – в виде ребер. Хранилища на основе графа широко применяются для социальных сетей, многомерных данных, систем рекомендаций. К таким БД относятся Neo4j, OrientDB, AllegroGraph, Blazegraph, InfoGrid, InfiniteGraph, FlockDB, Titan.
Помимо различия в моделях данных, NoSQL СУБД сильно отличаются друг от друга и внутренним устройством. Для реализации хранилищ используются различные структуры данных: хеш-таблицы, деревья и др., которые делятся на ассоциативные («ключ-значение») и последовательные. Последовательные контейнеры хранят данные в памяти линейно, сохраняя относительные позиции элементов. Ассоциативные контейнеры не сохраняют порядок, в котором вставляются элементы, а вместо этого используют ключи, хранящиеся в элементе (или сам элемент в качестве ключа) для достижения максимальной скорости вставки, выборки и удаления [1]. В данной статье будет рассматриваться построение именно ассоциативных контейнеров, так как они являются наиболее популярными и используемыми в NoSQL [2] базах данных.
Методы построения контейнеров данных «ключ-значение» можно разделить на две категории. Одна группа методов подразумевает использование некоторого глобального упорядочения (числового или лексикографического). Ключи хранятся в отсортированном состоянии, а для поиска используется бинарный алгоритм. Контейнеры, полученные данным методом, называются отсортированными ассоциативными контейнерами. Примерами таких контейнеров являются различные деревья.
Второй группой методов является хеширование, а контейнеры, полученные данным методом, называются хешированными ассоциативными контейнерами. Примерами таких контейнеров являются различные вариации хеш-таблиц.
На рис. 1 изображена классификация ассоциативных контейнеров, проанализированных в данной статье.

Рис. 1
Отсортированные ассоциативные контейнеры
В отсортированном ассоциативном контейнере все ключи отсортированы в некотором порядке. Простейшим примером такого контейнера является Sorted String Table (SSTable) [3]. Этот контейнер является одним из самых популярных для хранения, обработки и обмена большими наборами данных. Он используется в таких известных NoSQL базах данных как Cassandra [4], HBase и LevelDB. Данный контейнер хорошо подходит для ситуаций, когда необходимо обработать гигабайты или даже терабайты информации и выполнить на них последовательность из заданий Map-Reduce [5]. В этом случае из-за размера входных данных затраты на операции чтения и записи будут преобладать над затратами на выполнение полезной работы. Таким образом, использование случайного чтения/записи крайне неэффективно; вместо этого можно использовать потоковое чтение и запись, что позволяет значительно уменьшить расходы на операции чтения/записи. SSTable позволяет использовать такое чтение, за счет своего внутреннего устройства. Данный контейнер представляет собой последовательность отсортированных по ключу пар «ключ-значение». Следовательно, временная сложность основных операций над этим контейнером соответствует временной сложности отсортированного массива (табл. 1).
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(log n)
|
|
Вставка
|
O(n)
|
O(n)
|
|
Удаление
|
O(n)
|
O(n)
|
Табл. 1
SSTable позволяет хранить дубликаты и не имеет ограничений на размер ключей и значений. Кроме того, для данного контейнера можно обеспечить доступ по ключу за константное время. Для этого необходимо создать отсортированный индекс, последовательно считывая данные из контейнера. Индекс будет упорядочен по ключу и будет содержать смещения до соответствующих значений, как показано на рис. 2.
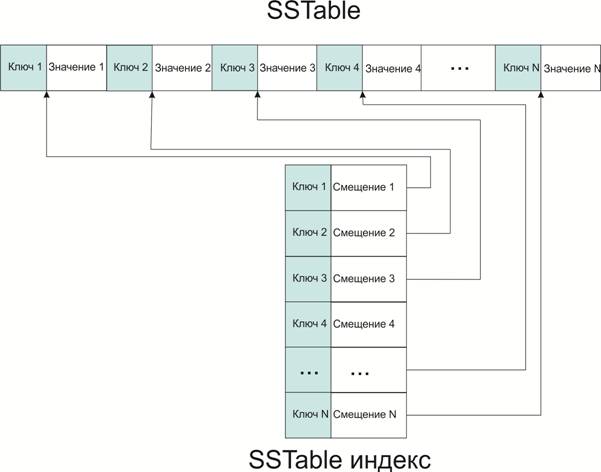
Рис. 2
Главное преимущество SSTable состоит в простоте и эффективности хранения и обработки большого объема данных, но у данного контейнера существует и значительный минус. Для работы с большими данными необходимо, чтобы SSTable размещался на жестком диске. Следовательно, любое изменение контейнера (удаление или вставка элемента) будет требовать больших затрат на дисковый ввод-вывод. Это связано с тем, что SSTable представляет собой отсортированный по ключу массив и для его изменения необходимо перестроить весь контейнер.
Таким образом, SSTable лучше всего использовать для хранения статических индексов, так как для извлечения с диска можно последовательно считывать данные, установив головку диска всего один раз. Достаточно быстро происходит и случайное чтение. Следовательно, любая операция по изменению данного контейнера является слишком длительной и дорогостоящей, особенно, когда SSTable располагается не в оперативной памяти. Поэтому обычно в NoSQL СУБД SSTable, которые располагаются на диске, являются неизменяемыми.
Для решения основной проблемы SSTable (крайне неэффективной случайной записи) был разработан другой контейнер – LSM (Log-Structured Merge) дерево [6], которое будет описано ниже.
При использовании данного контейнера в самоадаптирующихся контейнерах [7] необходимо учитывать, что перестроение в SSTable из других контейнеров в основном требует больших затрат (особенно если SSTable располагается на диске), так как данные в памяти или на диске должны быть упорядочены по ключу. Данный контейнер следует использовать в самоадаптирующихся контейнерах только тогда, когда известно, что длительное время контейнер будет использоваться только для частого чтения больших данных, а следовательно, преимущества последовательного чтения перекроют затраты на построение.
Помимо SSTable существует другая группа отсортированных ассоциативных контейнеров – деревья поиска.
Древовидные структуры
Древовидная структура [8] данных – это динамическая связанная структура, в которой связи между элементами не линейны как в списке, а похожи на ветви дерева. Существует две категории данных структур, которые различны по методам построения и обработки. Первая – это деревья, вторая – кучи. Кроме того, деревья различают по другим атрибутам:
1. Сбалансированность. Дерево может быть:
− вырожденным;
− идеально сбалансированным;
− cбалансированным;
− несбалансированным и невырожденным.
2. Количество ветвей. Дерево может быть:
− двоичным;
− многопутевым, когда количество ветвей больше двух.
Бинарные деревья
Самым простым деревом поиска является бинарное (двоичное) дерево [9]. Временная сложность данного дерева представлена в табл. 2.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(n)
|
|
Вставка
|
O(log n)
|
O(n)
|
|
Удаление
|
O(log n)
|
O(n)
|
Табл. 2
Данные деревья являются одними из самых популярных в связи с простой реализацией и достаточно высокой эффективностью. Главным достоинством бинарного дерева является возможность реализовать высокоэффективные алгоритмы сортировки и поиска, построенные на его основе. Кроме того, это дерево используется при реализации контейнеров set и map в с++ и TreeSet и TreeMap в Java [10].
Бинарные деревья могут быть вырожденными, сбалансированными, идеально сбалансированными или не относится ни к одной из этих категорий. На практике обычно используются сбалансированные деревья, так как вырожденные деревья превращаются в список, а идеально сбалансированные трудоемки в построении и балансировка в них происходит достаточно часто.
Существует несколько реализаций сбалансированного дерева [12].
1. АВЛ-дерево [13]. В данном дереве дополнительно требуется 2 бита на каждый узел дерева. Кроме того, при изменении дерева требуются операции балансировки (при вставке до двух поворотов, при удалении до высоты дерева), что также требует дополнительных затрат. Временная сложность данного дерева представлена в табл. 3.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(log n)
|
|
Вставка
|
O(log n)
|
O(log n)
|
|
Удаление
|
O(log n)
|
O(log n)
|
Табл. 3
2. Красно-черное дерево [14]. Временная сложность данного дерева представлена в табл. 4.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(log n)
|
|
Вставка
|
O(log n)
|
O(log n)
|
|
Удаление
|
O(log n)
|
O(log n)
|
Табл. 4
При реализации данного дерева необходимо дополнительно для каждой вершины хранить цвет (1 бит). Иногда в связи с необходимостью выравнивания памяти данное условие приводит к большим затратам памяти. Кроме того, при изменении дерева требуются операции балансировки (при вставке до двух поворотов, при удалении до трех), что также требует дополнительных затрат. Красно-черные деревья применяются в различных областях: в ядре операционной системы Linux для обработки очередей запросов, в файловой системе ext3 и в различных библиотеках для реализации set и map.
Помимо этого существует модификация АА-дерево, которая имеет еще одно условие: красный узел может быть только правым потомком. Это условие позволяет упростить реализацию всех операций, так как возможных случаев для разбора становится меньше. Быстродействие данного дерева сопоставимо с красно-черным деревом, но АА-дерево для каждой вершины хранит еще и «уровень», что приводит к дополнительным затратам памяти.
Красно-черные деревья могут иметь высоту в 1.388 раз больше, чем АВЛ при том же количестве узлов. Это приводит к тому, что время вставки и поиска может больше у красно-черного дерева, но удаление из АВЛ-дерева может потребовать количество поворотов равное глубине дерева, что делает удаление более выгодным в красно-черном дереве.
3. Декартово дерево [15]. Данная структура имеет и другие названия, например, дерамида (в английской литературе treap), так как эта структура данных является объединением двоичного дерева и пирамиды. Пирамида – структура данных аналогичная дереву, но с одним условием: значение в любом узле не меньше, чем значения его детей.
Каждый узел декартова дерева содержит пару значений (x, y), при этом x называют ключом, y – приоритетом. Таким образом, по у данное дерево получается пирамидой, а по х – бинарным деревом. Пример такого дерева изображен на рис. 3. Приоритеты обычно выбираются случайным образом, чтобы избежать чрезмерно большой высоты дерева (в худшем случае O(n)). Для выполнения основных операций с данным деревом используются две операции: Merge и Split.
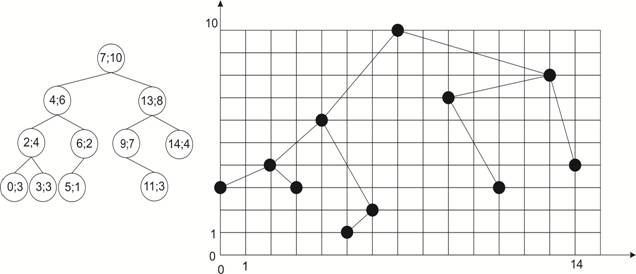
Рис. 3
Временная сложность данного дерева представлена в табл. 5. Стоит обратить внимание на значение худшего случая amortized O(log n). Это означает, что среднее значение для худшего случая всегда O(log n), т. е. часть операций на одном дереве могут выполняться за большее время (максимум O(N)), но тогда остальная часть операций будет выполняться за меньшее время. Данное свойство следует из следующей теоремы: «В декартовом дереве из n узлов, приоритеты y которого являются случайными величинами c равномерным распределением, средняя глубина вершины O(log n)» [15, с. 28]. Это означает, что среднее время операций Split и Merge – O(log n).
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
amortized O(log n)
|
|
Вставка
|
O(log n)
|
amortized O(log n)
|
|
Удаление
|
O(log n)
|
amortized O(log n)
|
Табл. 5
Также необходимо отметить сложность создания такого дерева. В общем случае – O(N log N), так как операция добавления занимает O(log N). Также возможен случай построения за O(N) в случае, когда ключи приходят в возрастающем порядке.
Еще одной особенностью дерева является достаточно большой перерасход по памяти (от 2 до 4 байт на узел для того, чтобы хранить высоту). Таким образом, данное дерево невозможно использовать там, где необходима гарантированная производительность, к примеру, в системах реального времени и ядрах ОС.
Данные деревья хорошо подходят для сбора статистики по большому числу параметров, так как эти деревья позволяют считать сумму/разницу, минимум/максимум, а также другие операции за время O(log N).
Кроме того, существует модификация – декартово дерево по неявному ключу. Эта структура предоставляет интерфейс динамического массива, но она реализована на основе декартова дерева. Декартово дерево по неявному ключу позволяет реализовать большое количество операций с массивом и подмассивами за логарифмическое время.
4. Splay-дерево [16]— двоичное дерево, которое не имеет дополнительных требований к устройству дерева и само балансируется в процессе работы.
В некоторые моменты времени splay-дерево может оказаться абсолютно несбалансированным. Splay-дерево поддерживает сбалансированность с помощью специальной функции splay. Эта функция ищет необходимый узел и делает его корнем путем простейших поворотов, которые изменяют структуру дерева, при этом сохраняя упорядоченность в дереве. Splay активируется после каждой операции, в том числе и поиска.
Временная сложность данного дерева представлена в табл. 6. В данном дереве нельзя гарантировать сложность операций O(log n), так как дерево во время запроса может быть разбалансировано, следовательно, высота дерева – более log(n). Поэтому здесь также используется значение amortized O(log n). Данная оценка достигается за счет того, что поиск элементов, которые были использованы недавно, будет более быстрым и компенсирует случай указанный ранее.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
amortized O(log n)
|
|
Вставка
|
O(log n)
|
amortized O(log n)
|
|
Удаление
|
O(log n)
|
amortized O(log n)
|
Табл. 6
Основным преимуществом данного дерева является производительность. Было произведено тестирование в реальных условиях и splay-дерево оказалось в полтора-два раза эффективнее, чем другие сбалансированные двоичные деревья. Однако в теории доказано, что если вероятности использования элементов одинаковы во времени, то дерево будет работать так же, как и остальные реализации. При этом при произвольных вероятностях обращения к элементам дерево работает в полтора раза медленней. Таким образом, splay-дерево нельзя использовать в системах реального времени и большинстве библиотек для общего пользования.
Помимо производительности к преимуществам данного дерева относятся отсутствие дополнительных издержек по памяти, а к недостаткам – сильное ограничение при использовании в мультипоточной среде и ограничения в чисто функциональных языках.
5. Scapegoat-дерево [17]. У данного дерева имеется параметр alpha, который лежит в пределах (0.5, 1). Этот параметр указывается при создании дерева и определяет высоту дерева по формуле
`O(log_(1/alpha)N)` .
Следовательно, alpha влияет на скорость модификации и поиска, например, при alpha = 0.5 получаем сбалансированное дерево (максимальная скорость поиска, но минимальная скорость модификации), а при alpha → 1 получаем связный список (максимальная скорость модификации, но минимальная скорость поиска). При этом поиск происходит аналогично обычному дереву поиска, а вставка и удаление отличаются.
Для реализации этих операций ищется элемент, который нарушает сбалансированность, и после этого идет перебалансировка поддерева, где корнем является элемент, нарушивший сбалансированность.
Временная сложность данного дерева представлена в табл. 7. В худшем случае операции модификации могут занять O(N) времени (в зависимости от узла), но данная операция распределена по дереву, следовательно, среднее время для худшего случая O(log N).
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(n)
|
|
Вставка
|
O(log n)
|
amortized O(log n)
|
|
Удаление
|
O(log n)
|
amortized O(log n)
|
Табл. 7
К преимуществам Scapegoat-дерева можно отнести отсутствие дополнительных затрат по памяти и возможность задавать соотношение между скоростью операций поиска и модификации, руководствуясь условиями конкретной задачи. Минусом данного дерева является отсутствие гарантированного времени операций вставки и удаления. К тому же неправильное задание параметра alpha может привести к ситуации, когда Scapegoat-дерево окажется крайне неэффективным.
Многопутевые деревья
Помимо бинарных деревьев существуют и деревья с количеством ветвей больше двух. Такие деревья называются многопутевыми или сильноветвящимися. Самым распространенным является Б-дерево и его различные модификации [18]. Временная сложность такого дерева отображена в табл. 8. Б-дерево используется в системах баз данных (индексы во многих современных СУБД) и файловых системах.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log n)
|
O(log n)
|
|
Вставка
|
O(log n)
|
O(log n)
|
|
Удаление
|
O(log n)
|
O(log n)
|
Табл. 8
У данного дерева существует большое количество вариаций. Ниже представлены самые известные из них.
1. Б+-дерево, также известное как дерево Байера-Баума [19]. Это дерево используется в файловых системах для хранения каталогов и индексирования метаданных (NTFS, BeFS и другие), в реляционных СУБД – в качестве индекса (Oracle, SQLite и другие), в NoSQL базах данных – для доступа к данным (CouchDB).
2. Б*-дерево [20]. Эта структура данных аналогична Б-дереву, но имеет другой минимальный коэффициент заполненности вершины — ⅔ (в Б-дереве ½). Данная модификация позволяет использовать память более эффективно и дает небольшой прирост производительности. К минусам Б*-дерева можно отнести более сложную функцию разделения переполненного узла. Сферы применения этого дерева аналогичны сферам применения Б-дерева.
3. 2-3-дерево [9]. Данное дерево – частный случай Б+-дерева, которое может иметь только узлы с одним ключом (содержит максимум левого поддерева) и двумя потомками и узлы с двумя ключами (содержат максимумы левого и среднего поддеревьев) и 3 потомками. Терминальные узлы не имеют потомков.
Кроме того, существует 2-3-4-дерево (В-дерево степени 4), построенное по аналогичным правилам. Оно может использоваться для хранения словарей во внутренней памяти во избежание штрафов за промах кэша.
Многопутевые деревья, оптимизированные для записи
На протяжении долгого времени Б-дерево не имело альтернатив среди структур данных для хранения во внешней памяти. Но в последнее время ситуация стала меняться из-за необходимости обработки постоянно растущих объемов данных. Для достижения этой цели появились структуры данных, оптимизированные специально для операций записи. Некоторые из этих структур частично уступают Б-дереву в скорости поиска, но позволяют более эффективно осуществлять вставку и удаление. Существует несколько типов таких структур данных:
· деревья, использующие буфер;
· LSM и фрактальные деревья.
Деревья, использующие буфер
Деревья, которые используют буфер, также можно разделить на несколько типов:
1. Буферизированное дерево [21] – (a, b)-дерево (это сбалансированное сильно ветвящееся дерево, где каждый узел имеет степень O(m), а не B) с коэффициентами a = m/4, b = m, построенное над множеством O(n) листьев, каждый из которых содержит O(B) элементов. При этом каждый внутренний узел содержит буфер из m элементов. Данные хранятся только в листьях, в остальных узлах располагаются лишь разделительные ключи. Данные сначала добавляются в буфер корневого узла и только после переполнения этого узла распределяются по буферам последующих уровней и т. д. Так происходит до тех пор, пока данные не дойдут до нижнего уровня, где они уже остаются. При этом в случае необходимости применяется перебалансировка, аналогичная В-дереву. Использование буфера позволяет улучшить время вставки за счет пакетной обработки запросов, но использование оффлайн-модели (ответ на любой запрос приходит не сразу, а через какое-то время) делает недоступным использование буферизированного дерева для задач, где ответ нужен сразу и от него зависит дальнейшая логика. Временная сложность представлена в табл. 9.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O((logm n)/B)
|
O((logm n)/B)
|
|
Вставка
|
O((logm n)/B)
|
O((logm n)/B)
|
|
Удаление
|
O((logm n)/B)
|
O((logm n)/B)
|
Табл. 9
На основе данного дерева реализована очередь с приоритетами: range tree и segment tree, которые успешно решают некоторые геометрические проблемы и проблемы на графах. Также данное дерево позволяет использовать сортировку во внешней памяти с оценкой O(n logm n). При этом необязательно наличие всех элементов перед началом сортировки.
2. Bε–деревья [22] представляют собой класс деревьев, которые отличаются от буферизированных деревьев методом поиска данных и наличием параметра ε. Операция поиска в Bε–дереве также похожа на поиск в буферизированном дереве, но требует получения ответа сразу, что в свою очередь требует дополнительных операций для поиска данных в буферах. Временная сложность представлена в табл.10.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(logBN/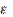 ) )
|
O(logBN/)
|
|
Вставка
|
O((logBN)/(ε*B1-ε ))
|
O((logBN)/(ε*B1-ε ))
|
|
Удаление
|
O((logBN)/(ε*B1-ε ))
|
O((logBN)/(ε*B1-ε ))
|
Табл. 10
Параметр ε определяет размер буфера (≈ B – Bε) и размер разделяющих ключей в узле (≈ Bε) при инициализации дерева и варьируется от 0 до 1. Схема дерева представлена на рис. 4.
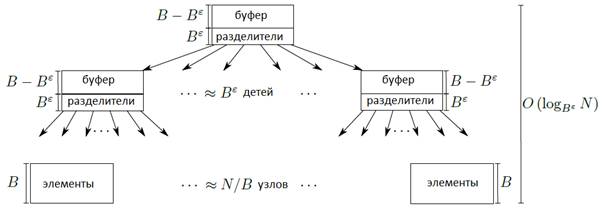
Рис. 4
При ε = 1 получается обычное В-дерево (размер буфера равен 0), а при ε = 0 получается модификация буферизированного дерева – Buffered Repository tree [23]. Это также (a, b)-дерево, но с коэффициентами a = 2, b = 4 и размерами буферов B вместо m. Данное дерево широко используется для обхода графа в ширину и глубину. Временная сложность представлена в табл. 11.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(log2N/B+k/B)
|
O(log2N/B+k/B)
|
|
Вставка
|
O((log2 N/B)/B)
|
O((log2 N/B)/B)
|
|
Удаление
|
O((log2 N/B)/B)
|
O((log2 N/B)/B)
|
Табл. 11
LSM и фрактальные деревья
LSM-дерево (англ. Log-structured merge-tree) [24] — структура данных, которая обеспечивает высокую скорость вставки с приемлемой скоростью поиска. Данное дерево известно также как журнально-структурированное дерево со слиянием, поскольку оно хорошо подходит для хранения журналов различных операций, которые постоянно обновляются и достаточно часто просматриваются.
Данное дерево состоит из двух и более структур, каждая из которых имеет высокую эффективность на том устройстве, на котором она хранится. В самом простом случае LSM-дерево содержит две древоподобные структуры, различные по размеру. Меньшая из них располагается во внутренней памяти, большая – во внешней памяти (рис. 5).
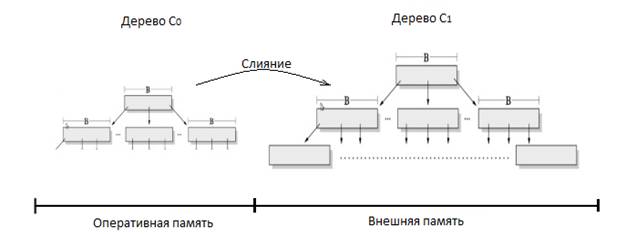
Рис. 5
При этом вставка осуществляется только в меньшее дерево (так как оно расположено в оперативной памяти и это намного быстрее), а при достижении определенного размера дерево из внутренней памяти отправляется во внешнюю и объединяется с большим деревом путем слияния (рис. 6).
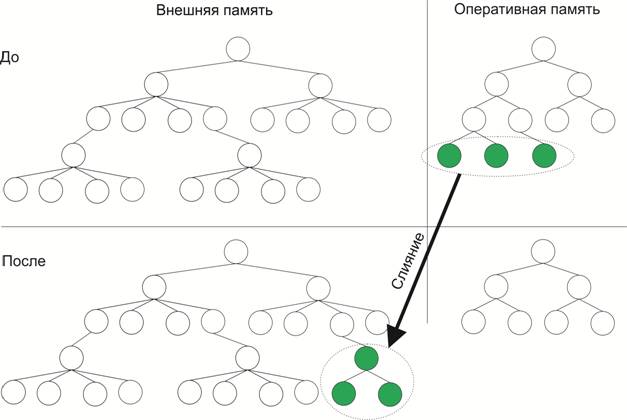
Рис. 6
На практике обычно применяются LSM-деревья, которые имеют несколько уровней. При этом каждый уровень представлен древоподобной структурой и при переполнении происходит объединение со следующим уровнем, как изображено на рис. 7.
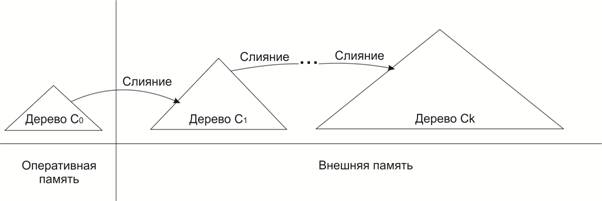
Рис. 7
Поиск в данной структуре занимает больше времени, чем в В-дереве, так как в худшем случае необходимо произвести поиск в каждом уровне. Время поиска составляет O(log N*logBN). Однако вставка осуществляется быстро, так как она происходит всегда в оперативную память (хотя необходимо учитывать возможное слияние). Амортизированная стоимость вставки составляет O((log N)/B), где B – размер блока в оперативной памяти.
Кроме того, для использования на практике применяются несколько улучшений. Например, для проверки наличия элемента в LSM-дереве можно использовать блум-фильтр для каждого уровня (например, BLSM-дерево [25]), а проблему вторичных индексов решает Diff-Index [26].
Самая простая реализация LSM-дерева не позволяет получать информацию о диапазоне ключей и получить отсортированную часть. Поэтому на практике используется архитектура, впервые примененная в LevelDB (рис. 8) [27]. В ней используются неизменяемые файлы на диске SSTable, а в памяти – MemTable. При этом при вставке определяется диапазон файлов SStable, которые должны измениться при слиянии, и меняются на уровне только эти файлы. LevelDb использует постоянное слияние файлов, чтобы усреднить затраты на слияние после определенного порога.
Также существуют СУБД, которые вместо нескольких файлов на одном уровне используют один большой, что позволяет уменьшить время слияния, но увеличивает занимаемое место почти в два раза. Данная стратегия слияния называется Leveled Compaction.
Кроме того, существует стратегия Size-Tiered, которая не делит SSTables на уровни и не ограничивает по размеру, а находит некоторое количество файлов (например, 4), приблизительно одинаковых по размеру и сливает их.
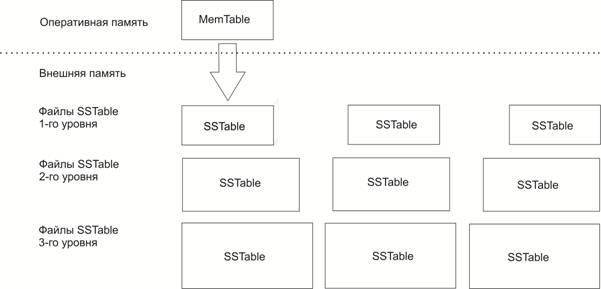
Рис. 8
LSM-дерево получило широкое распространение в NoSQL-базах данных, таких как Apache Cassandra, BigTable, LevelDB и многие другие, а также в новом «дисковом движке» Vinyl для СУБД Tarantool. Данные деревья особенно эффективно применять для данных с разной степенью актуальности (лента сообщений, чаты, стены в социальных сетях, события), хранения timeseries и журнала логов.
Основным недостатком LSM-дерева является необходимость поиска на каждом уровне со стоимостью O(logB N). Поэтому появилось еще одно дерево – фрактальное [28]. Изначально оно было основано на архитектуре COLA (cache-oblivious lookahead array), но сейчас это – модификация Bε-дерева с различными улучшениями по производительности и объемом листов в 4МБ, что сильно превышает объем листов в обычном В-дереве. Оно использует фрактальное каскадирование для уменьшения стоимости поиска на уровне до O(1).
Основная идея состоит в том, что при поиске по уровню Ti известно, где ключ должен быть на этом уровне и мы можем использовать данную информацию для улучшения поиска на следующем уровне Ti+1. Для этого в LSM-деревья добавляются ссылки на следующие уровни, и получается аналог В-дерева. Кроме того, на каждый узел отводится буфер, в который вносятся все изменения.
На рис. 9 изображена схема фрактального дерева; черным отмечены узлы дерева, белым – элементы узла, а серым – буферы. При переполнении буфера он отправляется в буферы дочерних узлов пока не дойдет до листьев, в которые и кладутся элементы. При этом все не листовые узлы служат как индексы для поиска, а листовые уже содержат информацию.
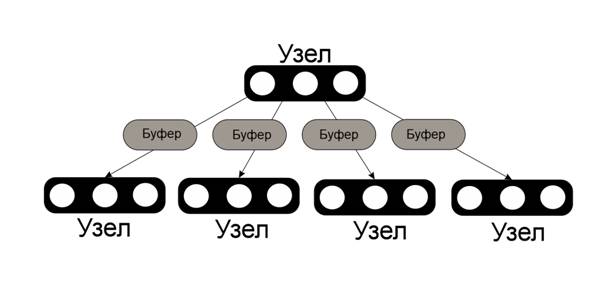
Рис. 9
При такой схеме вставка осуществляется достаточно быстро (так как родительский узел с несколькими буферами всегда в оперативной памяти), а поиск занимает то же время, что и в В-дереве (см. табл.12).
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(N/B)
|
O(N/B)
|
|
Поиск
|
O(logB N)
|
O(logB N)
|
|
Вставка
|
O(logB N/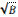 ) )
|
O(logB N/)
|
|
Удаление
|
O(logB N/)
|
O(logB N/)
|
Табл. 12
Основным недостатком по сравнению с LSM-деревом является сложное последовательное чтение, а также достаточно сложное удаление и обновление информации, так как необходимо найти данные.
Данное дерево используется как «движок» базы данных TokuDB для MySQL и MariaDB, а также как «движок» базы данных TokuMX для MongoDB. Кроме того, оно используется в прототипе файловой системы TokuFS.
Кучи
Другой древовидной структурой данных является куча [9]. Данный контейнер широко используется для различных задач. На основе кучи реализована очередь с приоритетом и пирамидальная сортировка, различные алгоритмы поиска и алгоритмы на графах [29].
Существует несколько вариантов кучи. Основные перечислены ниже.
1. Двоичная куча [30], также известная как пирамида. Это бинарное дерево, для которого выполнено главное свойство кучи. Все уровни в этой куче должны быть заполнены, кроме, может быть, последнего уровня, который обязательно должен быть заполнен слева направо как показано на рис. 10.
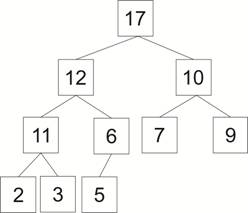
Рис. 10
2. Биномиальная куча [30]. Эта структура данных представляет собой отсортированный по размеру набор биномиальных деревьев, для каждого из которых выполняется свойство кучи. Кроме того, все деревья различные по размеру. Биномиальное дерево определяется индуктивно. B0 содержит только один узел, Bk содержит два биномиальных дерева Bk-1. При этом корень первого является потомком корня второго дерева. Куча представлена на рис. 11.
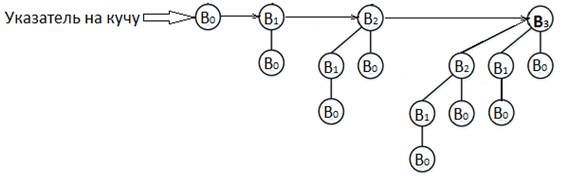
Рис. 11
3. Фибоначчиева куча (рис. 12) [31]. Данная структура состоит из множества фибоначчиевых деревьев (это n-арные деревья, для которых выполняется главное свойство кучи и вершины одного слоя соединены в двусвязный список). Обращение к куче происходит по ссылке на минимальный элемент, который содержится в корне одного из деревьев. Данная куча имеет хорошую производительность – амортизированное время работы O(1) для всех операций, кроме удаления (для нее – log(n)).
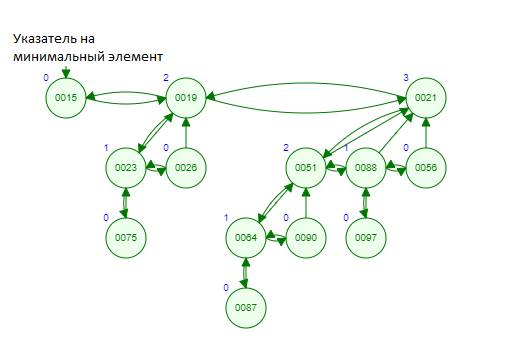
Рис. 12
4. Тонкая куча (англ. Thin heap) [32] представляет собой множество тонких деревьев, которые удовлетворяют свойству кучи (при этом ранги деревьев могут повторяться). Тонким деревом (англ. Thin tree) Tk ранга k называется биномиальное дерево Bk, у которого удалили левых потомков у нескольких вершин (рис. 13). При этом удалять нельзя у терминальных узлов (так как у них нет потомков) и у корня (иначе получится биномиальное дерево с меньшим рангом). На практике тонкая куча используется для реализации приоритетной очереди, но является более эффективной, чем фибоначчиева, поскольку имеет меньшие константы во времени работы.
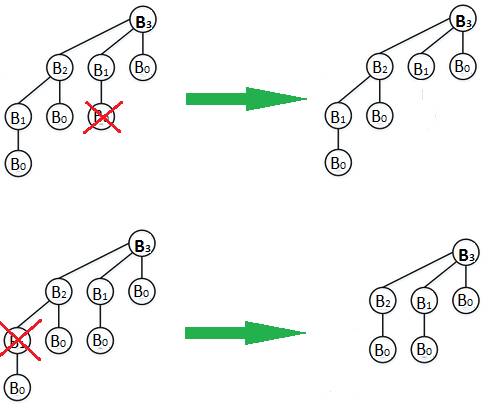
Рис. 13. Получение тонких деревьев из биномиального ранга 3
5. Толстая куча (англ. Thick heap, Fat heap) [32] представляет собой множество толстых деревьев, в котором ранги могут повторяться и может быть не более двух узлов на один ранг, содержащих значение меньше значения предка. Толстое дерево (англ. Thick tree) определяется индуктивно. F0 содержит одну вершину, Fk содержит три дерева ранга k–1, причем у корня одного из них самыми левыми сыновьями являются корни двух других (рис. 14).
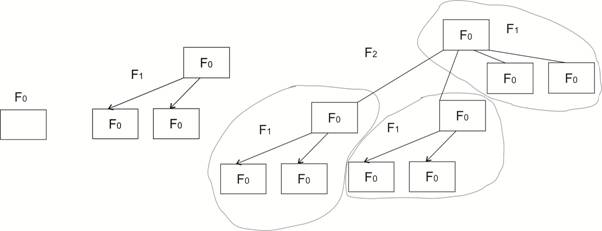
Рис. 14. Толстые деревья ранга 0, 1 и 2
Толстая куча, также как и тонкая, является модификацией фибоначчиевой, но на практике требует меньше места и является более эффективной.
6. Левосторонняя куча (англ. leftist heap) [33] — структура данных на основе бинарного левостороннего дерева, для которого выполняется главное свойство кучи. При этом дерево может быть несбалансированным. К тому же для данной кучи должно выполняться условие: ближайшее место, куда можно вставить вершину, должно быть самой правой позицией в дереве. Если обозначить d(v) как расстояние от вершины v до ближайшего места для вставки, то для всех вершин должно выполняться условие d(v.left) >= d(v.right). Так как в данной куче не происходит присваиваний, то она является персистентной и ее можно реализовать на функциональном языке.
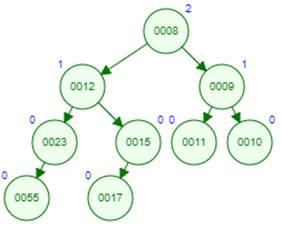
Рис. 15. Пример левосторонней кучи, где синие цифры обозначают расстояние до ближайшего места для вставки
7. 2-3-куча (2-3 heap) [34] представляет собой набор деревьев H[i], где i = 0..n, для которых выполняется главное условие кучи. H[i] – это дерево, содержащее от нуля до двух 2-3-дерева степени i, которые объединены по следующему правилу: корень каждого следующего является самым правым сыном предыдущего. 2-3-дерево определяется индуктивно. T0 –дерево из одной вершины, Tj –два или три дерева Tj-1, которые объединены по тому же правилу, что и H[i]. Указанное устройство 2-3-кучи (рис. 16) позволяет выполнять балансировку и при удалении элементов, и при добавлении, что позволяет увеличить эффективность извлечения минимума по сравнению с фибоначчиевой кучей.
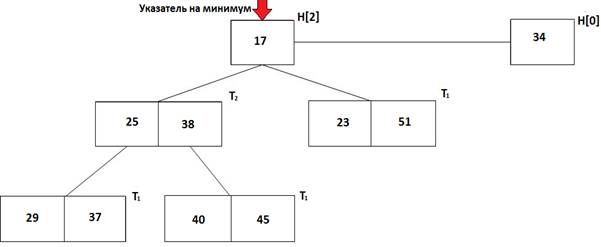
Рис. 16
8. Куча Бродала-Окасаки (англ. Brodal's and Okasaki's Priority Queue) [35]. Эта структура данных построена на нескольких принципах:
a. Применение специальной ассиметричной кучи. Это позволяет сделать вставку элемента за время О(1).
b. Хранение минимума, что позволяет извлекать его за О(1).
c. Идея Data-structural bootstrapping, позволяющая хранить очередь в очереди и уменьшить время слияния до О(1).
Таким образом, куча Бродала-Окасаки состоит из минимума и специальной приоритетной очереди, которая хранит кучи Бродала-Окасаки, отсортированные по Tmin. Данное описание может быть представлено в виде формулы BPQ = <Tmin, PQ(BPQ)>, где BPQ – Bootstrapping Priority Queues. В качестве приоритетной очереди (PQ) используется специальная куча – ассиметричная. Эта куча является модификацией биномиальной кучи, но позволяет два дополнительных типа деревьев (рис. 17 Б и рис. 17 В). Данная идея основана на использовании ассиметричного двоичного кодирования числа с использованием цифры 2 в последнем непустом разряде, что позволяет иметь максимум по одному дереву одного биномиального ранга, за исключением возможно минимально ранга (2 дерева). Это улучшение биномиальной кучи позволяет избежать каскадного слияния деревьев при вставке и уменьшить время вставки до O(1).
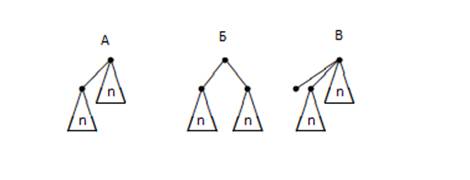
Рис. 17. Три способа получения дерева ранга n+1 из деревьев ранга n для ассиметричной кучи: А – одно дерево ранга n становится самым левым сыном другого, Б – оба дерева ранга n становятся сыновьями дерева нулевого ранга, В – одно дерево ранга n и дерево нулевого ранга становятся самыми левыми сыновьями другого дерева.
Сравнение различных вариантов кучи по временной сложности представлено в табл. 13.
|
Операция
|
Двоичная
|
Биномиальная
|
Фибоначчиева
|
2-3 куча
|
Бродал
|
Левосторонняя куча
|
|
найти минимум
|
Θ(1)
|
Θ(log n)
|
Θ(1)
|
Θ(1)*
|
Θ(1)
|
O(1)
|
|
удалить минимум
|
Θ(log n)
|
Θ(log n)
|
O(log n)*
|
O(log n)*
|
O(log n)
|
O(log n)
|
|
добавить
|
Θ(log n)
|
O(log n)
|
Θ(1)
|
O(1)*
|
Θ(1)
|
O(log n)
|
|
уменьшить ключ
|
Θ(log n)
|
Θ(log n)
|
Θ(1)*
|
O(1)*
|
Θ(1)
|
O(log n)
|
|
слияние
|
Θ(n)
|
O(log n)**
|
Θ(1)
|
O(1)*
|
Θ(1)
|
O(log n)
|
(*) Амортизационное время, (**) n — размер наибольшей кучи
Табл. 13
Анализ древовидных структур данных
Среди множества древовидных структур для использования в самоадаптирующихся ассоциативных контейнерах можно найти оптимальную структуру практически для любого случая. При выборе следует руководствоваться условиями задачи (подробный анализ представлен в [36]). Основным условием для выбора структуры является объем данных.
В случае, когда данные помещаются в память, можно использовать сбалансированные бинарные деревья, выбор которых необходимо осуществлять на основе многих факторов: сложность построения, дополнительная память, соотношение производительности вставки и удаления. Если в задаче используются многомерные данные, то можно использовать специальные деревья для предоставления многомерной информации [37]. Если имеется необходимость использовать контейнер как очередь с приоритетами или для решения задачи поиска минимума/максимума, то можно использовать кучу (любой вариант в зависимости от потребностей в эффективности и персистентности).
В случае, когда данные не помещаются в оперативную память и необходимо использовать внешнюю память, надо использовать другие деревья. Если используются многомерные данные, то необходимо использовать специальные деревья для предоставления многомерной информации с использованием внешней памяти [37].
В остальных случаях основной структурой данных является В-дерево (или его вариации в зависимости от необходимости последовательного доступа к ключам, дополнительной памяти и сложности реализации). При необходимости большого количества записей лучший выбор – использование деревьев, оптимизированных на запись (LSM-деревья, фрактальные и буферизированные).
Хеширование
Другим методом построения ассоциативных контейнеров является хеширование [38]. Идея хеширования используется во многих контейнерах данных, но самым используемым считается хеш-таблица. Этот контейнер реализует ассоциативный массив, причем индексы в нем определяются с использованием функции хеширования.
Временная сложность представлена в табл. 14.
|
Алгоритм
|
Среднее
|
Худший случай
|
|
Место
|
O(n)
|
O(n)
|
|
Поиск
|
O(1)
|
O(n)
|
|
Вставка
|
O(1)
|
O(n)
|
|
Удаление
|
O(1)
|
O(n)
|
Табл. 14
Основная идея данного метода построения заключается в том, чтобы сузить множество ключей, т. е. ключи, полученные в результате применения функции хеширования, имеют меньше уникальных значений, чем исходные ключи. Следовательно, хеш-коды могут совпадать при различных входных данных согласно принципу Дирихле. Ситуация, которая возникает при этом, называется коллизией. Коллизии значительно ухудшают производительность хеш-таблицы. Поэтому было создано несколько методов для борьбы с ними:
1. Метод цепочек. При использовании этого метода ячейка хеш-таблицы содержит указатель на голову списка из ключей, у которых хеш-коды одинаковы. Следовательно, при появлении коллизий список будет хранить несколько элементов вместо одного. Данное обстоятельство не изменяет время вставки в хеш-таблицу, так как время вставки в список то же – О(1). Зато ухудшается производительность поиска. Если все элементы хеш-таблицы будут содержаться в одном списке, оно будет достигать О(n). Существует модернизация данного метода, которая используется в Java8 для реализации HashMap, LinkedHashMap и ConcurrentHashMap. Основная идея в том, чтобы при определенном количестве элементов в ячейке хеш-таблицы использовать сбалансированное дерево вместо списка. Данное улучшение уменьшает время работы с O(n) до O(log(n)).
2. Линейное разрешение коллизий (метод открытой адресации). При использовании данного метода ячейка i массива H содержит непосредственно элемент, а не указатель на список. При попытке добавить элемент в занятую ячейку i начинается поиск следующей свободной ячейки по определенному правилу:
a. Последовательный поиск – просматриваются i + 1, i + 2 и т.д. ячейки.
b. Линейный поиск – выбирается некоторый шаг q и просматриваются i + (1*q), i + 2*q и т.д. ячейки.
c. Квадратичный поиск – просматриваются i + 1, i + 4, i + 9 и т.д. ячейки.
Данный метод отличается от метода цепочек тем, что все ячейки таблицы могут оказаться занятыми. Тогда может потребоваться увеличение размера и полное перестроение хеш-таблицы, что является очень трудоемкой операцией.
3. Двойное хеширование. Линейное разрешение коллизий имеет существенный недостаток – образование кластеров, т. е. последовательности пар «ключ-значение» в хеш-таблице, которую необходимо пройти при поиске. Следовательно, производительность поиска значительно снижается, так как кластер может содержать не только коллизии, но и элементы с абсолютно другим хеш-кодом. Для исключения данной ситуации вводится дополнительная хеш-функция h2(k), которая должна быть независима от h1(k). Тогда алгоритм поиска будет выглядеть следующим образом:
a. Поиск в ячейке h1(k).
b. Если она занята, производится поиск, пока не будет найдена свободная ячейка в ячейках (h1(k) + i * h2(k)) mod n для i = 0, 1, ..., n–1.
Данный метод позволяет избежать коллизий, идущих друг за другом в таблице и образующих кластеры, так как две независимые функции хеширования с низкой вероятностью выдадут одинаковые значения для разных ключей. Таким образом, несмотря на то, что временная сложность данного метода аналогична линейному апробированию, в среднем производительность данного метода на практике оказывается лучше.
4. Хеширование кукушки [39]. Данный метод позволяет достичь линейной скорости поиска в худшем случае. Для этого используются две хеш-функции h1 и h2. При вставке элемента x вычисляются h1(x) и h2(x). Если одна из ячеек свободна, то вставляется в нее. Если обе ячейки заняты, то выбирается любая из занятых ячеек и х добавляется в нее, а элемент из этой ячейки вставляется по аналогичному алгоритму. При этом может возникнуть зацикливание. В данном случае выбираются две новые хеш-функции и таблица перестраивается. Этот алгоритм работает эффективно при загрузке до 50%. Для того чтобы улучшить коэффициент загрузки, было создано несколько вариаций – использование трех хеш-функций, блочное кукушкино хеширование (больше первого элемента на ячейку), хеширование кукушки с запасом (дополнительная таблица для исключения циклов).
5. Идеальное хеширование [40]. Данный метод применяется тогда, когда известно множество всех ключей, т.е. оно неизменно. В этом случае можно использовать двухуровневое хеширование с помощью универсальных функций хеширования. При использовании данного метода хеш-таблица представляет собой таблицу из хеш-таблиц. Алгоритм поиска при идеальном хешировании выглядит следующим образом:
a. Случайным образом выбирается универсальная функция h из семейства Hp,m и вычисляется h(k) = ((a*k + b) mod p) mod n (p — простое число, p > n) и определяется ячейка, которая в свою очередь также содержит хеш-таблицу.
b. Выбирается универсальная функция hj из семейства Hp,mj и вычисляется адрес hj(k) = ((aj * k + bj) mod p) внутри хеш-таблицы, расположенной в j-й ячейке основной таблицы.
Идеальное хеширование позволяет достигнуть константной скорости поиска О(1).
6. Хеширование «Классики» (Hopscotch hashing) [41]. Данный алгоритм является модификацией алгоритма открытой адресации и позволяет хранить элемент только рядом с корзиной, в которую он должен попадать. Задается некоторое число H – максимальное расстояние, на котором может располагаться элемент от свой корзины. При вставке ищется свободная позиция для вставки. Если она попадает в H, то элемент вставляется, иначе ищется элемент из другой корзины, который можно сдвинуть вправо в пределах H, и так пока первичный элемент не попадет в Н. Если это невозможно, то таблицу необходимо увеличить и перехешировать. Для реализации быстрого поиска при сдвиге каждая ячейка хеш-таблицы хранит битовую карту из H соседних элементов, в которой отмечается, занято ли место элементами с одинаковым хеш-кодом. Такое хеширование позволяет избежать проблемы кластеризации, присущую методу открытой адресации, и улучшает производительность при большой заполненности таблицы.
Структуры данных, использующие хеширование
Хеш-таблица является самым распространенным контейнером, использующим хеширование, но помимо нее существует несколько других хешированных ассоциативных контейнеров. Ниже перечислены наиболее известные:
1. Фильтр Блума (англ. Bloom filter) [42]. Данная структура данных предназначена для проверки принадлежности элемента к множеству. Фильтр Блума содержит массив из m бит и несколько хеш-функций h1, ... hk. Когда фильтр не содержит ни одного элемента, то все биты нулевые. При добавлении элемента х вычисляются позиции h1(х)... hk(x), и на эти позиции выставляются единицы. При определении наличия элемента х вычисляются позиции h1(х)... hk(x). Элемент х возможно содержится в фильтре, только если на всех этих позициях в массиве стоят единицы, иначе элемента нет в множестве. Данная структура обычно занимает меньший объем памяти, чем хеш-таблица, но при этом жертвует детерминизмом. На практике фильтр Блума применяется для фильтрации запросов к внешней памяти или данным, передаваемым по сети во избежание дорогостоящих операций доступа. Фильтр Блума применяется в прокси-серверах, базах данных и некоторых программах проверки орфографии.
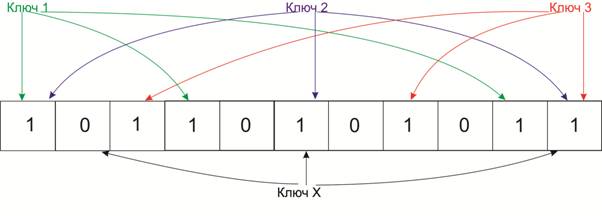
Рис. 18
Пример фильтра Блума, который содержит ключи 1,2 и 3. Цветные стрелки указывают на биты, которые выставляются при наличии соответствующего элемента. Также изображена проверка наличия ключа Х в фильтре.
2. Hash array mapped trie (HAMT) [43] — контейнер, который является объединением префиксного дерева и хеш-таблицы и обладает хорошей производительностью О(1). Hash array mapped trie содержит хеш-таблицу, содержащую 2t ячеек, где обычно t >= 5. Ячейка может содержать либо элемент, либо массив подтаблиц и битовую карту (обычно размером 32 бита). При этом вставка элемента происходит следующим образом:
a. вычисляется значение хеш-функции;
b. из получившегося хеша берем старшие t бит и по ним определяем индекс в главной таблице;
c. если в ячейке нет данных, кладем туда ключ-значение, иначе:
i. если в ячейке только одно ключ-значение, заменяем его на ссылку на подтаблицу и битовую карту размера 32, берем следующие 5 бит от хеша нового и старого ключа в текущей ячейке. Устанавливаем в карте по порядку те биты, которые соответствуют десятичному представлению текущих 5 бит у нового и старого хеша (например, 27-й бит устанавливается, если часть хеша равна 11011). Далее создаем подтаблицу с двумя элементами и кладем в них старое и новое ключ-значение.
ii. если в ячейке уже есть подтаблица, то необходимо взять следующие 5 бит от хеша вставляемого значения, установить в битовой карте бит и выбрать ячейку из подтаблицы по правилу: номер ячейки = количеству установленных битов до номера равному десятичному представлению текущих 5 бит. Далее текущий шаг повторяется до тех пор, пока не будет достигнут последний бит в хеше. Если данная ячейка окажется опять занятой (т.е. хеши у нового и старого ключа полностью совпали), то используется дополнительная хеш-функция и подтаблицы.
HAMT применяется для реализации персистентных структур данных в функциональных языках, таких как Scala, Clojure, Haskell и другие. Модификация данного дерева CTrie используется для потокобезопасной реализации словаря.
Анализ хешированных ассоциативных контейнеров
Основным преимуществом данных контейнеров является очень хорошая средняя скорость операций О(1), что гораздо лучше, чем у деревьев O(log n). Однако хешированные контейнеры имеют недостатки, связанные с внутренним устройством:
1. Невозможно итерировать объекты в порядке увеличения/уменьшения ключей, а следовательно, невозможно эффективно реализовать операции поиска минимума/максимума и хранить данные в упорядоченном виде.
2. Плохая временная сложность худшего случая. Например, в реализациях хеш-таблиц, которые используют полную перестройку таблицы при изменении размера, вставка и удаление имеют сложность до О(n). Кроме того, большое количество коллизий может привести к тому, что может потребоваться перебор большого количества элементов.
Таким образом, хешированные контейнеры стоит использовать для приложений, где изначально можно предсказать количество элементов, что позволит выделить под таблицу необходимую память и не перестраивать ее впоследствии. Кроме того, хеш-таблицы не стоит использовать в приложениях, где необходима гарантированная средняя стоимость операций. А также они плохо подходят для использования в определенных приложениях для работы со строками таких, как приложения для проверки орфографии (для них лучше подходят деревья и конечные автоматы).
Следовательно, использование хеш-таблиц в самоадаптирующихся контейнерах данных может быть целесообразно в случаях, когда данные долгое время используются для поиска и очень редко для вставки и удаления. Кроме того, необходимо учитывать, что при перестроении требуется выбрать подходящую хеш-функцию и размер хеш-таблицы, что в общем случае – сложная задача. Фильтр Блума может использоваться в данных контейнерах в первую очередь как дополнительная модификация (для уменьшения количества запросов к самому контейнеру). HAMT может использоваться в самоадаптирующихся контейнерах как альтернатива хеш-таблицам для экономии занимаемого места и во избежание перехеширования таблицы.
Заключение
В данной статье рассмотрены методы построения контейнеров данных «ключ-значение» и представлен обзор таких контейнеров. В табл. 15 отображены основные области использования этих контейнеров на практике. В результате анализа ассоциативных контейнеров были выявлены сферы применения контейнеров при реализации самоадаптирующихся ассоциативных контейнеров данных.
|
Контейнер
|
Области использования
|
|
SSTable
|
NoSQL СУБД (Cassandra, HBase и LevelDB).
|
|
АВЛ-дерево
|
Высокоэффективные алгоритмы сортировки и поиска (подсистема управления памятью ОС Linux), шахматные програмы, искуственный интеллект.
|
|
Красно-черное дерево
|
Высокоэффективные алгоритмы сортировки и поиска (ядро ОС Linux, файловая система ext3), реализация set и map.
|
|
Декартово дерево
|
Сбор статистики по большому числу параметров.
|
|
Splay-дерево
|
Эффективная обработка часто повторяющихся запросов (сетевые маршрутизаторы, кеш, ОС Windows NT, gcc компилятор и GNU C++ библиотека).
|
|
Scapegoat-дерево
|
Работа с многомерными объектами (k-d дерево, квадродерево, ортогональные запросы).
|
|
Б+ дерево
|
Файловые системы для хранения каталогов и индексирования метаданных (NTFS, BeFS и другие), реляционные СУБД – в качестве индекса (Oracle, SQLite и другие), NoSQL базы данных – для доступа к данным (CouchDB).
|
|
Б* дерево
|
Файловые системы для хранения каталогов и индексирования метаданных (HFS+, Microsoft's NTFS, AIX (jfs2), btrfs, Ext4), реляционные СУБД – в качестве индекса (PostgreSQL, MySQL), NoSQL базы данных – в качестве индекса (MongoDB).
|
|
2-3-4-дерево
|
Хранение словарей во внутренней памяти.
|
|
Буферизированное дерево
|
Очередь с приоритетами, range и segment деревья, алгоритм сортировки.
|
|
Bε–дерево
|
СУБД TokuDB и файловая система BetrFS.
|
|
Buffered Repository tree
|
Обход графа в ширину и глубину, СУБД TokuDB.
|
|
LSM-дерево
|
Хранение данных в СУБД (BigTable, HBase, LevelDB, MongoDB, SQLite4, RocksDB, WiredTiger, Apache Cassandra и InfluxDB, Tarantool).
|
|
Фрактальное дерево
|
Индексы в СУБД TokuDB и TokuMX, файловые системы TokuFS и BetrFS.
|
|
Куча
|
Пирамидальная сортировка, приоритетная очередь (библиотеки Java, C++, PHP, Python и др., планировщики задач в различных ОС, сетевые маршрутизаторы), алгоритмы на графах (алгоритм Дейкстры, Хаффмана и Прайма), поиск минимума/максимума.
|
|
Хеш-таблица
|
Реализация ассоциативного массива и set (Java, Perl, Ruby, Python, PHP и др.), индексы и хранение данных в СУБД (MySQL,Oracle,MS SQL, Memcached, MemcacheDB, REDIS, Tarantool и многие другие), кэши.
|
|
Фильтр Блума
|
Прокси сервер Squid, браузер Chrome, проверка существования записи в СУБД (BigTable, Apache HBase, Apache Cassandra, Postgresql, Oracle, RocksDB), криптовалюта Bitcoin, веб-сервер Akamai, программы проверки орфографии.
|
|
Hash array mapped trie
|
Реализация персистентных структур данных (Scala, Clojure, Haskell и другие), проверка целостности в файловых системах (IPFS, Btrfs,ZFS), протоколы (Bittorent, Dat, Apache Wave), криптовалюты Bitcoin и Ethereum, СУБД (Apache Cassandra, Riak, Dynamo).
|
Табл. 15
Библиография
1. Мюссер Д., Дердж Ж., Сейни А. C++ и STL. Справочное руководство. 2-е изд. М.: Вильямс, 2010. 430 с.
2. Садаладж П. Дж., Фаулер М. NoSQL: Новая методология разработки нереляционных баз данных. М.: Вильямс, 2013. 172 с.
3. SSTable & LSM-Tree [Электронный реcурс]. Режим доступа: http://www.mezhov.com/2013/09/sstable-lsm-tree.html. – Заглавие с экрана (дата обращения: 23.06.2017).
4. Carpenter J., Hewitt E. Cassandra: The Definitive Guide, 2nd Edition. NY: O'Reilly Media, 2016. 360p.
5. Исламов А. Ш., Артемов М. А., Барановский Е. С., Киргинцев М. В. Обработка больших объемов данных на основе MapReduce // Информатика: проблемы, методология, технологии. Материалы XV международной научно-методической конференции. Воронеж: ВГУ, 2015. C. 78–80.
6. SSTable and Log Structured Storage: LevelDB [Электронный реcурс]. Режим доступа: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb. Заглавие с экрана (дата обращения: 23.06.2017).
7. Зобов В. В., Селезнев К. Е. Инструмент для моделирования нагрузки на контейнеры данных // Материалы четырнадцатой научно-методической конференции «Информатика: проблемы, методология, технологии», 10-11 февраля 2011 г. Воронеж: ВГУ, 2014. Т. 3. С. 154–161.
8. Ахо А. В., Хопкрофт Д. Э., Ульман Д. Д. Структуры данных и алгоритмы. М.: Вильямс, 2003. 382 с.
9. Кормен Т. Х. [и др.] Алгоритмы: построение и анализ. 2-е изд. М.: Издательский дом «Вильямс», 2005. 1296 с.
10. Топп У., Форд У. Структуры данных в C++. М.: Бином, 2000. 815 с.
11. Вирт H. Алгоритмы + структуры данных = программы. М.: Мир, 1985. 406 с.
12. Структуры данных: бинарные деревья. Часть 2: обзор сбалансированных деревьев [Электронный реcурс]. Режим доступа: https://habrahabr.ru/post/66926/. Заглавие с экрана (дата обращения: 23.06.2017).
13. Кнут Д. Э. Искусство программирования для ЭВМ. Т. 1 : Основные алгоритмы. М.: Мир, 1976. 736 с.
14. Седжвик Р. Фундаментальные алгоритмы на Java. Ч. 1 – 4: Анализ. Структуры данных. Сортировка. Поиск. Киев: ДиаСофт, 2002. 688 с.
15. Aragon C. R., Seidel R. Randomized Search Trees // Proc. 30th Symp. Foundations of Computer Science. Washington, D.C.: IEEE Computer Society Press, 1989. P. 540–545.
16. Sleator D. D., Tarjan R. E. Self-Adjusting Binary Search Trees // Journal of the ACM. 1985. № 32. P. 652–686.
17. Andersson A. Improving partial rebuilding by using simple balance criteria // Proc. Workshop on Algorithms and Data Structures. Berlin: Springer-Verlag, 1989. P. 393–402.
18. Левитин А. В. Алгоритмы. Введение в разработку и анализ. М.: Вильямс, 2006. 576 с.
19. Зубов В. С., Шевченко И. В. Структуры и методы обработки данных. Практикум в среде Delphi. М.: Филинъ, 2004. 304 c.
20. Berliner H. The B* Tree Search Algorithm. A Best-First Proof Procedure // Artificial Intelligence. 1979. № 12. P. 23–40.
21. Arge L. The buffer tree: a new technique for optimal I/O-algorithms // In Proc. Workshop on Algorithms and Data Structures. Berlin: Springer-Verlag, 1995. P. 334–345.
22. Bender M., Farach-Colton M., Jannen W, Johnson R., Kuszmaul B. C., Porter D. E., Yuan J., Zhan Y. An Introduction to Bε-Trees and Write-Optimization // In: login; magazine. 2015. Vol. 40. No 5. P. 22–28.
23. Buchsbaum A. L., Goldwasser M., Venkatasubramanian S., Westbrook J. R. On external memory graph traversal // In Proceedings of the Eleventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’00). Philadelphia: Society for Industrial and Applied Mathematics, 2000. P. 859–860.
24. O’Neil P. E., Cheng E., Gawlick D., O’Neil E. J. The log-structured merge-tree (LSM-tree) // Acta Informatica. 1996. Vol. 33, No. 4. P. 351–385.
25. Sears R., Ramakrishnan R. bLSM: a general purpose log structured merge tree // In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. NY: ASM, 2012. P. 217–228.
26. Tan W., Tata S., Tang Y., Fong L. Diff-Index: Differentiated Index in Distributed Log-Structured Data Stores // In Proceedings of the 17th International Conference on Extending Database Technology, EDBT. Konstanz, Germany: OpenProceedings.org, 2014. P. 700–711.
27. LevelDB [Электронный реcурс]. Режим доступа: http://leveldb.org. – Заглавие с экрана (дата обращения: 23.06.2017).
28. Bender M. A., Farach-Colton M., Fineman J., Fogel Y., Kuszmaul B., Nelson J. Cache-Oblivious streaming B-trees // Proceedings of the 19th Annual ACM Symposium on Parallelism in Algorithms and Architectures. CA: ACM Press, 2007. P. 81–92.
29. Алексеев В. Е., Таланов В. А. Графы и алгоритмы. Структуры данных. Модели вычислений. М.: Интернет Ун-т Информ. Технологий: БИНОМ, 2006. 320 с.
30. Т. Х. Кормен [и др.]. Алгоритмы: построение и анализ = Introduction to Algorithms. М.: Вильямс, 2005. 1296 с.
31. Fredman M. L., Tarjan R. E. Fibonacci heaps and their uses in improved network optimization algorithms // Journal of the Association for Computing Machinery. 1987. Vol. 34, No. 3. P. 596–615.
32. Kaplan H., Tarjan R. E. Thin heaps, thick heaps // ACM Transactions on Algorithms (TALG). 2008. Vol. 4, Article No. 3. P. 1–14.
33. Crane C. A. Linear lists and priority queues as balanced binary trees. Stanford: Stanford University, 1972.
34. Takaoka T. Theory of 2-3 Heaps // Discrete Applied Math. 2003. Vol. 126. P. 115–128.
35. Brodal G. S., Okasaki C. Optimal purely functional priority queues // Journal of Functional Programming. 1996. Vol. 6. P. 839–857.
36. Потапов Д. Р., Артемов М. А., Барановский Е. С. Обзор условий адаптации самоадаптирующихся ассоциативных контейнеров данных // Вестник Воронежского государственного университета. Серия: Системный анализ и информационные технологии. 2017. № 1. С. 112–119.
37. Гулаков В. К., Трубаков А.О. Многомерные структуры данных. Брянск: БГТУ, 2010. 387 с.
38. Кнут Д. Искусство программирования. Т. 3. Сортировка и поиск / Д. Кнут. 2-е издание. М.: «Вильямс», 2007. С. 824.
39. Pagh R., Flemming F. R. Cuckoo Hashing // Journal of Algorithms. 2004. Vol. 51. P. 122–144.
40. Fredman M. L., Komlos J., Szemeredi E. Storing a Sparse Table with O(1) Worst Case Access Time // Journal of the ACM. 1984. Vol. 31. No. 3. P. 538–544.
41. Herlihy M., Shavit N., Tzafrir M. Hopscotch Hashing // Proceedings of the 22nd international symposium on Distributed Computing. Arcachon, France: Springer-Verlag, 2008. P. 350–364.
42. Фильтр Блума [Электронный реcурс]. Режим доступа: https://ru.wikipedia.org/wiki/Фильтр_Блума. Заглавие с экрана (дата обращения: 23.06.2017).
43. Hash array mapped trie [Электронный реcурс]. Режим доступа: https://habrahabr.ru/post/266861/. Заглавие с экрана (дата обращения: 23.06.2017)
References
1. Myusser D., Derdzh Zh., Seini A. C++ i STL. Spravochnoe rukovodstvo. 2-e izd. M.: Vil'yams, 2010. 430 s.
2. Sadaladzh P. Dzh., Fauler M. NoSQL: Novaya metodologiya razrabotki nerelyatsionnykh baz dannykh. M.: Vil'yams, 2013. 172 s.
3. SSTable & LSM-Tree [Elektronnyi recurs]. Rezhim dostupa: http://www.mezhov.com/2013/09/sstable-lsm-tree.html. – Zaglavie s ekrana (data obrashcheniya: 23.06.2017).
4. Carpenter J., Hewitt E. Cassandra: The Definitive Guide, 2nd Edition. NY: O'Reilly Media, 2016. 360p.
5. Islamov A. Sh., Artemov M. A., Baranovskii E. S., Kirgintsev M. V. Obrabotka bol'shikh ob''emov dannykh na osnove MapReduce // Informatika: problemy, metodologiya, tekhnologii. Materialy XV mezhdunarodnoi nauchno-metodicheskoi konferentsii. Voronezh: VGU, 2015. C. 78–80.
6. SSTable and Log Structured Storage: LevelDB [Elektronnyi recurs]. Rezhim dostupa: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb. Zaglavie s ekrana (data obrashcheniya: 23.06.2017).
7. Zobov V. V., Seleznev K. E. Instrument dlya modelirovaniya nagruzki na konteinery dannykh // Materialy chetyrnadtsatoi nauchno-metodicheskoi konferentsii «Informatika: problemy, metodologiya, tekhnologii», 10-11 fevralya 2011 g. Voronezh: VGU, 2014. T. 3. S. 154–161.
8. Akho A. V., Khopkroft D. E., Ul'man D. D. Struktury dannykh i algoritmy. M.: Vil'yams, 2003. 382 s.
9. Kormen T. Kh. [i dr.] Algoritmy: postroenie i analiz. 2-e izd. M.: Izdatel'skii dom «Vil'yams», 2005. 1296 s.
10. Topp U., Ford U. Struktury dannykh v C++. M.: Binom, 2000. 815 s.
11. Virt H. Algoritmy + struktury dannykh = programmy. M.: Mir, 1985. 406 s.
12. Struktury dannykh: binarnye derev'ya. Chast' 2: obzor sbalansirovannykh derev'ev [Elektronnyi recurs]. Rezhim dostupa: https://habrahabr.ru/post/66926/. Zaglavie s ekrana (data obrashcheniya: 23.06.2017).
13. Knut D. E. Iskusstvo programmirovaniya dlya EVM. T. 1 : Osnovnye algoritmy. M.: Mir, 1976. 736 s.
14. Sedzhvik R. Fundamental'nye algoritmy na Java. Ch. 1 – 4: Analiz. Struktury dannykh. Sortirovka. Poisk. Kiev: DiaSoft, 2002. 688 s.
15. Aragon C. R., Seidel R. Randomized Search Trees // Proc. 30th Symp. Foundations of Computer Science. Washington, D.C.: IEEE Computer Society Press, 1989. P. 540–545.
16. Sleator D. D., Tarjan R. E. Self-Adjusting Binary Search Trees // Journal of the ACM. 1985. № 32. P. 652–686.
17. Andersson A. Improving partial rebuilding by using simple balance criteria // Proc. Workshop on Algorithms and Data Structures. Berlin: Springer-Verlag, 1989. P. 393–402.
18. Levitin A. V. Algoritmy. Vvedenie v razrabotku i analiz. M.: Vil'yams, 2006. 576 s.
19. Zubov V. S., Shevchenko I. V. Struktury i metody obrabotki dannykh. Praktikum v srede Delphi. M.: Filin'', 2004. 304 c.
20. Berliner H. The B* Tree Search Algorithm. A Best-First Proof Procedure // Artificial Intelligence. 1979. № 12. P. 23–40.
21. Arge L. The buffer tree: a new technique for optimal I/O-algorithms // In Proc. Workshop on Algorithms and Data Structures. Berlin: Springer-Verlag, 1995. P. 334–345.
22. Bender M., Farach-Colton M., Jannen W, Johnson R., Kuszmaul B. C., Porter D. E., Yuan J., Zhan Y. An Introduction to Bε-Trees and Write-Optimization // In: login; magazine. 2015. Vol. 40. No 5. P. 22–28.
23. Buchsbaum A. L., Goldwasser M., Venkatasubramanian S., Westbrook J. R. On external memory graph traversal // In Proceedings of the Eleventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’00). Philadelphia: Society for Industrial and Applied Mathematics, 2000. P. 859–860.
24. O’Neil P. E., Cheng E., Gawlick D., O’Neil E. J. The log-structured merge-tree (LSM-tree) // Acta Informatica. 1996. Vol. 33, No. 4. P. 351–385.
25. Sears R., Ramakrishnan R. bLSM: a general purpose log structured merge tree // In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. NY: ASM, 2012. P. 217–228.
26. Tan W., Tata S., Tang Y., Fong L. Diff-Index: Differentiated Index in Distributed Log-Structured Data Stores // In Proceedings of the 17th International Conference on Extending Database Technology, EDBT. Konstanz, Germany: OpenProceedings.org, 2014. P. 700–711.
27. LevelDB [Elektronnyi recurs]. Rezhim dostupa: http://leveldb.org. – Zaglavie s ekrana (data obrashcheniya: 23.06.2017).
28. Bender M. A., Farach-Colton M., Fineman J., Fogel Y., Kuszmaul B., Nelson J. Cache-Oblivious streaming B-trees // Proceedings of the 19th Annual ACM Symposium on Parallelism in Algorithms and Architectures. CA: ACM Press, 2007. P. 81–92.
29. Alekseev V. E., Talanov V. A. Grafy i algoritmy. Struktury dannykh. Modeli vychislenii. M.: Internet Un-t Inform. Tekhnologii: BINOM, 2006. 320 s.
30. T. Kh. Kormen [i dr.]. Algoritmy: postroenie i analiz = Introduction to Algorithms. M.: Vil'yams, 2005. 1296 s.
31. Fredman M. L., Tarjan R. E. Fibonacci heaps and their uses in improved network optimization algorithms // Journal of the Association for Computing Machinery. 1987. Vol. 34, No. 3. P. 596–615.
32. Kaplan H., Tarjan R. E. Thin heaps, thick heaps // ACM Transactions on Algorithms (TALG). 2008. Vol. 4, Article No. 3. P. 1–14.
33. Crane C. A. Linear lists and priority queues as balanced binary trees. Stanford: Stanford University, 1972.
34. Takaoka T. Theory of 2-3 Heaps // Discrete Applied Math. 2003. Vol. 126. P. 115–128.
35. Brodal G. S., Okasaki C. Optimal purely functional priority queues // Journal of Functional Programming. 1996. Vol. 6. P. 839–857.
36. Potapov D. R., Artemov M. A., Baranovskii E. S. Obzor uslovii adaptatsii samoadaptiruyushchikhsya assotsiativnykh konteinerov dannykh // Vestnik Voronezhskogo gosudarstvennogo universiteta. Seriya: Sistemnyi analiz i informatsionnye tekhnologii. 2017. № 1. S. 112–119.
37. Gulakov V. K., Trubakov A.O. Mnogomernye struktury dannykh. Bryansk: BGTU, 2010. 387 s.
38. Knut D. Iskusstvo programmirovaniya. T. 3. Sortirovka i poisk / D. Knut. 2-e izdanie. M.: «Vil'yams», 2007. S. 824.
39. Pagh R., Flemming F. R. Cuckoo Hashing // Journal of Algorithms. 2004. Vol. 51. P. 122–144.
40. Fredman M. L., Komlos J., Szemeredi E. Storing a Sparse Table with O(1) Worst Case Access Time // Journal of the ACM. 1984. Vol. 31. No. 3. P. 538–544.
41. Herlihy M., Shavit N., Tzafrir M. Hopscotch Hashing // Proceedings of the 22nd international symposium on Distributed Computing. Arcachon, France: Springer-Verlag, 2008. P. 350–364.
42. Fil'tr Bluma [Elektronnyi recurs]. Rezhim dostupa: https://ru.wikipedia.org/wiki/Fil'tr_Bluma. Zaglavie s ekrana (data obrashcheniya: 23.06.2017).
43. Hash array mapped trie [Elektronnyi recurs]. Rezhim dostupa: https://habrahabr.ru/post/266861/. Zaglavie s ekrana (data obrashcheniya: 23.06.2017)
|
 Рус
Рус










