|
Litera
Правильная ссылка на статью:
Борунов А.Б.
Разнообразие речи и методы его измерения в тексте (лингвостатистический подход)
// Litera.
2017. № 4.
С. 81-86.
DOI: 10.25136/2409-8698.2017.4.20751 URL: https://nbpublish.com/library_read_article.php?id=20751
Разнообразие речи и методы его измерения в тексте (лингвостатистический подход)
Борунов Артем Борисович
ORCID: 0000-0003-2507-7218
кандидат филологических наук
доцент кафедры романо-германских языков
Московский государственный гуманитарно-экономический университет
107150, Россия, г. Москва, ул. Лосиноостровская, 49
Borunov Artem Borisovich
PhD in Philology
Associate Professor of the Department of Romano-Germanic Languages
Moscow State University of Humanities and Economics
107150, Russia, g. Moscow, ul. Losinoostrovskaya, 49

|
borunov.artem@yandex.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.25136/2409-8698.2017.4.20751
Дата направления статьи в редакцию:
16-10-2016
Дата публикации:
16-01-2018
Аннотация:
В данной статье рассматриваются особенности использования статистических методов для проведения лингвистических исследований, объектом которых является естественный язык. Основной целью статьи является описание основных методов лингвостатистичеcкого исследования, служащих критерием разнообразия речи в тексте. Данный положения могут быть использованы в исследованиях как русского, так и иностранного языков для выявления и доказуемости при помощи статистических моделей и формул стилистического разнообразия речи. Описываемый лингвостатистический анализ дополнит традиционный лингвостилистический анализ. Методологией исследования явился анализ научной литературы в области данной проблематики, описательный метод и метод деструктивного анализа. В работе представлены краткие, но логически обоснованные, формулы разнообразия речи, которые также принято назвать - коэффициентами разнообразия. Кроме того, в статье представлена методика проведения исследования стилистического разнообразия как звучащей речи, так и письменного текста, описание результатов при помощи математических формул, позволяющих выявить коэффициенты разнообразия речи.
Ключевые слова:
математический подход, лингвостатистический подход, богатство речи, коэффициенты разнообразия речи, лексическое разнообразие, синтаксическое разнообразие, стандартная величина коэффициентов, лингвостатистический анализ, квантитативная лингвистика, лингвостилистика
УДК: 81.139
Abstract: This article is devoted to particularities of using statistical methods in linguistic researches of natural language. The main purpose of the research is to describe the main methods of linguostatistical research that serve as criteria for speech variety in a text. The provisions of this research can be used in future research of both Russian and foreign languages to define and prove stylistic variety of speech using statistical models and formulas. The linguostatistical analysis described in this research completes traditional linguostylistic analysis. The methodology of this research involves analysis of research literature on the matter, descriptive method and destructive analysis method. The research provides brief but logically grounded formulas of speech variety that are usually called variety oefficients. In addition, the article presents the method of stylistic variety of both verbal utterance and written text as well as the method that describe results using mathematical formulas that define speech variety coefficients.
Keywords: mathematical approach, linguostatistical approach, richness of speech, diversity of speech coefficients, lexical diversity, syntactic variety, standard value of the coefficients, linguostatistical analysis, quantitative linguistics, linguostylistics
В данной статье предполагается рассмотреть с позиции лингвостатистики такое понятие как «разнообразие речи», о котором упоминают в различных научных статьях. Как известно, в современной науке разнообразие речи изучается стилистикой, которая имеет дело с выразительными средствами языка, коннотациями лексических единиц и функциональными стилями. Исследований стилистического разнообразия речи с позиций лингвостилистики, стилистики декодирования и литературоведческой стилистики довольно много, однако, необходимо подметить, что есть определенные лакуны в данной научной сфере, которые не могут быть полностью восполнены данными, полученными стилистическими методами. Результаты, полученные в ходе лингвостатистических исследований, которые, благодаря математическим методам, позволяют наглядно проиллюстрировать теоретические положения и восполнить имеющиеся лакуны в данной сфере лингвистического знания.
Прежде всего, следует начать с определения сути науки «лингвостатистика» (или статистическая лингвистика), которая является дисциплиной, изучающей закономерности количественного характера на основе естественного языка. Учитывая относительно недавнее вхождение компьютера в нашу жизнь, который, несомненно, является незаменимым инструментом для исследователя в данной области, отметим, что лингвостатистика является молодой наукой. Интерес к данной науке возник с появлением первых ЭВМ, которые облегчали труд исследователя по машинному подсчету слов в тексте и могли оперативно обрабатывать и анализировать большие объёмы информации. Сегодня с масштабным вхождением компьютерных технологий в нашу жизнь (а без компьютера, в наши дни, навряд ли себя может представить любой учёный) интерес к лингвостилистике (в настоящее время ученые все чаще оперируют термином «квантитативная лингвистика») и математической лингвистике неуклонно возрастает, так как персональный компьютер и разаботанное специализированное программное обеспечение (к примеру, WordSmith Tools – частотный анализ корпуса, WordStat – статистика слов, Vaal-mini 1.5 – анализатор текста, Fresh Eye версия 1.21 – утилита для стилистической проверки текстов и ряд других) помогают за несколько минут автоматизировано обработать любой текст, составить алфавитно-частотный список лексических единиц, рассмотреть индивидуальные особенности авторского текста и выполнить другие запросы пользователя.
Напомним, что основой квантитативной лингвистики составляет предположение о том, что «…некоторые числительные характеристики и функциональные зависимости между ними, которые были получены для ограниченной совокупности текстов, характеризуют язык как некий целый объект, а также его основные функциональные стили» [6].
Говоря о методологии исследования, отметим, что в квантитативной лингвистике используются статистические методы, которые направлены на выявление и описание произведений речи и структуры языка и помогают устанавливать общие статистические законы, которые можно применять к языку, его динамике и статике [2, с. 210]. Среди данных методов различаются квалитативные (количественные) и квантитативные (качественные) методы. В настоящее время эти методы являются достаточно популярными, так как оба метода могут быть использованы в лингвистическом исследовании, выступая в качестве одного единственного инструмента измерения языковых единиц, также они способны образовывать некий симбиоз, что повышает продуктивность получаемых заключений. При этом количественные (квантитативные) методы играют роль аппаратов разрешительного характера, то есть, количественные методы занимаются разрешением любых вопросов, непосредственно относящихся к виду функционирования языковой деятельности.
Для более глубокого рассмотрения вышеупомянутых методов обратимся к истории языкознания. Как известно, точкой отсчета появления и существования в лингвистике количественных методов в актуальном понимании исконно принято считать начало двадцатого века. Именно XX век связан с оформлением данной области лингвистики как науки, обращающей «повышенное внимание к структурным особенностям языка, а язык, как известно, всегда был приоритетной зоной применения количественных критериев» [1].
Выдающийся психолог Л. С. Выготский в своей книге «Мышление и речь» еще в 1934 году, отмечал, что «первым, кто увидел в математике мышление, происходящее из языка, но преодолевающее его, был, по-видимому, Декарт» [4, с. 23]. Таким образом, очевидно, что учёные задумывались над использованием математических методов при изучении языка еще задолго до появления первых ЭВМ.
Следующей вехой в развитии лингвостатистики был период XIX и XX вв. В данный период ряд ученых стал пользоваться математическими и количественными методами в своих работах, где требовалось лингвистическое описание терминов, различных понятий и суждений. К таким ученых следует относить русских математиков В. Я. Буняковского и А. А. Маркова, британца Дж. Юла и немца Э. Форстеманна. По словам В. А. Звегинцева, «…все эти ученые рассматривали в своих исследованиях языковые элементы как самый полезный иллюстрированный материал, который сам по себе помогает строить квантитативные методы, или, даже, статистические теоремы. При всем многообразии формы лингвистического анализа, результаты статистических исследований, казалось, совершенно не учитывали тот факт, что полученные выводы можно применить к лингвистике» [5, с. 115].
В свою очередь А. Росс пришел к выводу, что подходящим аппаратом для этого является математическая статистика и теория вероятностей. В данный момент времени принято называть этот аппарат математической моделью, которая способна проверять и подтверждать такие лингвистические заключения, допускающие цифровую трактовку.
Как известно богатство и разнообразие речи являются высшими уровнями владения языком носителем. Разнообразие становится богатством языка, как только сам язык начинает наполняться средствами, необходимыми для выражения содержательной информации. Такое наполнение языка возможно благодаря способности языка взаимодействовать с сознанием человека. Также следует подчеркнуть наличие опыта прошлых поколений, так или иначе, базируется на речи и сознании человека. Соотношение сознания с речью связано с экстралингвистическими компонентами, в данном случае чувствами, мыслями, эмоциями, которыми человек наполняет свою речевую деятельность. По этой причине, выбор языковых элементов как способов выражения зависят от сознания человека, его темперамента и характера. Именно работа сознания человека является основополагающим процессом для зарождения информативного и лексически наполненного текста высказывания.
Современные методы оценки богатства языка, языкового разнообразия, в пределах того или иного фрагмента текста, опираются на интуицию исследователя, что естественно подразумевает под собой некий субъективизм оценки текста. С подобным субъективизмом и помогают частично справиться объективные статистические данные, полученные в ходе квантитативного исследования, что справедливо отмечает в своих работах А. П. Варфоломеев: «такие попытки как применение объективных, опирающихся на количественные (лингвостатистические) меры способов характеризации этой стороны речи, да и то эти попытки носят не практический, а декларативный (предполагающий решение проблемы, но не реализующийся) характер, причем отдельно по разным языковым уровням, без комплексного обобщения» [7, с. 27].
Использование математических формул позволяет лингвистам прийти к коэффициентам речевого разнообразия речи, которые также принято называть коэффициентом словарного разнообразия. Наличие данного коэффициента свидетельствует о существовании отличительных черт вербального интеллекта.
Таким образом, существуют два вида корреляционных связей: прямая корреляционная связь и отрицательная корреляционная связь. Поясним, что корреляционная связь – это такая связь, при которой каждому определенному значению одного признака соответствует несколько значений другого взаимосвязанного с ним признака. Данный коэффициент ученые вычисляют по формуле:
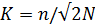 , ,
где n – это количество разных знаменательных слов в тексте, отрывке разговора (в данном случае разговор будет принят за фонотекст);
N – это число всех слов.
В данном случае существует зависимость, заключающаяся в следующем положении «чем больше коэффициент разнообразия, тем выше уровень ее выразительности и уникальности и наоборот». Такая речь очень редко рождается в результате импровизационных моментов. Такая речь не режет слух, и она всегда приветствуется на важных собраниях, официальных выступлениях, темы всегда интересны и языковые единицы подобраны с точки зрения стилистических особенностей. Речь, коэффициент разнообразия которой имеет значение выше среднего, свидетельствует о высоком интеллекте говорящего.
Таким образом, «расчет коэффициента речевого разнообразия должен предполагать взаимосвязь, как минимум, двух параметров: лексического разнообразия и степени синтаксической сложности. На этих уровнях легко достигнуть формальной соотносимости коэффициентов» [7, с. 27].
«Лексическое разнообразие» или «лексическое богатство» языка более устоявшийся термин в отечественной лингвистике, в который заложен основной смысл понятие «богатство», т.е. особая выразительность, синонимия и т.п., всё то, что не дает одному языку потеряться наравне с другими языками. Любое слово подчиняется стилю текста, в состав которого оно входит, например, стилистически маркированная лексика, например, книжная.
В понятие лексическое своеобразие заложено также положение свидетельствующее о существовании нескольких значений одного и того же слова или полисемия. Кроме второстепенных значений, лексика может быть стилистически маркированной или нейтральной.
Коэффициент лексического разнообразия речи формируется из отношения числа лексем к общему числу слов текста, а именно:
Клекс = Л / С,
где Клекс - это коэффициент лексического разнообразия;
Л - число лексем в данном тексте;
С - общее число слов этого текста;
Таким образом, значения данной формулы располагаются в промежутке от 0 до 1. Чем больше получаемая десятичная дробь, тем выше лексическое разнообразие [6, с. 27].
По словам Ирины Борисовны Голуб, «не следует считать, что экспрессивная окраска речи свойственна лишь разговорному и просторечному синтаксису, и возможна только в сниженной речи» [3, с. 432].
Коэффициент синтаксического разнообразия в данном случае вытекает из отношения числа предложений к числу слов данного текста.
Ксинт = 1 - П/С,
где Ксинт – это коэффициент сложности конструкции;
П - число предложений;
С - число слов во всем тексте.
Пограничными значениями в расчете синтаксического коэффициента будут значения от 0 до 1. Чем больше дробь, тем предложения данного текста многословнее, разнообразнее, следовательно, выше наполненность текста этими синтаксическими отношениями между словами в составе отдельного предложения.
Согласно А. П. Варфоломееву, «официальных стандартов для коэффициентов разнообразия речи не существует». К числу стандартов разнообразия принято относить: лексическое разнообразие речи, синтаксический уровень разнообразия [2, с. 28].
Однако, А. П. Варфоломеев утверждает, что в роли «…оценки какого либо текста в однородной группе текстов вполне может служить среднестатистическая норма величины коэффициента для равных по длине отрывков» [2, с. 28].
Так оптимальный размер (длина) отрывка – 100 слов. Это идеальное количество слов для проведения группового исследования, так как написания 100-160 слов не требует много времени каждого конкретного человека. «Показателем нормы здесь является среднеарифметическая величина коэффициента (лексический, синтаксический) в блоке текстов (их отрывки одинаковой величины). Близость или удаленность отдельного индивидуального коэффициента от среднего служит основанием для вынесения оценки разнообразия речи в соответствующем тексте» [2, с. 28].
Таким образом, получается, удовлетворительными результатами исследования являются коэффициенты разнообразия, которые попадают в интервал стандартных отклонений отданной формы.
Стандартное отклонение рассчитывают по формуле:
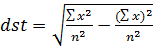 , ,
где dst – стандартное отклонение (как в большую, так и в меньшую сторону) от средней;
x – каждый отдельный коэффициент данной совокупности;
n – общее число коэффициентов (текстов).
Пределы зоны стандартных отклонений вычисляются как промежуток в пределах: [6, с. 28]
x±dst.
Подводя итог, следует подчеркнуть тот факт, что лингвостатистические методы, созданные для выявления общих лингвистических закономерностей на основе математических расчетов, оказывают значительное влияние на общее языкознание и его дочерние дисциплины. За последние десятилетия наука в области изучения языка на основе вероятностно-статистических методов еще раз помогла филологам со всего мира осознать все величие и великолепие языка в широком смысле.
Библиография
1. Большая советская энциклопедия [Электронный ресурс]. URL: http://dic.academic.ru/contents.ns/bse/(дата обращения: 03.06.2016)
2. Варфоломеев А.П. Психосемантика слова и лингвостатистика текста: Методические рекомендации к спецкурсу / Сост. А.П. Варфоломеев; Калинингр. ун-т. Калининград, 2000. 37 с.
3. Голуб И.Б. Литературное редактирование: учебное пособие / Новая университетская библиотека. М.: Логос, 2010. 432 с.
4. Гладкий А.В. О точных и математических методах в лингвистике и других гуманитарных науках – Текст // Вопросы языкознания. 2007. № 5. С. 22-36.
5. Звегинцев В.А. Очерки по общему языкознанию. М.: МГУ, 1962. 115 с.
6. Лингвистический энциклопедический словарь [Электронный ресурс]. URL: http://www.kodges.ru/nauka/inyaz/117972-lingvisticheskij-yenciklopedicheskij-slovar..html (Дата обращения: 07.06.2016)
7. Нелюбин Л.Л. Толковый переводческий словарь: учебное пособие / 3-е издание, переработанное. М.: ФЛИНТА, 2003. 320 с.
References
1. Bol'shaya sovetskaya entsiklopediya [Elektronnyi resurs]. URL: http://dic.academic.ru/contents.ns/bse/(data obrashcheniya: 03.06.2016)
2. Varfolomeev A.P. Psikhosemantika slova i lingvostatistika teksta: Metodicheskie rekomendatsii k spetskursu / Sost. A.P. Varfolomeev; Kaliningr. un-t. Kaliningrad, 2000. 37 s.
3. Golub I.B. Literaturnoe redaktirovanie: uchebnoe posobie / Novaya universitetskaya biblioteka. M.: Logos, 2010. 432 s.
4. Gladkii A.V. O tochnykh i matematicheskikh metodakh v lingvistike i drugikh gumanitarnykh naukakh – Tekst // Voprosy yazykoznaniya. 2007. № 5. S. 22-36.
5. Zvegintsev V.A. Ocherki po obshchemu yazykoznaniyu. M.: MGU, 1962. 115 s.
6. Lingvisticheskii entsiklopedicheskii slovar' [Elektronnyi resurs]. URL: http://www.kodges.ru/nauka/inyaz/117972-lingvisticheskij-yenciklopedicheskij-slovar..html (Data obrashcheniya: 07.06.2016)
7. Nelyubin L.L. Tolkovyi perevodcheskii slovar': uchebnoe posobie / 3-e izdanie, pererabotannoe. M.: FLINTA, 2003. 320 s.
|
 Рус
Рус









